online gambling singapore
online gambling singapore
online slot malaysia
online slot malaysia
mega888 malaysia
slot gacor
live casino malaysia
online betting malaysia
mega888
mega888
mega888
mega888
mega888
mega888
mega888
mega888
mega888
Coding
詳細內容
Coding
建立: 07 十二月 2023
摘要: Google團隊指出,過去半年裡中國對台灣的網路攻擊大幅增加,光是中國境外就追蹤到上百個與中國政府有關連的駭客團體。
詳細內容
Coding
建立: 22 十一月 2022
摘要:
In recent years I’ve seen the evolution of the use of both of these languages in the world of Data Analytics. Here are my thoughts.
詳細內容
Coding
建立: 28 八月 2022
摘要: MIT alumni-founded WalkWise uses a motion-detecting device for walkers to allow family members and care professionals to monitor adults with mobility challenges.
詳細內容
Coding
建立: 02 八月 2022
摘要: Experimental successor to C++ strives for C++ performance and compatibility while avoiding its technical debt and ‘extreme difficulty’ to improve.
詳細內容
Coding
建立: 30 七月 2022
摘要: 随着大数据分析市场快速渗透到各行各业,哪些大数据技术是刚需?哪些技术有极大的潜在价值?根据弗雷斯特研究公司发布的指数,这里给出最热的十个大数据技术。
詳細內容
Coding
建立: 26 七月 2022
摘要: 情緒分析就是針對文本背後所詮釋的情緒進行分析。近來年機器學習和資料探勘正廣為學界和業界使用,而情緒分析則類似於資料探勘中的文字探勘,計算文本中各個字詞所代表的情緒分數,解讀進而轉化成資訊。
詳細內容
Coding
建立: 30 六月 2022
摘要: Following is the recipe. and the secret sauce is understanding the SQL internal sequence, which is so important not many people talk about this.
詳細內容
Coding
建立: 30 六月 2022
摘要: There are many Java-haters and many Java-lovers, but I have hardly seen anyone who doesn’t like Kotlin.
詳細內容
Coding
建立: 31 五月 2022
摘要: In this article, we help you to define which Python libraries work best if you are actively engaged with algorithmic trading with Python.
詳細內容
Coding
建立: 31 五月 2022
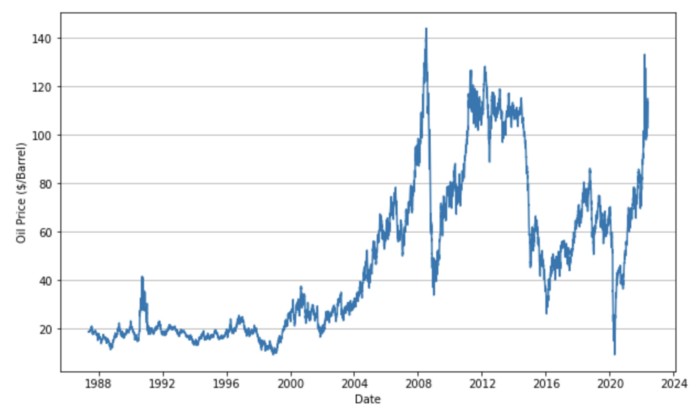
摘要: This article will explain the basics of how to analyze time series data using crude oil price data.
詳細內容
Coding
建立: 18 一月 2022
摘要:
Businesses today have lots of data, modern data warehousing, AI (Artificial Intelligence) tools, and nice visualization platforms. Still, users across small and large enterprises globally are frustrated by their inability to quickly get answers to their questions from their data.
詳細內容
Coding
建立: 27 十二月 2021
摘要: Even in a simple development environment, machines and algorithms are still powered by human intelligence.