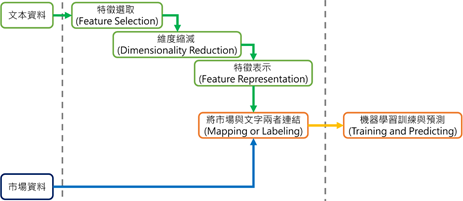
文字探勘(Text Mining)是一種透過資訊技術來分析文本中意見、情緒及感受的技術。 在訊息爆炸,且網路成為重要的訊息傳播管道下,由於文字探勘能大量且迅速的瞭解文字訊息中的意涵,而具有相當的商業價值。現今文字探勘經常用在顧客剖面分析、專利分析、信息摘要和企業報告分析上 。Arman Khadjeh等人將以機器學習預測市場的文字探勘文獻歸納出三個步驟,資料擷取與輸入、前處理、以機器學習進行市場預測。下圖中虛線分隔的三個區塊分別代表三個執行階段。
以預測金融市場為例,Arman Khadjeh等人將以機器學習預測市場的文字探勘文獻彙整並歸納出進行流程 。文字探勘流程可以分成三個步驟,首先為資料擷取與輸入,接著為前處理,最後是以機器學習進行分類來進行市場漲跌趨勢預測。
Paul C. Tetlock (2004)、 陳俊達(2007) 、鍾任明(2007) 等皆試圖利用財經新聞中的文字資訊來預測市場漲跌趨勢。Johan Bollen1 (2011)、Karabulut(2013)則從近年來被廣泛使用的網路社群平台 (如,Twitter, Facebook, 微博等) 捕捉大眾的情緒狀態來預測市場。另外隨著資訊技術進步,透過機器學習來找到字詞間對應的向量空間,來瞭解及呈現字詞間的關係,這類技術被稱之為字詞向量(Word to Vector)。
第一步中的資料內容會隨著研究題目而有所不同,如Ben J. Marafino 等人便使用護士紀錄的病患資料來預測病患的死亡率,Lei Zhang 等人則利用網路上的產品意見來衡量顧客對產品的正負面感受。Paul C. Tetlock(2004)透過WSJ專欄(Wall Street Journal)的內容進行文字探勘,發現當媒體情緒特別高或低時,成交量也會隨之放大。相似的研究還有陳俊達(2007) 、鍾任明(2007) 等,皆使用財經新聞資訊來預測市場漲跌趨勢。另一方面,亦有學者試圖從近年來被廣泛使用的網路社群平台 (如,Twitter, Facebook, 微博等) 捕捉大眾的情緒狀態來預測市場。Johan Bollen1 等人便以Twitter所建構的大眾情緒來預測DJIA (Dow Jones Industrial Average) 日漲跌趨勢。黃潤鵬 等人則以微博作為文本資料來源,並將情緒分為七種強度,來預測上證指數漲跌。Karabulut(2013)則利用Facebook上的國民幸福指數(Gross National Happiness, GNH)作為投資人情緒,結果顯示GNH能用來預測美國股市的報酬率和交易量,當GNH的增加時會使得隔日的市場報酬增加。顯然地,資料中是否具有研究議題所帶有的資訊是相當關鍵的。
在進行第二步將文字內容量化並取得文本特徵時,中文文字探勘往往順勢使用字典(Lexicon)來定義關鍵字詞並利用各個字詞地出現次數作為文本特徵。文獻上稱這類做法為詞袋方法(Word of Bag),實際應用的例子,有。另外由於中文文字屬於方塊字,不同於英文等拼音文字,在進行文字探勘時通常需要先經過斷詞處理,將語句分為數個字詞來表示語句的意涵。值得一提的是,雖然英文文字探勘不需要進行斷詞處理,但文獻指出考量字根與詞態變化後的文字探勘能明顯提高預測的命中率 。如何輸入攸關且精確地將「語意」量化是進行文字探勘的重要步驟。
以透過捕捉財經新聞或是網路論壇中的情緒,達到預測金融市場走勢的目標來說,其先決條件為資料必須要與未來走勢有所關聯。因此在黃潤鵬(2015)中將微博上的內容分為已發生的事實,及帶有未來展望的情緒內容兩者。希望藉此達到更好的預測效果 。 相反的,Tetlock(2010)則認為已發生的事實仍對市場有一定的影響,其實證發現股票報酬對過時的新聞報酬反應較弱,但股價報酬在事件當週仍然有負向的效果,且散戶投資人對過時的新聞報導反應較劇烈,此結果與散戶投資人對過時新聞過度反應,導致股價暫時推升理論一致。對於新聞中的事件、情緒等意涵,影響金融市場的機制仍需要更進一步的探索與研究。另一方面Dan diBartolomeo 指出新聞是一種資訊流入,代表新聞主體商業情境改變。當新聞大量湧入時意味著背後的商業情境在短時間內迅速變化,波動性便顯得大幅上升。
另外除了詞袋方法外,亦有文獻將機器學習應用在字詞與文本意涵的萃取上 ,在英文文字探勘文獻中往往獲得不錯的結果。其主要的概念是透過機器學習來找到字詞或文本間對應的向量空間,來瞭解及呈現字詞間的關係。這類技術被稱之為字詞向量(Word to Vector)。這類方法相對前者詞袋方法,最大的好處在於改善後者兩大問題,詞袋方法忽略了「字詞順序」的意涵,和「字詞語意(semantics of the words)」,因此這類方法在分類及情緒分析上常勝過詞袋方法。
Reference:
B. Pang and L. Lee, Opinion mining and sentiment analysis, Foundations and Trends in Information Retrieval, 2008
Ping-Tsun Chang, Text Mining with Machine Learning Techniques
Arman Khadjeh Nassirtoussi, Teh Ying Wah, Saeed Reza Aghabozorgi, David Ngo Chek Ling, Text Mining for Market Prediction: A Systematic Review, Expert Systems with Applications, 2014
Ben J. Marafino, W. John Boscardin, R. Adams Dudley, Efficient and sparse feature selection for biomedical text classification via the elastic net: Application to ICU risk stratification from nursing notes, Journal of Biomedical Informatics, 2015
Lei Zhang, Riddhiman Ghosh, Mohamed Dekhil, Meichun Hsu, Bing Liu, Combining Lexicon-based and Learning-based Methods for Twitter Sentiment Analysis, International Journal of Electronics, Communication and Soft Computing Science & Engineering, 2015
陳俊達 Jiun-Da Chen, 王台平 Tai-Ping Wang, 劉昭麟 Chao-Lin Liu, 以文件分類技術預測股價趨勢, 2007
鍾任明 李維平 吳澤民, 運用文字探勘於日內股價漲跌趨勢預測之研究, 中華管理評論, 2007
Johan Bollen, Huina Mao, Xiao-Jun Zeng, Twitter mood predicts the stock market, Journal of Computational Science, 2011
黃潤鵬、左文明、華淩燕, 基於微博情緒資訊的股票市場預測, 管理工程學報, 2015
鍾任明 李維平 吳澤民, 運用文字探勘於日內股價漲跌趨勢預測之研究, 中華管理評論, 2007
這類的看法認為主客觀文字內容帶有不同的資訊意涵。以Jonathan Ortigosa-Hern´andeza將文字探勘用於產品意見分析,並將研究分為三項1.主客觀屬性、2.情緒態度、3.影響意願,當中的主客觀屬性為將顧客意見分為主觀的表達感受和客觀的描述事實兩者,並配合顧客的正負面態度及是否有散播影響他人的意願強度,找出關鍵性評論並避免發生公關危機。
Dan diBartolomeo曾在Northfield Information Services Asian Research Seminar, November 2009指出新聞是一種資訊流入,代表新聞主體商業情境改變。
Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean, Efficient Estimation of Word Representations in Vector Space, 2013
Paragraph Vector: Le, Quoc, and Tomas Mikolov. "Distributed Representations of Sentences and Documents.“ ICML, 2014

留下你的回應
以訪客張貼回應