
摘要: In this article, I’ll show you five ways to load data in Python. Achieving a speedup of 3 orders of magnitude.

▲Source: https://www.hippopx.com/, public domain
As a Python user, I use excel files to load/store data as business people like to share data in excel or csv format. Unfortunately, Python is especially slow with Excel files.
In this article, I’ll show you five ways to load data in Python. In the end, we’ll achieve a speedup of 3 orders of magnitude. It’ll be lightning-fast.
Experimental Setup
Let’s imagine that we want to load 10 Excel files with 20000 rows and 25 columns (that’s around 70MB in total). This is a representative case where you want to load transactional data from an ERP (SAP) to Python to perform some analysis.
Let’s populate this dummy data and import the required libraries (we’ll discuss pickle and joblib later in the article).
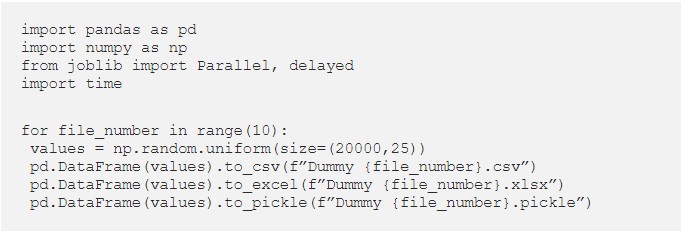
5 Ways to Load Data in Python
Idea #1: Load an Excel File in Python
Let’s start with a straightforward way to load these files. We’ll create a first Pandas Dataframe and then append each Excel file to it.

▲A simple way to import Excel files in Python.
It takes around 50 seconds to run. Pretty slow.
Idea #2: Use CSVs rather than Excel Files
Let’s now imagine that we saved these files as .csv (rather than .xlsx) from our ERP/System/SAP.

▲Importing csv files in Python is 100x faster than Excel files.
We can now load these files in 0.63 seconds. That’s nearly 10 times faster!
Python loads CSV files 100 times faster than Excel files. Use CSVs.
Con: csv files are nearly always bigger than .xlsx files. In this example .csv files are 9.5MB, whereas .xlsx are 6.4MB.
Idea #3: Smarter Pandas DataFrames Creation
We can speed up our process by changing the way we create our pandas DataFrames. Instead of appending each file to an existing DataFrame,
- We load each DataFrame independently in a list.
- Then concatenate the whole list in a single DataFrame.

▲A smarter way to import csv files in Python
We reduced the time by a few percent. Based on my experience, this trick will become useful when you deal with bigger Dataframes (df >> 100MB).
Idea #4: Parallelize CSV Imports with Joblib
We want to load 10 files in Python. Instead of loading each file one by one, why not loading them all, at once, in parallel?
We can do this easily using joblib.

▲Import CSV files in Python in Parallel using Joblib.
That’s nearly twice as fast as the single core version. However, as a general rule, do not expect to speed up your processes eightfold by using 8 cores (here, I got x2 speed up by using 8 cores on a Mac Air using the new M1 chip).
Simple Paralellization in Python with Joblib
Joblib is a simple Python library that allows you to run a function in //. In practice, joblib works as a list comprehension. Except each iteration is performed by a different thread. Here’s an example.
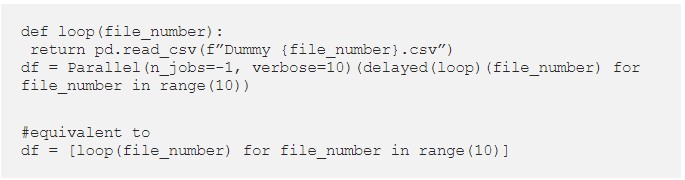
▲Think as joblib as a smart list comprehension.
Idea #5: Use Pickle Files
You can go (much) faster by storing data in pickle files — a specific format used by Python — rather than .csv files.
Con: you won’t be able to manually open a pickle file and see what’s in it.
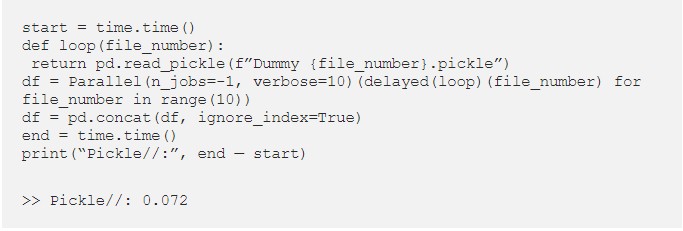
We just cut the running time by 80%!
In general, it is much faster to work with pickle files than csv files. But, on the other hand, pickles files usually take more space on your drive (not in this specific example).
In practice, you will not be able to extract data from a system directly in pickle files.
I would advise using pickles in the two following cases:
- You want to save data from one of your Python processes (and you don’t plan on opening it on Excel) to use it later/in another process. Save your Dataframes as pickles instead of .csv
-
You need to reload the same file(s) multiple times. The first time you open a file, save it as a pickle so that you will be able to load the pickle version directly next time.
Example: Imagine that you use transactional monthly data (each month you load a new month of data). You can save all historical data as .pickle and, each time you receive a new file, you can load it once as a .csv and then keep it as a .pickle for the next time.
Bonus: Loading Excel Files in Parallel
Let’s imagine that you received excel files and that you have no other choice but to load them as is. You can also use joblib to parallelize this. Compared to our pickle code from above, we only need to update the loop function.

▲How to load excel files using parallelization in Python.
We could reduce the loading time by 70% (from 50 seconds to 13 seconds).
You can also use this loop to create pickle files on the fly. So that, next time you load these files, you’ll be able to achieve lightning fast loading times.

Recap
By loading pickle files in parallel, we decreased the loading time from 50 seconds to less than a tenth of a second.
- Excel: 50 seconds
- CSV: 0.63 seconds
- Smarter CSV: 0.62 seconds
- CSV in //: 0.34 seconds
- Pickle in //: 0.07 seconds
- Excel in //: 13.5 seconds
詳見全文READ MORE: medium.com
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應