
摘要: MIT和普朗克航空系統公司的研究人員合作,提出了一類「透明設計網絡」,在李飛飛等人提出的視覺理解資料庫CLEVR上達到了99.1%的準確率,他們設計的模塊使用注意力機制,縮小了現有視覺理解模型在性能和可解釋性之間的差距,相關論文已被CVPR 2018接收,你也可以用公布的代碼構建自己的視覺理解模型。
根據看到的圖像來回答問題,需要在圖像識別和分類的基礎上再進一步,形成對圖中物體彼此關係的推理和理解,是機器完成複雜任務所需的一項基本能力,也是視覺研究人員目前正在努力攻克的問題。
最近,在視覺推理任務中,模塊化的網絡展現出了很高的性能,但它們在可解釋性方面還多有欠缺。為了解決這個問題,MIT和普朗克航空系統公司的研究人員合作,圍繞視覺注意力機制,提出了一組視覺推理原語(primitives),組合起來後得到的模型,能夠以明確可解釋的方式,執行複雜的視覺推理任務,在視覺理解數據集CLEVR上達到了99.1%的準確率。
他們將這種設計模型的方法稱之為「透明設計」(Transparency-by-Design,TbD),使用這種方法設計出的網絡則稱為「透明設計網絡」(TbD-nets)。
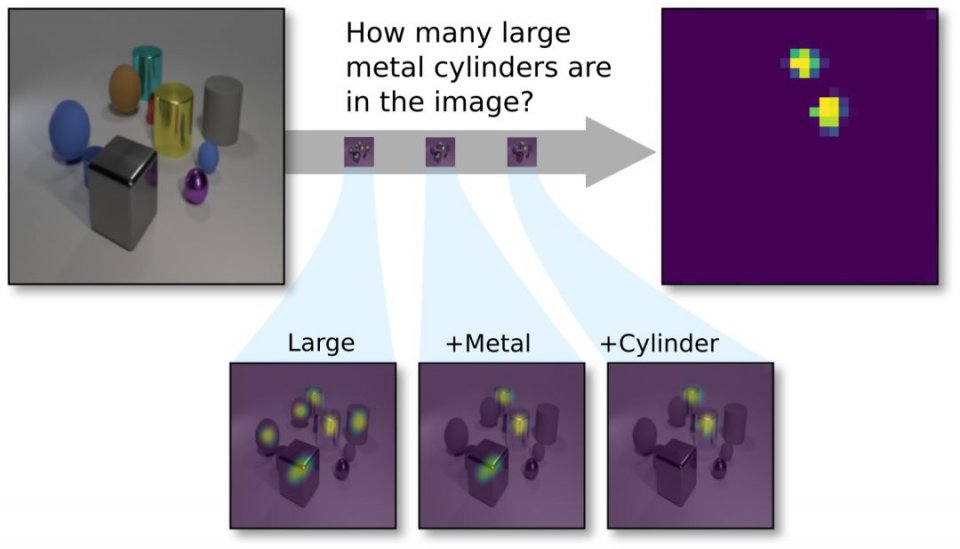
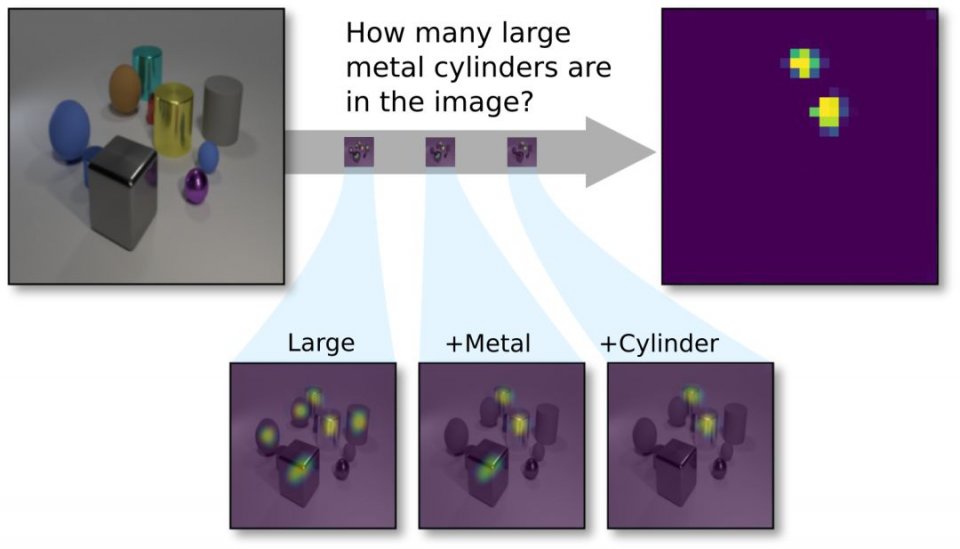
CLEVR視覺問答任務示意:新提出的透明設計網絡(TbD-net)組成了一系列的注意力掩碼(mask),使其能夠正確計數圖像中的兩個大型(Large)金屬(Metal)圓柱體(Cyliner)。
由上可見,模塊在輸出時,將結果高亮顯示,這樣人類也能夠檢查每個模塊的中間輸出,並且從一個高的層次理解模塊的行為,研究人員認為,這樣的模型就可以說是「透明」的。他們在論文中寫道,這些原語的輸出的保真度(fidelity)和可解釋性(interpretability),讓我們在診斷所得模型的優缺點方面,獲得了無與倫比的能力。由此,縮小了現有視覺理解模型在性能和可解釋性之間的差距。
他們還表明,當提供給模型的數據集很小,而且其中含有從未見過的新數據時,模型也能很好地學會泛化表示。在CoGenT泛化任務中,得到了比現有最好技術提高了20個百分點的成績。
相關論文《透明設計:縮小視覺推理中性能和可解釋性之間的差距》(Transparency by Design: Closing the Gap Between Performance and Interpretability in Visual Reasoning),已經被CVPR 2018接收。利用開原始碼,你也能構建視覺理解模型並在CLEVR數據集上測試,自己問問題,看看模型能否給出正確回答。
論文: https://arxiv.org/abs/1803.05268v1
代碼: https://github.com/davidmascharka/tbd-nets
CLEVR:10 萬圖像+100 萬問題,構建視覺理解基準
在介紹成果前,簡單介紹一下這項工作的基礎——CLEVR數據集。CLEVR是李飛飛領導的斯坦福人工智慧實驗室和Facebook AI Lab聯合提出的一個視覺問題基準,結合語義和推理,測試機器的語言視覺(Language Vision)在語義(Syntax)和推理(Inference)方面的能力。


CLEVR 包含 10 萬張經過渲染的圖像和大約 100 萬個自動生成的問題,其中有 85.3 萬個問題是互不相同的,包含了測試計數、比較、邏輯推理和在記憶中存儲信息等視覺推理能力的圖像和問題。
CoGenT是CLEVR的一個子任務,全稱是Compositional Generalization Test,檢驗模型在測試時識別新組合的屬性的能力。
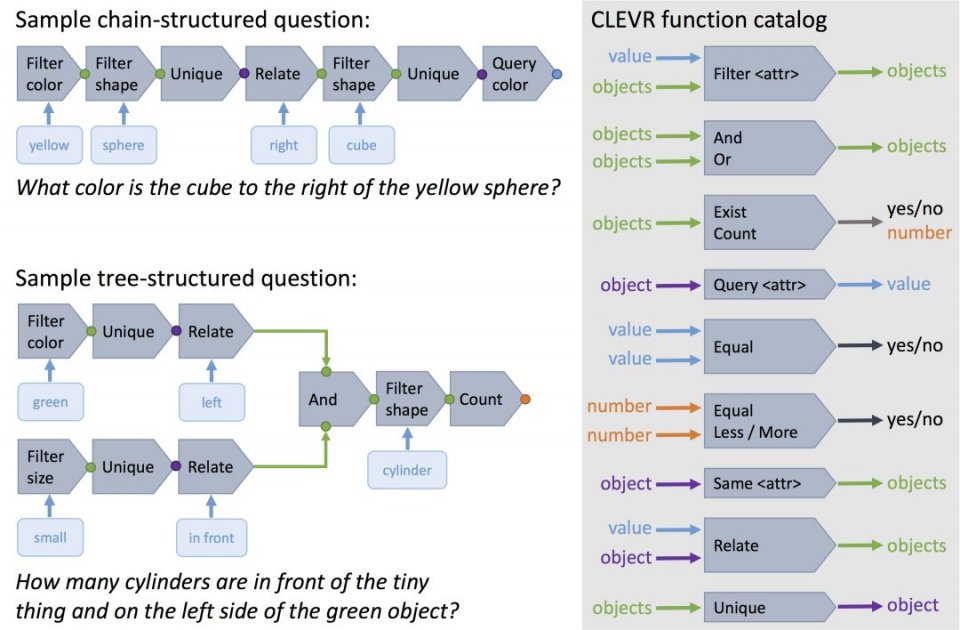
CLEVR中的每個問題都以自然語言和函數編程(functional program)的形式表示,函數編程表示讓人能精確確定模型回答每個問題所需的推理技能。
透明設計:圍繞注意力機制構建,可解釋的視覺推理原語
將一個複雜的推理鏈分解為一系列較小的子問題,其中每一個子問題都可以獨立解決,然後組合起來,這是一種強大而直觀的推理手段。像這樣的模塊化結構還允許在推理過程的每個步驟檢查網絡的輸出,取決於產生可解釋輸出的模塊設計。
受此啟發,我們提出一個神經模塊網絡(neural module network),該網絡在圖像空間中構建一個注意力機制模型,我們稱之為透明設計網絡( Transparency by Design network ,TbD-net),因為透明度(Transparency)是我們設計決策的驅動因素。
這個設計決策考慮到一些模塊只需要關注圖像中某個局部的特徵,例如注意力模塊(Attention module)只關注不同的對象或特徵一樣。其他模塊則需要在全局環境中執行操作,例如關聯模塊(Relate modules),它必須要將注意力轉移到整個圖像上。我們將每個模塊任務的先驗知識與經驗實驗相結合,從而為每個操作優化出一套新的模塊化架構。
在視覺問題回答任務中,推理鏈中的大多數步驟都需要對具有一些明顯可見屬性的對象(例如顏色,材質等)進行定位。我們確保每個執行此類型過濾的TbD模塊都輸出一維注意力掩模(attention mask),它可以明確地劃分相關的空間區域。因此, TbD-net不是在整個網絡中細化高維特徵映射,而是僅通過其模塊之間的attention mask。通過故意強化這種行為,我們產生了一個極好的具有可解釋性和直觀性的模型。這意味著我們離打開複雜的神經網絡的黑盒又近了一步。
圖3顯示了一個TbDnet如何在整個推理鏈中適當地轉移注意力,它解決了一個複雜的VQA問題,並且通過直接顯示它產生的attention mask,可以很容易地解釋這個過程。這裡顯示的所有attention masks都是使用視覺均勻的顏色圖生成的。
架構細節
以下描述每個模塊的架構。表1顯示了所有的模塊概覽。有幾個模塊共享輸入和輸出類型(例如Attention和Relate),但實現方式不同,這取決於它們的特定任務。
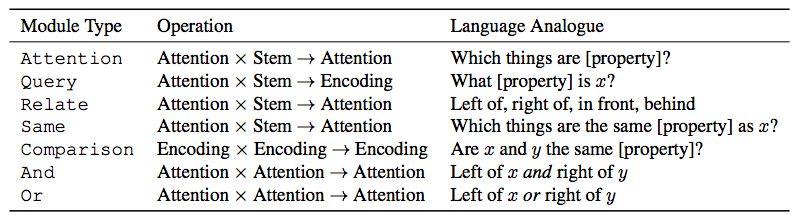
表1:Transparency by Design network中使用的模塊。Attention和Encoding分別指前一模塊的單維和高維輸出。Stem是指訓練的神經網絡產生的圖像特徵。變量x和y表示場景中不同的對象,例如[property]表示顏色,形狀,大小或材質。
我們使用從ResNet-101中提取的圖像特徵,並通過一個簡單的卷積模塊「stem」提供這些特徵。我們為大多數模塊提供了stem特徵,這確保了每個模塊都可以輕鬆訪問圖像特徵,並且在長的合成中不會丟失任何信息。stem可以將ResNet的高維特徵輸入轉換為適合我們任務的低維特徵。
具體的模塊描述如下:
-
Attention 模塊處理包含具有指定屬性的對象的圖像區域。
-
And和Or模塊分別在一組交集和並集中組合兩個attention masks。
-
Relate 模塊處理與另一個區域有一定空間關係的區域。
-
Same模塊處理一個區域,從該區域提取相關的屬性,並出現在共享該屬性的圖像中其他區域。
-
Query 模塊從圖像的參與區域提取特徵。
-
Compare 模塊比較兩個Query 模塊輸出的特徵,並生成一個特徵映射,用於對特徵是否相同進行編碼。
-
最後一個模塊是一個classifier,它將Query或Compare 模塊中的特徵映射作為輸入,並產生一個分布答案。
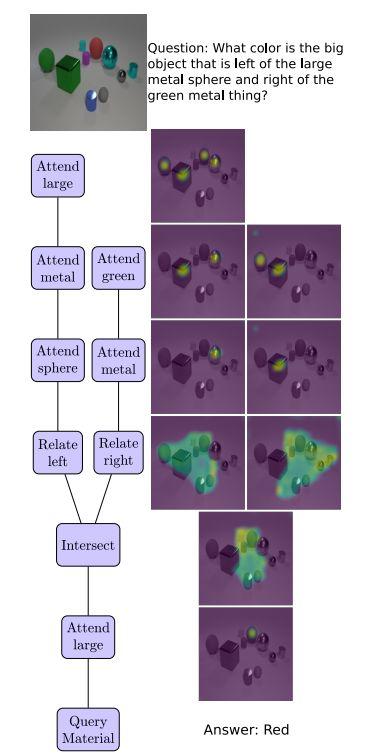
圖3. 從上到下看,透明設計網絡(TbD-net)組成視覺attention masks來回答關於場景中對象的問題。樹形圖(左側)表示TbD-net使用的模塊,右側顯示了相應的attention masks。
實驗:精度達到99.1%
我們使用CLEVR數據集和CLEVR-CoGenT來評估我們的模型。CLEVR是一個VQA數據集,包含70k圖像和700k問題的訓練集,以及15k圖像和150k問題的測試和驗證集。
CLEVR
我們的初始模型在CLEVR數據集上實現了98.7%的測試精度,遠遠超過其他基於神經網絡的方法。我們利用模型生成的attention masks來優化這個初始模型,進而實現99.1%的精確度。考慮到針對CLEVR已有許多高效的模型,我們對模型進行了5次訓練,以得到統計性能測量,結果平均驗證準確率為99.1%,標準差為0.07。此外,我們注意到其他模型沒有一個能夠以直觀的方式檢查它們的推理過程。而我們的模型在視覺推理過程的每個階段都提供了直接的、可解釋的輸出。

圖4. 輸入圖像(左)和Attention[large]模塊產生的attention mask覆蓋在輸入圖像上。如果不處罰attention mask輸出(中間),attention mask會產生噪音並在背景區域產生響應。懲罰attention輸出(右圖)提供了一個信號來減少外界的attention。
透明度
我們檢查了TbD模型的中間模塊產生的attention masks。結果顯示,我們的模型明確地構成了視覺attention masks以得出答案,從而導致神經網絡具有前所未有的透明度(transparency)。
圖3顯示了整個問題的視覺注意力組成。在本節中,我們提供透明度的定量分析。我們進一步檢查了幾個模塊的輸出,表明任何組成的每一步都可以直接解釋。

圖5. 輸入圖像(左)和被要求注意藍色柱狀塊後面區域以及大的青色橢球塊前面區域產生的attention masks,輸入特徵分別是14×14(中)和28×28(右)。
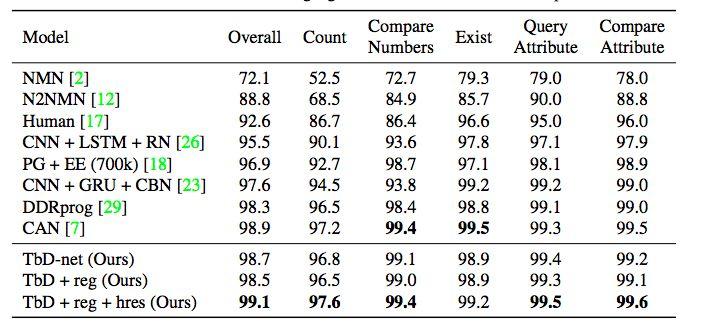
表2. CLEVR數據集上 state-of-the-art 模型的性能比較。我們的模型運行良好,同時保持模型透明度。我們在Query問題上實現了最先進的性能表現,同時保持了其他所有類別的競爭力。

圖6. 輸入圖像(左)和Attention[metal]模塊(右)產生的attention mask。當attention mask疊加在輸入圖像頂部(中圖)時,顯然注意力集中在金屬塊上。
CLEVR-CoGenT
CLEVR-CoGenT數據集為泛化提供了極好的測試。它與CLEVR數據集的形式完全相同,只是它有兩個不同的條件。在條件A中,所有立方體的顏色都是灰色,藍色,棕色或黃色,並且所有圓柱體都是紅色,綠色,紫色或青色中的一種; 在條件B中所有顏色交換。這可以檢查模型是否將形狀和顏色的概念關聯在一起。
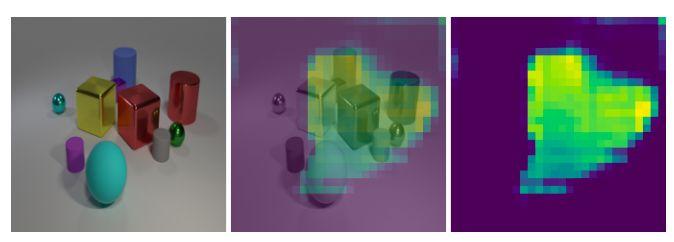
圖7. 一個輸入圖像(左)和Relate[right]模塊(右)在紫色圓柱體受到注意時產生的attention mask。當attention mask疊加在輸入圖像頂部(中圖)時,很明顯注意力集中在紫色圓柱右側的區域。
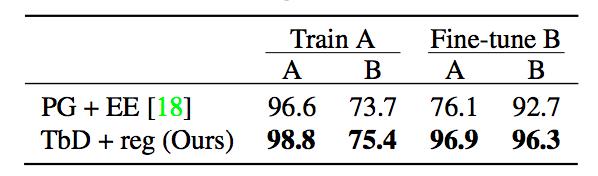
表3. 僅在條件A數據(中間列)上訓練,並且在微調具有新屬性的少量數據(右側列)之後的CoGenT數據集上,TbD-net與當前 state-of-the-art 模型的性能比較。
如表3所示,我們的模型在條件A上達到98.8%的準確性,但條件B上只有75.4%。然後我們使用3k圖像和條件B數據中的30k個問題對我們的模型進行微調。其他模型在微調後會看到條件A數據的性能顯著下降,而我們的模型保持高性能。如表3所示,我們的模型可以從少量的條件B數據中有效地學習。在微調後,我們在條件A上達到96.9%的準確度,在條件B上達到96.3%的準確度,遠高於 state-of-the-art模型報告的條件A 76.1%和條件B 92.7%的準確度。
強大的診斷工具,有助於信任視覺推理系統
我們提出Transparency by Design網絡,它構成了利用明確的注意力機制來執行推理操作的可視化基元。與此前的模型不同,由此產生的神經組件網絡既具有高性能又易於解釋。這是利用TbD模型的關鍵優勢——通過生成的attention masks 直接評估模型的學習過程,這是一個強大的診斷工具。
人們可以利用這種能力來檢查視覺操作的語義,例如「相同的顏色」,並重新設計模塊以解決推理中明顯的偏差。利用這些attention作為提高性能的手段,我們在具有挑戰性的CLEVR數據集和CoGenT generalization任務上實現了最高的準確度。對神經網絡操作的這種洞察也有助於用戶建立對視覺推理系統的信任。
轉貼自: 壹讀

留下你的回應
以訪客張貼回應