
在 2015-2016 年間,出現了 ResNet 和 Attention 模型。從而我們知道,LSTM 不過是一項巧妙的「搭橋術」。並且注意力模型表明 MLP 網絡可以被「通過上下文向量對網絡影響求平均」替換。下文中會繼續討論這一點。
經過兩年多的時間,我們終於可以說:「放棄你的 RNN 和 LSTM 路線吧!」
我們能看到基於注意力的模型已越來越多地被用於谷歌、Facebook 和 Salesforce 的 AI 研究。它們都經歷了將 RNN 模型和其變體用基於注意力的模型替換的過程,而這纔剛剛開始。RNN 模型曾經是很多應用的構建基礎,但相比基於注意力的模型,它們需要更多的資源來訓練和運行。(參見:https://towardsdatascience.com/memory-attention-sequences-37456d271992)
讀者可查閱GitHub項目,理解RNN與CNN在序列建模上的概念與實現。
爲什麼?
RNN、LSTM 和其變體主要對時序數據進行序列處理。如下圖中的水平箭頭部分:
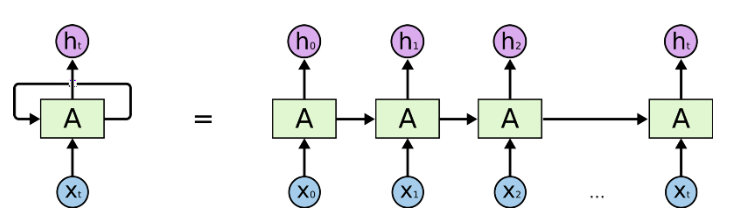
RNN 中的序列處理過程,來自《Understanding LSTM Networks》
這些箭頭表明,在長期信息訪問當前處理單元之前,需要按順序地通過所有之前的單元。這意味着它很容易遭遇梯度消失問題。
爲此,人們開發了 LSTM 模型,LSTM 可以視爲多個轉換門的合併。ResNet 也借鑑於這種結構,它可以繞過某些單元從而記憶更長時間步的信息。因此,LSTM 在某種程度上可以克服梯度消失問題。
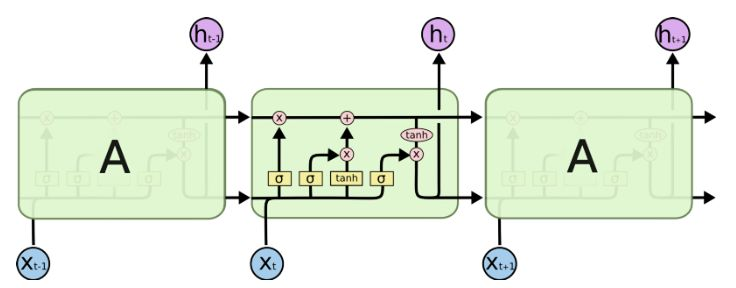
LSTM 中的序列處理過程,來自《Understanding LSTM Networks》
但這並不能完全解決該問題,如上圖所示。LSTM 中仍然存在按順序地從過去單元到當前單元的序列路徑。實際上,現在這些路徑甚至變得更加複雜,因爲路徑上還連接了加如記憶的分支和遺忘記憶的分支。毫無疑問,LSTM、GRU 和其變體能學習大量的長期信息(參見《The Unreasonable Effectiveness of Recurrent Neural Networks》),但它們最多隻能記住約 100s 的長期信息,而不是 1000s 或 10000s 等。
並且,RNN 的一大問題是它們非常消耗計算資源。即如果需要快速訓練 RNN,需要大量的硬件資源。在雲端上運行這些模型的成本也很高,隨着語音到文本的應用需求快速增長,雲計算資源目前甚至趕不上它的需求。
解決方案是什麼?
如果序列處理無可避免,那麼我們最好能找到可向前預測和向後回顧的計算單元,因爲我們處理的大多數實時因果數據只知道過去的狀態並期望影響未來的決策。這和在翻譯語句或分析錄製視頻時並不一樣,因爲我們會利用所有數據並在輸入上推理多次。這種向前預測和後向回顧的單元就是神經注意力模塊,下面將簡要介紹這一點。
爲了結合多個神經注意力模塊,我們可以使用下圖所示的層級神經注意力編碼器:
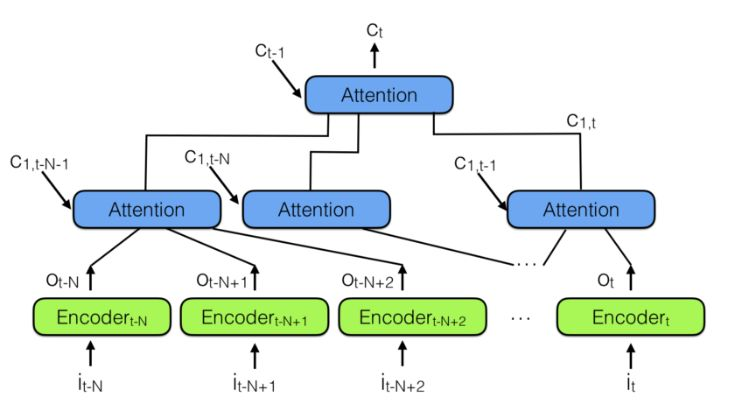
層級神經注意力編碼器
觀察過去信息的更好方式是使用注意力模塊將過去編碼向量彙總到上下文向量 C_t。請注意上面有一個層級注意力模塊,它和層級神經網絡非常相似。
在層級神經注意力編碼器中,多層注意力可查看過去信息的一小部分,例如 100 個向量,而上面層級的注意力模塊能查看到 100 個下層的注意力模塊,也就是 100×100 個向量。即利用層級模塊可極大地擴展注意力機制觀察的範圍。
這就是一種能回顧更多的歷史信息並預測未來的方法。
這種架構類似於神經圖靈機,但令神經網絡通過注意力決定從記憶中需要讀取什麼。這意味着一個實際的神經網絡將決定過去的哪個向量對未來的決策更重要。
但記憶的儲存呢?與神經圖靈機不同,上面的架構將會把所有的歷史表徵儲存在記憶中。這可能是不高效的,若儲存視頻中每一幀的表徵,而大多數情況下表徵向量並不會一幀幀地改變,所以這導致儲存了太多的相同信息。我們確實可以添加另一個單元來防止儲存相關數據,例如不儲存與之前太相似的向量。但這只是一種技巧,更好的方法可能是讓架構自己判斷哪些向量需要儲存,而哪些不需要。這一問題也是當前研究領域的重點,我們可以期待更多有意思的發現。
所以,最後總結來說:忘了 RNN 和它的變體吧,你僅需要的是注意力機制模塊。
目前我們發現很多公司仍然使用 RNN/LSTM 作爲自然語言處理和語音識別等架構,他們仍沒有意識到這些網絡是如此低效和不可擴展。例如在 RNN 的訓練中,它們因爲需要很大的內存帶寬而很難訓練,這對於硬件設計很不友好。本質上來說,遞歸是不可並行的,因此也限制了 GPU 等對並行計算的加速。
簡單來說,每個 LSTM 單元需要四個仿射變換,且每一個時間步都需要運行一次,這樣的仿射變換會要求非常多的內存帶寬,因此實際上我們不能用很多計算單元的原因,就是因爲系統沒有足夠的內存帶寬來傳輸計算。這對於模型的訓練,尤其是系統調參是非常大的限制,因此現在很多工業界應用都轉向了 CNN 或注意力機制。
論文:Attention Is All You Need
論文鏈接:https://arxiv.org/abs/1706.03762
在編碼器-解碼器配置中,顯性序列顯性轉導模型(dominant sequence transduction model)基於複雜的 RNN 或 CNN。表現最佳的模型也需通過注意力機制(attention mechanism)連接編碼器和解碼器。我們提出了一種新型的簡單網絡架構——Transformer,它完全基於注意力機制,徹底放棄了循環和卷積。兩項機器翻譯任務的實驗表明,這些模型的翻譯質量更優,同時更並行,所需訓練時間也大大減少。我們的模型在 WMT 2014 英語轉德語的翻譯任務中取得了 BLEU 得分 28.4 的成績,領先當前現有的最佳結果(包括集成模型)超過 2 個 BLEU 分值。在 WMT 2014 英語轉法語翻譯任務上,在 8 塊 GPU 上訓練了 3.5 天之後,我們的模型獲得了新的單模型頂級 BLEU 得分 41.0,只是目前文獻中最佳模型訓練成本的一小部分。我們表明 Transformer 在其他任務上也泛化很好,把它成功應用到了有大量訓練數據和有限訓練數據的英語組別分析上。
轉貼自: 幫趣

留下你的回應
以訪客張貼回應