
Visualization




網絡分析介紹
摘要: 網絡分析是透過兩兩之間的個體關聯,所構造出的網絡型架構,利用其圖形結構的緊密程度、中心化程度、不同族群之間的連結關係......等,來觀察個體在網絡中的角色地位,或是整體網絡結構的隱含資訊。
網絡分析簡介
摘要: 網絡分析是透過兩兩之間的個體關聯,所構造出的網絡型架構,利用其圖形結構的緊密程度、中心化程度、不同族群之間的連結關係......等,來觀察個體在網絡中的角色地位,或是整體網絡結構的隱含資訊。
慶祝破百萬瀏覽量! 免費輕鬆註冊會員觀看股票情緒!
摘要: 破百萬瀏覽量慶祝! 免費輕鬆註冊會員觀看股票情緒 !
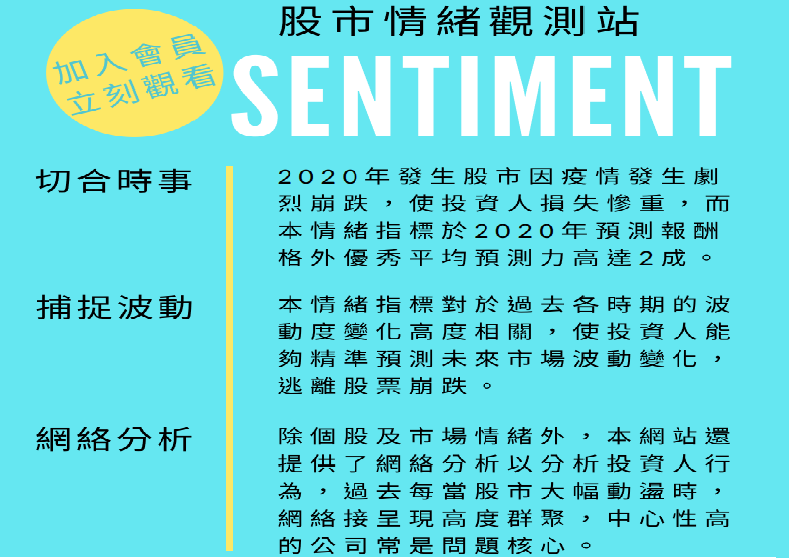
秒懂本站情緒指標使用說明
摘要: 本文介紹本站情緒指標使用說明
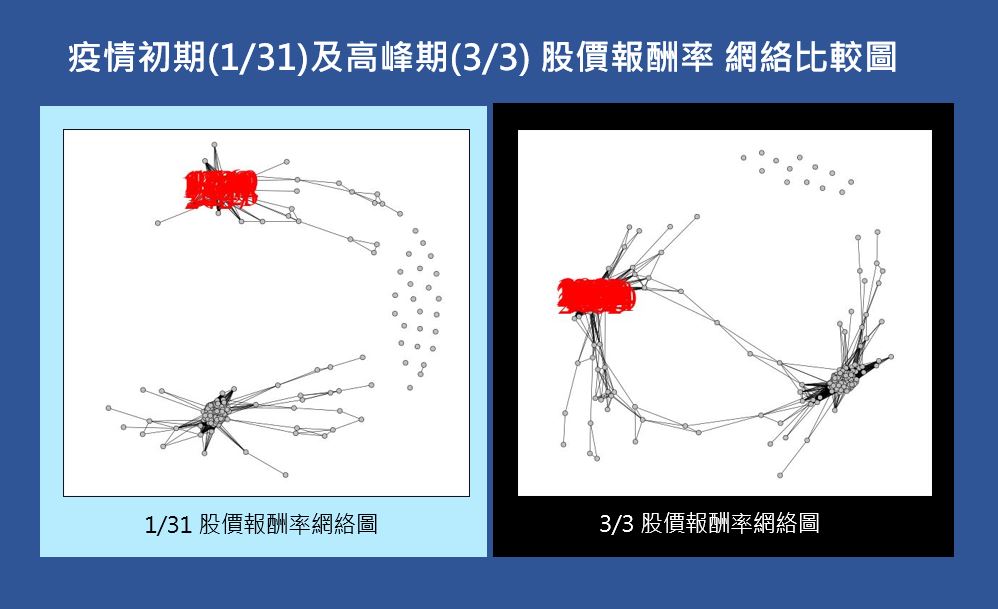
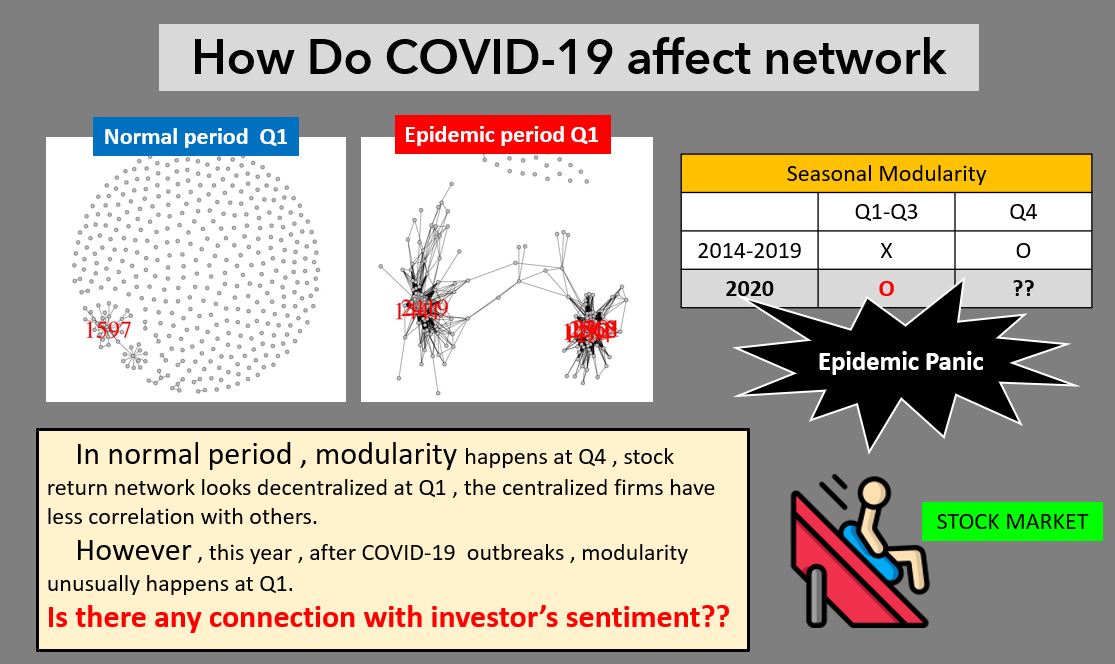
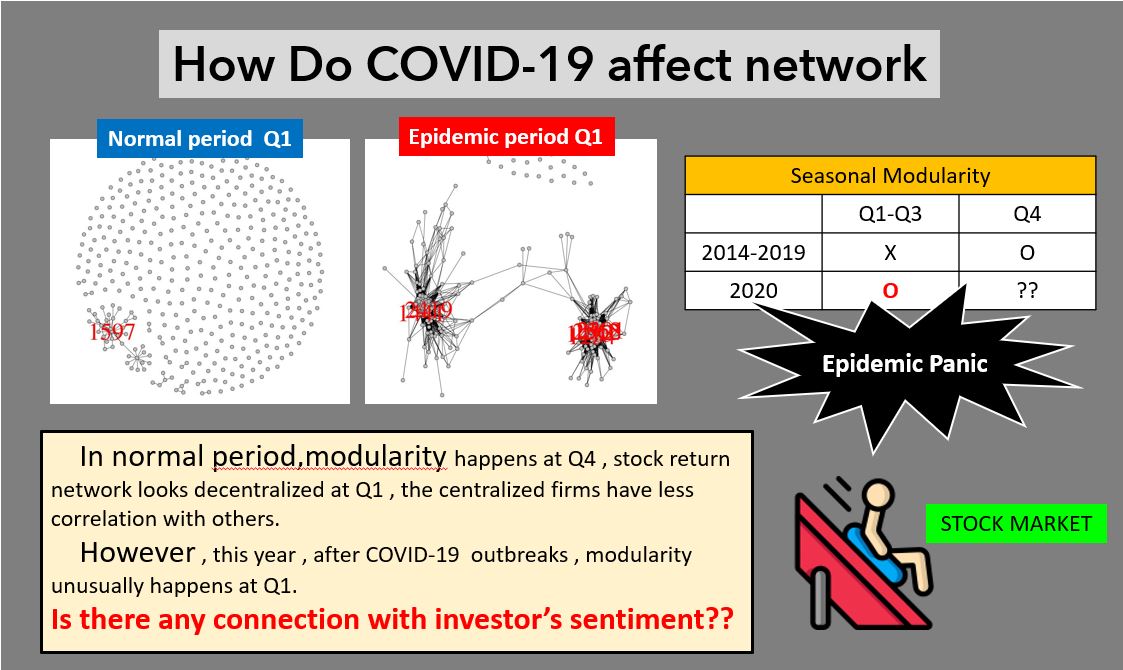
網絡分析介紹
摘要: 網絡分析是透過兩兩之間的個體關聯,所構造出的網絡型架構,利用其圖形結構的緊密程度、中心化程度、不同族群之間的連結關係......等,來觀察個體在網絡中的角色地位,或是整體網絡結構的隱含資訊。
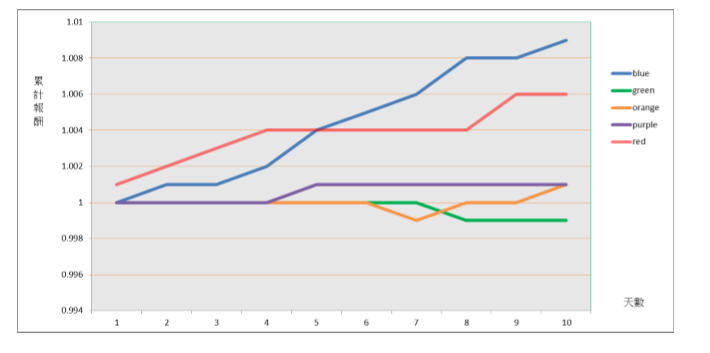
BigDataFinance情緒指標實證應用
摘要: 本篇文章示範本網站提供的情緒指標實證結果與如何應用於投資。
YOU MAY BE INTERESTED
