
摘要: 基於文本挖掘的量化投資應用。文本挖掘作為數據挖掘的一個分支,挖掘對象通常是非結構化的文本數據,常見的文本挖掘對象包括網頁中的論壇、微博、新聞等。文本挖掘是目前金融量化研究的一個非常熱門的領域,其主要原...
1. 金融文本挖掘背景介紹
文本挖掘作為數據挖掘的一個分支,挖掘對象通常是非結構化的文本數據,常見的文本挖掘對象包括網頁中的論壇、微博、新聞等。文本挖掘是目前金融量化研究的一個非常熱門的領域,其主要原因有以下三點:
關注對沖量化與金融工程行業的讀者,如果想加入“對沖量化與金融工程”專業討論群,請即回復後台“金融工程”,我們審核通過後將盡快將您安排加入到相應的微群討論組中。
一是對傳統數值型數據的研究已經相對成熟了,而對文本數據的研究處於起步狀態,在全新的數據源尋找超額收益相對容易。
二是網絡文本數據更直接的反應投資者的投資意向。比如說,投資者A在某論壇中發表言論提及某概念,那麼表示他近期特別關注該概念的投資機會;再比如說,當投資者B 想參與到某個主題投資中,那麼他應該會買入那些在日常新聞中閱讀到的和這些概念相關的股票。當我們以群體的方式去研究這些文本數據,便可以獲取額外的信息。
三是目前網絡所留存的文本數據在數量以及時間上都可以滿足我們去構建成熟的量化投資模型。量化投資模型的穩定性在很大程度上取決於樣本的數量,而隨著近年來互聯網技術的普及,網絡中留存的文本數據也呈幾何式增長,且普及時間也基本在5 年以上,因此這些數據滿足構建量化模型的基本要求。
在目前的文本數據研究領域,大家主要集中在對點數據的定性研究上,而對文本數據在時間序列上的定量分析較少。這主要有以下兩個方面原因:一是文本數據是以非結構化的形式存儲,且歷史數據規模較大,這是傳統統計分析難以處理的。二是文本數據獲取較難,需要長時間的積累,如果早期沒有進行積累的話,短期內很難獲取足夠長時間的數據進行時間序列分析。
2. 在眾人恐懼時貪婪,在眾人貪婪時恐懼
所有投資者似乎都認可這樣的常識:在眾人恐懼時貪婪,在眾人貪婪時恐懼。然而要驗證這個邏輯似乎是不容易的,最主要的原因就是對情緒的刻畫沒有一個標準模式,有人用市場波動率指標,也有人用換手率指標。然而通過文本挖掘,我們給出了一個更直觀的方法:如果說一個投資者在股票論壇上發的帖子反應了他對當前股市的情緒,那麼所有論壇的帖子反應了整個投資者群體對當前股市的情緒,基於這樣的想法,我們按天去收集股票論壇中所有的發貼,並對這些帖子進行情感分析、統計分析,得到一個可量化的、反映投資者群體情緒的指標。

前文中提到的“情感分析”,可以理解為一個黑盒,這個黑盒的輸入端為一段文字,輸出端為一個數值,這個數值反映了這句話的情感。若數值為正,則表示這段文字是樂觀的;若數值為負,則表示這段文字是悲觀的。在常規的情感分析算法中,監督學習仍然是主流,主要包括一些常規的分類算法,如貝葉斯,Kmean,SVM 等;另外還有一些基於規則的方法,當然考慮到金融詞彙的特殊性,還需要進行一些特別的處理。
由於中文詞語博大精深,我們的測試結果顯示:情感分析的正確率僅在85%左右,因此情感分析僅針對較大樣本下的統計才有意義。
運用該情緒指標,我們便可以構建貪婪恐懼的擇時模型。關於具體擇時模型構建的信息,請參考我們後續的報告。
3. 眼球經濟與主題投資
眼球經濟是指依靠吸引公眾注意力來獲取收益的一種經濟活動,在某種程度上,主題投資也是一樣的,它通過不停的吸引更多投資者的注意力來維持行情。如果能夠將主題投資吸引到的投資者註意力進行量化,我們在研究主題投資時便能獲取更豐富的額外信息。因此,我們定義了主題熱度指標,該指標反應了某個主題所受到的投資者關注量。具體的操作方法是:我們統計每日論壇中這些主題詞出現的頻率,然後計算其10日移動平均值,得到主題熱度指標。
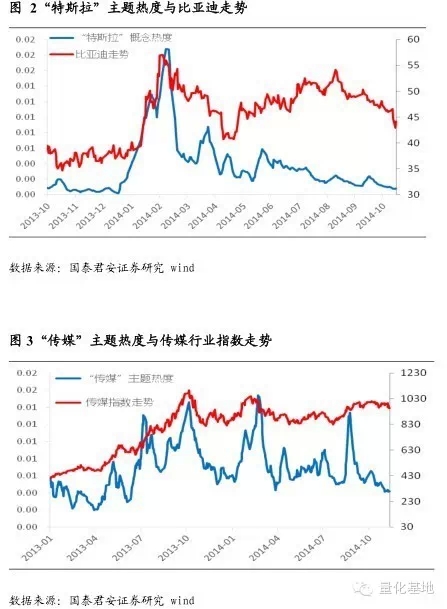
圖2 所示為“特斯拉”的主題熱度以及與其有較大相關性的比亞迪的走勢。從中我們可以看出主題熱度與主題相關股走勢呈正相關關係。這也驗證了主題投資的特點:主題可以通過不停的吸引更多投資者註意力來維持行情。圖3 中,傳媒主題熱度以及傳媒指數的走勢也高度相關。
然而經過我們的統計發現,幾乎所有的主題熱度與相關個股走勢均趨於同步性。僅僅依據主題熱度這樣一個同步指標,我們很難對主題做出擇時的判斷,因為在某種程度上基於主題熱度投資和基於股價本身投資是一樣的。對於主題熱度,我們更多的是從事件投資、突發新聞、主題炒作後相關股票超漲超跌的現象入手進行分析。具體分析大家可以參考我們後續的專題報告。
4. 在冷門股中尋找投資機會
格雷厄姆認為“冷門股中的投資機會更多"。他的理由是,這些冷門股由數量化專題報告於缺乏市場的關注,價格遠遠滯後於其統計表現,但是一旦該股票受到關注,結果可能完全相反,公司的業績將最大限度地反映到股票價格上。同時,《彼得〃林奇的成功投資》中也提到:“如果說有一種股票我避而不買的話,它一定是最熱門行業中最熱門的股票,這種股票受到大家最廣泛的關注,投資者上下班途中在汽車上或在火車上都會聽到人們談論這種股票,一般人往往禁不住這種強大的社會壓力就買入了這種股票。”
基於上述理論,我們來探索A 股中是否存在這樣的冷門股、熱門股效應。冷門股是指那些較少為人問津、很少被投資者關注並且公司名稱少有耳聞的股票。這些股票的一個重要特徵是它所對應的網絡論壇不活躍,因此網絡論壇的活躍度能夠直觀的反映股票的冷熱門程度。具體的操作方法是:我們統計每個股票所屬的子論壇下每日新發貼的數量,我們認為那些新發帖量較大的股票屬於相對熱門的股票,而那些新發帖量較小的股票屬於相對冷門的股票。我們僅按照發帖量的數據將所有股票劃分為5 組,組1 是所有股票中發帖量最低的20%,組5 為所有股票中發帖量最高的20%,組2,3,4 為依次遞增,然後我們按月進行調倉,每組內等權配置,得到5 組從2008 年6 月至今的各組累積收益率如下:
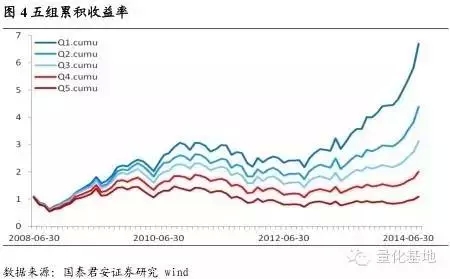
從圖4 中,我們看出基於論壇中的發帖量數據具有很好的區分度以及單調性;Q1,也就是發帖量最小的20%的股票組合,具有非常穩定的超額收益;Q5,也就發帖量最大的20%的股票組合,穩定的跑輸基準。這就是說明冷門股以及熱門股效應在A 股中也同樣是存在的。
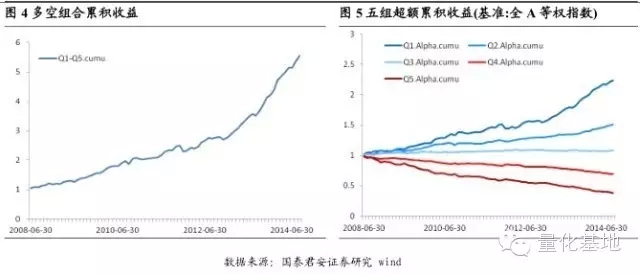
在中證800 指數、中證500 指數中,該因子也同樣有效。即使跟一些同性質的因子相比,它也有一定的優勢。比如分析師覆蓋家數因子,也能在一定程度上反映股票的冷熱程度,但是它的數據量較少,一方面會導致不是所有股票均有因子值,另一方面因子本身的小幅波動對結果影響較大。
我們推崇於這類因子的主要原因在於,首先這些數據基於一個全新的數據源,在一定程度上它所提供的超額收益是之前的方法所不能及的;其次這類因子的構造具有一定的複雜性,提高了研究門檻,因此其超額收益具有較強的持續性。關於該因子詳細的回測報告,請關注後期的專題報告。
5. 歲歲年年人不同
我們經常會面臨這樣的問題:當我們想去參與某個主題的投資時,應該去買什麼股票?一種困擾可能是這個主題太新了,根本不知道什麼股票屬於這一主題;另一種困擾可能是屬於這個主題的股票太多了, 而且各個相關股票也在不停的冷熱交替中,根本不清楚最近哪些股票和這些主題是最相關的。基於股票論壇中的大量文本數據,我們給出了解決方案。
一直以來我們都認可這樣的常識:當一個主題和一些股票同時出現在一個帖子或者一篇新聞中,那麼這些股票在大概率下是和這個主題相關的。於是我們在成千上萬的包含該主題的帖子或者新聞中去計算所有股票與該主題的文本上的相關關係,確定閥值,挑選出與該主題相關的個股。
在計算所有股票與主題的相關關係時,我們藉用了文本挖掘中常用的TF-IDF 算法。 TF-IDF 算法是一種統計方法,主要用於評估一個字詞對於一個語料庫中的一份文件的重要程度。字詞的重要性隨著它在該文件中出現的次數(TF)正比增加,但同時會隨著它在總的語料庫中出現的頻率(IDF)反比下降。具體而言,當我們想獲取環保最新的相關個股,分數量化專題報告以下步驟:1)獲取最近一段時間內所有含有環保詞組的文本;2)統計該文本中個股票出現次數,得到每個股票的TF 值;3)根據個股票在總文本中出現的次數計算IDF 值;4)計算每隻股票的TF-IDF 值,根據設定好的閥值,得到環保相關個股。這里之所以選用TF-IDF 算法,一方面因為它能夠量化股票僅和該主題間的相關性;另一方面通過IDF 權重的調整,可以篩去那些過熱的股票。
還有一個需要特別注意的細節:到底應該選用多久一段時間內的文本進行計算?我們的研究結果顯示,如果選取最近3 個月至6 個月的文本數據,則挑選出的相關個股基本偏向一些中規中矩、與主題確定相關的股票;如果選取較短時間內的文本數據,則挑選出的會是一些新近才與主題產生聯繫、相關性不確定的個股,且這些股票的波動性也非常大。
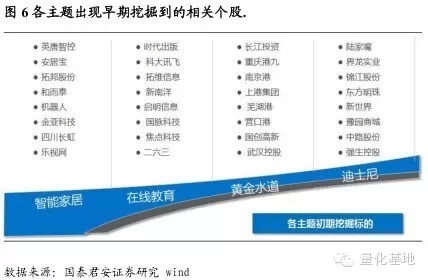
綜上所述,我們認為標的挖掘有以下幾個用途:1)新主題出現時,迅速地定位出和這些主題相關的個股;2)對舊主題,能夠量化主題和個股之間的相關性,在主題投資時對個股進行精選;3) 實時維護一個與主題相關性最大個股的組合。
6. 年年歲歲花相似
本節主要試圖闡明這樣一個道理:任何一樁能夠引起投資者關注的事件必然會帶來超額收益,這部分超額收益來源於投資者關注的溢價。如果這個事件的發生具有周期性,則我們可以基於其過去的表現來確定下次該事件來臨時的操作策略,從而獲取收益。這裡所指的事件定義非常廣泛,只要是能夠引起投資者關注的,並且是周期性發生的,均可以稱為事件。
以“中國國際機器人展覽會”為例,該展會是目前國內水平最高、規模最大、專業化程度最高的機器人專業展,目前已經舉辦了3 屆。 2012 年舉辦的時間為7 月3 日,2013 年舉辦時間為7 月2 日,2014 年舉辦時間為7 月9 日。首先我們仿照主題熱度的指標,在論壇的文本數據中去搜尋該博覽會被投資者所關注的熱度指標,如圖7。
從圖7 中可以看出,在該展覽會召開前,已經陸續有投資者在網絡論壇提到該展覽會,而且大量的提及時間點集中於召開前一個月。這說明該事件是能夠吸引大量投資者關注的,而且投資者的關注是在展覽會召開前一個月逐漸增多。接下來我們分析三屆會議召開前20 個交易日到召開後20 個交易日內,機器人主題指數相對於滬深300 的超額收益的累積情況如圖8 所示。

從圖8 中可以看出,每次在該展覽會前20 個交易日到展覽會召開當日均有一定的超額收益,在2013 年、2014 年的時候有近10%的超額收益,2012 年的時候有6%左右的超額收益,並且這些超額收益在展覽會召開後慢慢消減至0(2013 年因為其他的利好而導致了一定的偏差)。那麼基於這個數據,在2015 年7 月8 日該展覽會再次召開之前20 個交易日,我們可以考慮投資這樣一個事件。當然我們也可以根據上一節中介紹的主題相關個股標的挖掘法,來精選機器人主題的個股。
上述例子也闡述了立足於文本數據構造泛事件投資的基本框架,即:
-
確定該事件能否引起投資者關注以及確定具體的關注時段;
-
探索事件發生的歷史規律,如影響個股、收益變化等;
-
基於歷史規律,確認事件再次來臨時的操作策略。
資料來源:煉數成金

留下你的回應
以訪客張貼回應