
摘要: Artificial Intelligence may possibly be the single most misunderstood concept in contemporary data management. Most organizations are unclear about the relationship of AI to machine learning (they’re far from synonyms) and distinctions between supervised and unsupervised learning (which has nothing to do with monitoring results or human-in-the-loop).
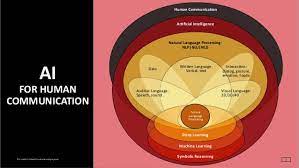
▲圖片標題(來源:slideshare)
they see little merit in combining statistical machine learning approaches with AI’s quintessential knowledge base, pairing onerous supervised learning approaches with true unsupervised ones, and implementing Neuro-Symbolic AI for their cognitive technology processes.
That is, until they realize how much time and money it saves them while mastering almost every aspect of natural language technologies—particularly question asking and answering.
“Neuro-Symbolic is a nod to word connectionist, neural network people, who then are also symbolic people,” Kyndi CEO Ryan Welsh explained. “It’s always been really interesting because in the field of AI, what I’ll call two of the main tribes are connectionist and the symbolic approach, and they’ve actually hated each other. But the path forward is them working together, and there’s really only a few people in the world that have the capacity to do that.”
Those who triumph in coupling the connectionist approach of machine learning techniques with the symbolic reasoning underscoring AI’s knowledge base make these technologies much more efficient, affordable, and efficacious for almost any application of processing natural language, especially the previously elusive domain of question answering.
The (Labeled) Training Data Dilemma
Machine learning typifies the statistical side of AI, which counterpoints that of its symbolic reasoning or knowledge base. The lack of domain specific labeled training data has consistently served as an enterprise barrier to organizations zealously embarking on machine learning initiatives under the guise of ‘doing AI’. When they can find enough example data for their use cases, they must undergo the arduous process of annotating that data for supervised learning techniques—which necessitate labeled training data. According to Welsh, with “another large vendor out of Seattle who has a cognitive search capability, on average it costs $250,000 just to pay someone to label the data. If you look at all the successful AI companies out there, they’re not actually AI companies. They’re data labeling companies.”
There are several issues with relying on pure supervised learning approaches for Natural Language Processing, search, question answering, and real-time language interactions with data systems, including:
‧ Effort: As Welsh alluded to, the high costs of labeling data pertain to the toils of fulfilling this task. “It’s kind of like turning a tanker where you have to label more data, retrain the system, hope it was right, if it wasn’t right label more data, re-train the system, hope it was right, and keep iterating on that process,” Welsh denoted.
‧ Time-to-Value:The time to meaningful findings and subsequent action based on rich datasets is considerably elongated with this method.
‧ Limited Understanding:Welsh observed that without augmentation “statistical approaches have very shallow understanding of language. The semantics just aren’t there.”
Unsupervised Learning
In addition to supplementing machine learning’s statistical reliance with symbolic reasoning, top Neuro-Symbolic AI mechanisms rely on unsupervised learning methods to avoid the costs, temporal delays, and other issues complicating supervised learning’s labeled training data requisites. By definition, unsupervised learning doesn’t involve labeled training data and uses techniques like clustering to identify categories or patterns in data. When employed with other semantic inference techniques like knowledge graphs, comprehensive data models or ontologies, and vocabularies—gleaned via parsing the data themselves—these unsupervised approaches work in conjunction with supervised learning to understand language for cognitive search.
Such a Neuro-Symbolic AI system is “unsupervised in its construction of the knowledge representation, but it does use supervised models to extract information to then build that representation,” Welsh mentioned. “There are some models that we’ve trained in how to do information or knowledge extraction from the data, but they’re very general models that allow us to machine learn in an unsupervised way to construct the knowledge representation.”
Examples of the knowledge Welsh referenced include business terms or concepts like ‘customer’ that are identified in a specific set of documents so users can ask questions about it. Best of all, with this approach they don’t have to recreate the labeled training data problem by building exhaustive taxonomies beforehand—which is “kind of like the data labeling problem but for semantic technologies, where you now need a human expert to go in and write down all of that knowledge representation; that can take forever and sometimes those systems are super brittle,” Welsh cautioned.
Symbolic Reasoning
Interweaving unsupervised and supervised learning techniques with symbolic reasoning allows organizations to represent the knowledge necessary to understand their text without building taxonomies beforehand or paying to label datasets. Implicit to this process is “taking the best of both worlds from the semantic technologies and the machine learning technologies and getting rid of the limitations of each,” Welsh noted. Symbolic reasoning, AI’s knowledge base, is directly responsible for understanding those knowledge representations, their meaning to queries, and how various terms or concepts relate to one another via graph technologies.
The vocabularies and definitions extracted from organizations’ texts are swiftly queried in knowledge graphs so that “from a question answering perspective and a Natural Language Understanding perspective you have a much richer semantic understanding of language compared to pure machine learning approaches,” Welsh revealed. Moreover, there’s no lengthy model training period on behalf of end users, while the contextualized understanding of knowledge this form of AI provides is ideal for discerning facts users didn’t explicitly state for information the system initially sees. “A manufacturing company out of Germany had built an internal machine learning system,” Welsh recalled. “It took them eight people years to build it and a bunch of labeled data, a bunch of data scientists working on it and [the Neuro-AI approach] out of the box had superior F1 results to their system.”
Keep in Mind
Despite its propensity for underpinning everything from computer vision to certain varieties of Natural Language Processing, machine learning is only one branch of AI. Its statistical capacity operates much better when coupled with AI’s knowledge base that involves semantic inferencing, knowledge graphs, descriptive ontologies, and more. Machine learning alone—particularly when only manifest as supervised learning—isn’t enough to handle sophisticated question answering and natural language technology applications at enterprise scale, speed, and affordability. Those who unduly rely on this approach are utilizing only half of AI’s potential to solve business problems with innovative methods.
Neuro-Symbolic AI enjoins statistical machine learning’s unsupervised and supervised learning techniques with symbolic reasoning methods to redouble AI’s enterprise worth. This total expression of AI realizes its full potential for cognitive search, textual applications, and natural language technologies. It’s the means of resolving the tension between the connectionist and symbolic approaches that have widely prevented them from working together in modern organizations’ IT systems.
“While knowledge systems have no capacity for learning, learning systems have no capacity for reasoning,” Welsh maintained. “It’s really interesting how AI has become almost synonymous with deep learning and specifically machine learning, when machine learning’s just an umbrella underneath AI and there’s a lot of other techniques that people aren’t using.”
轉貼自: Inside Big Data
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應