
摘要: 情緒分析就是針對文本背後所詮釋的情緒進行分析。近來年機器學習和資料探勘正廣為學界和業界使用,而情緒分析則類似於資料探勘中的文字探勘,計算文本中各個字詞所代表的情緒分數,解讀進而轉化成資訊。

▲圖片來源:knowslist
什麼是情緒分析(Sentiment Analysis)?
情緒分析就是針對文本背後所詮釋的情緒進行分析。近來年機器學習和資料探勘正廣為學界和業界使用,而情緒分析則類似於資料探勘中的文字探勘,計算文本中各個字詞所代表的情緒分數,解讀進而轉化成資訊。
近年來比較常見的作法是針對新聞內容分析,投資的世界其實是一場資訊戰,投資人透過會計資訊、技術線圖的指標…等資訊進行投資決策,而情緒分析就像是伴隨科技更為進步的一種分析方法,針對字詞傳達出樂觀(Optimistic)、悲觀(Pessimistic)的情緒來判斷標的價格變化。
Python套件-Jieba結巴斷詞
在文本分析中,斷詞是一個大議題,因為沒辦法正確的斷詞,就得不出正確的資訊,而中文斷詞在執行上有個相當窒礙難行的地方,在於中文的詞與詞之間並沒有明顯的分隔。
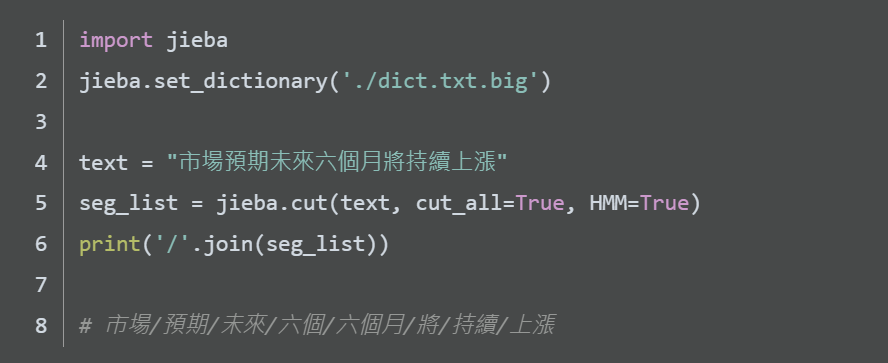
舉例來說,市場預期未來六個月將持續高通膨。這句話就是許多詞的組合,例如市場(名詞)、預期(動詞)、未來(名詞)...等等,但如果寫成英文呢
英文: Market expects high inflation rate will last six months.
詞與詞之間有明顯的空白分隔,因此可以輕易地區分出這句話中共有多少詞,但中文的區隔邏輯是不一的。
Jieba套件就是用於解決中文斷詞的問題,來看下面的例子。
jieba斷詞程式碼範例
導入了結巴斷詞套件後,設定要用來判斷字詞的辭典,進行斷詞。
▲圖片來源:knowslist
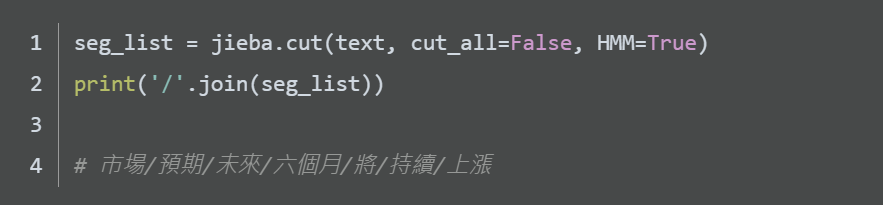
上方cut()函數中有個參數cut_all,當設定為True時是全模式,設定為False的時候是精確模式。
精確模式不會有同的字分到兩個詞的問題,全模式則是將所有可能都列出來。
▲圖片來源:knowslist
透過斷詞套件的輔助,解決了困難的斷詞作業,接著就能用文本中的詞句來計算情緒分數。
情緒分數計算
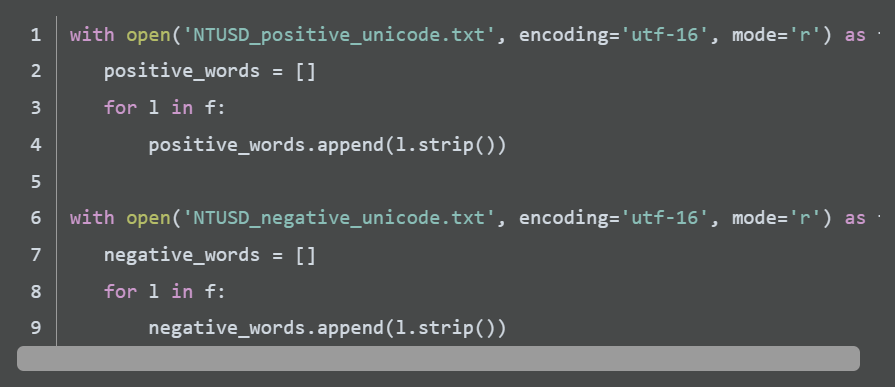
計算情緒分數的作業上,還缺一個很重要的元素,就是字詞所隱含的情緒方向和分數,在這使用台灣大學情緒字典(NTUSD),裏頭提供正面詞彙和負面詞彙的字典。
台大自然語言處理實驗室中還提供了英文字詞及對應的分數,裏頭有許多很棒的資源可以使用,提供參考。
接著隨機挑一篇財金新聞來做分析,原文連結在這:https://news.cnyes.com/news/id/4754811?exp=a

▲圖片來源:knowslist
接著讀取正負面詞彙的資料
▲圖片來源:knowslist
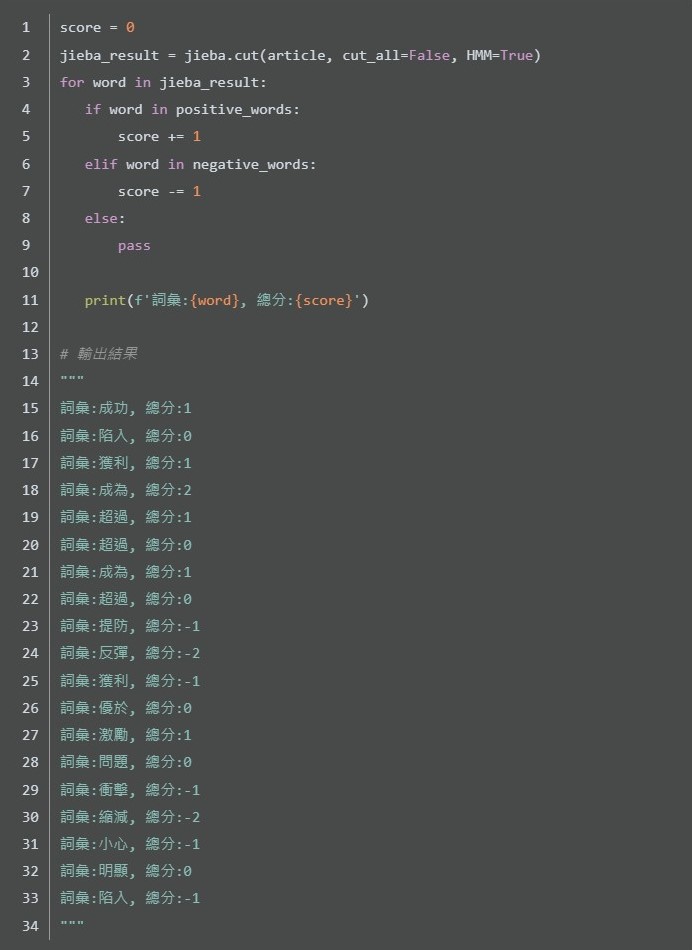
有了文本和字典後,就能透過剛剛介紹的jieba套件來完成。
▲圖片來源:knowslist
在上面的例子簡化了計算的方法,直接用正面字詞為1分,負面則為-1分的方式計算,實際上還有許多的計算方法,而不同的詞隱含的分數也可能多寡不一。
經過斷詞和情緒字詞判斷後,得出本篇新聞的情緒分數為-1,這篇新聞屬於盤勢解析的分類,而綜合許多盤勢解析的新聞之後,就能簡易的計算出當前市場投資人情緒分數。
轉貼自: knowslist
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應