
摘要: 在本教程中,我們將使用 PyTorch 實現基於 YOLO v3 的目標檢測器,後者是一種快速的目標檢測算法。本教程使用的代碼需要運行在 Python 3.5 和 PyTorch 0.3 版本之上。
以下鏈接中可以找到所有代碼:https://github.com/ayooshkathuria/YOLO_v3_tutorial_from_scratch
本教程包含五個部分:
1. YOLO 的工作原理
2. 創建 YOLO 網絡層級
3. 實現網絡的前向傳播
4. objectness 置信度閾值和非極大值抑制
5. 設計輸入和輸出管道
所需背景知識
在學習本教程之前,你需要了解:
-
卷積神經網絡的工作原理,包括殘差塊、跳過連接和上採樣;
-
目標檢測、邊界框迴歸、IoU 和非極大值抑制;
-
基礎的 PyTorch 使用。你需要能夠輕鬆地創建簡單的神經網絡。
什麼是 YOLO?
YOLO 是 You Only Look Once 的縮寫。它是一種使用深度卷積神經網絡學得的特徵來檢測對象的目標檢測器。在我們上手寫代碼之前,我們必須先了解 YOLO 的工作原理。
全卷積神經網絡
YOLO 僅使用卷積層,這就使其成爲全卷積神經網絡(FCN)。它擁有 75 個卷積層,還有跳過連接和上採樣層。它不使用任何形式的池化,使用步幅爲 2 的卷積層對特徵圖進行下采樣。這有助於防止通常由池化導致的低級特徵丟失。
作爲 FCN,YOLO 對於輸入圖像的大小並不敏感。然而,在實踐中,我們可能想要持續不變的輸入大小,因爲各種問題只有在我們實現算法時纔會浮現出來。
這其中的一個重要問題是:如果我們希望按批次處理圖像(批量圖像由 GPU 並行處理,這樣可以提升速度),我們就需要固定所有圖像的高度和寬度。這就需要將多個圖像整合進一個大的批次(將許多 PyTorch 張量合併成一個)。
YOLO 通過被步幅對圖像進行上採樣。例如,如果網絡的步幅是 32,則大小爲 416×416 的輸入圖像將產生 13×13 的輸出。通常,網絡層中的任意步幅都指層的輸入除以輸入。
解釋輸出
典型地(對於所有目標檢測器都是這種情況),卷積層所學習的特徵會被傳遞到分類器/迴歸器,從而進行預測(邊界框的座標、類別標籤等)。
在 YOLO 中,預測是通過卷積層完成的(它是一個全卷積神經網絡,請記住!)其核心尺寸爲:
1×1×(B×(5+C))
現在,首先要注意的是我們的輸出是一個特徵圖。由於我們使用了 1×1 的卷積,所以預測圖的大小恰好是之前特徵圖的大小。在 YOLO v3(及其更新的版本)上,預測圖就是每個可以預測固定數量邊界框的單元格。
雖然形容特徵圖中單元的正確術語應該是「神經元」,但本文中爲了更爲直觀,我們將其稱爲單元格(cell)。
深度方面,特徵圖中有 (B x (5 + C))* *個條目。B 代表每個單元可以預測的邊界框數量。根據 YOLO 的論文,這些 B 邊界框中的每一個都可能專門用於檢測某種對象。每個邊界框都有 5+C 個屬性,分別描述每個邊界框的中心座標、維度、objectness 分數和 C 類置信度。YOLO v3 在每個單元中預測 3 個邊界框。
如果對象的中心位於單元格的感受野內,你會希望特徵圖的每個單元格都可以通過其中一個邊界框預測對象。(感受野是輸入圖像對於單元格可見的區域。)
這與 YOLO 是如何訓練的有關,只有一個邊界框負責檢測任意給定對象。首先,我們必須確定這個邊界框屬於哪個單元格。
因此,我們需要切分輸入圖像,把它拆成維度等於最終特徵圖的網格。
讓我們思考下面一個例子,其中輸入圖像大小是 416×416,網絡的步幅是 32。如之前所述,特徵圖的維度會是 13×13。隨後,我們將輸入圖像分爲 13×13 個網格。
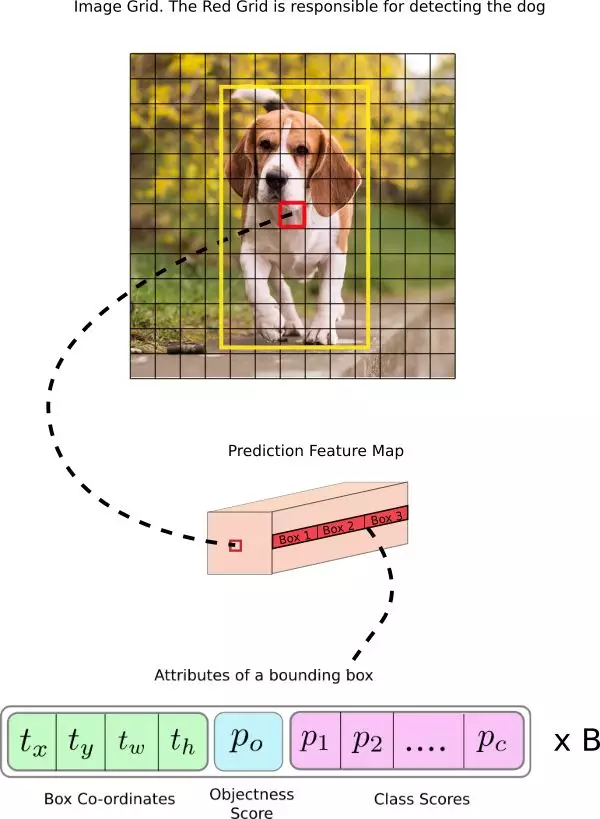
輸入圖像中包含了真值對象框中心的網格會作爲負責預測對象的單元格。在圖像中,它是被標記爲紅色的單元格,其中包含了真值框的中心(被標記爲黃色)。
現在,紅色單元格是網格中第七行的第七個。我們現在使特徵圖中第七行第七個單元格(特徵圖中的對應單元格)作爲檢測狗的單元。
現在,這個單元格可以預測三個邊界框。哪個將會分配給狗的真值標籤?爲了理解這一點,我們必須理解錨點的概念。
請注意,我們在這裏討論的單元格是預測特徵圖上的單元格,我們將輸入圖像分隔成網格,以確定預測特徵圖的哪個單元格負責預測對象。
錨點框(Anchor Box)
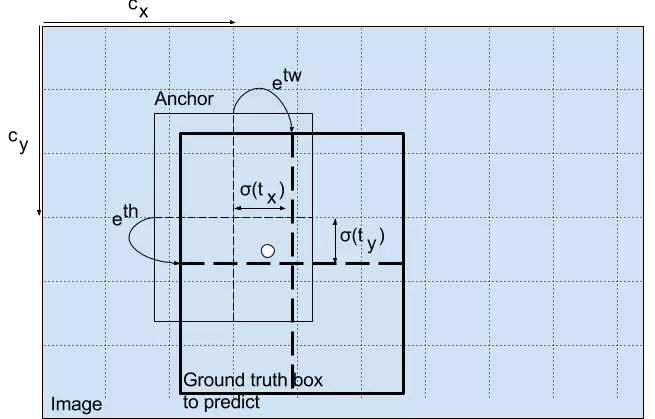
預測邊界框的寬度和高度看起來非常合理,但在實踐中,訓練會帶來不穩定的梯度。所以,現在大部分目標檢測器都是預測對數空間(log-space)變換,或者預測與預訓練默認邊界框(即錨點)之間的偏移。
然後,這些變換被應用到錨點框來獲得預測。YOLO v3 有三個錨點,所以每個單元格會預測 3 個邊界框。
回到前面的問題,負責檢測狗的邊界框的錨點有最高的 IoU,且有真值框。
預測
下面的公式描述了網絡輸出是如何轉換,以獲得邊界框預測結果的。
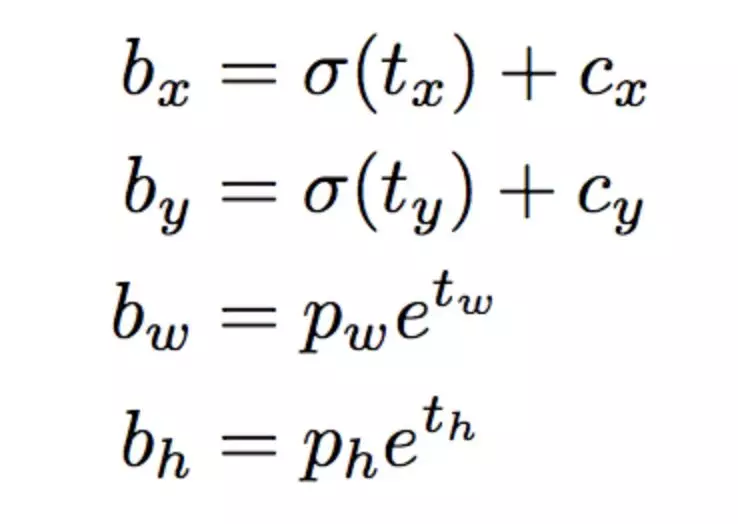
中心座標
注意:我們使用 sigmoid 函數進行中心座標預測。這使得輸出值在 0 和 1 之間。原因如下:
正常情況下,YOLO 不會預測邊界框中心的確切座標。它預測:
-
與預測目標的網格單元左上角相關的偏移;
-
使用特徵圖單元的維度(1)進行歸一化的偏移。
以我們的圖像爲例。如果中心的預測是 (0.4, 0.7),則中心在 13 x 13 特徵圖上的座標是 (6.4, 6.7)(紅色單元的左上角座標是 (6,6))。
但是,如果預測到的 x,y 座標大於 1,比如 (1.2, 0.7)。那麼中心座標是 (7.2, 6.7)。注意該中心在紅色單元右側的單元中,或第 7 行的第 8 個單元。這打破了 YOLO 背後的理論,因爲如果我們假設紅色框負責預測目標狗,那麼狗的中心必須在紅色單元中,不應該在它旁邊的網格單元中。
因此,爲了解決這個問題,我們對輸出執行 sigmoid 函數,將輸出壓縮到區間 0 到 1 之間,有效確保中心處於執行預測的網格單元中。
邊界框的維度
我們對輸出執行對數空間變換,然後乘錨點,來預測邊界框的維度。
檢測器輸出在最終預測之前的變換過程,圖源:http://christopher5106.github.io/
得出的預測 bw 和 bh 使用圖像的高和寬進行歸一化。即,如果包含目標(狗)的框的預測 bx 和 by 是 (0.3, 0.8),那麼 13 x 13 特徵圖的實際寬和高是 (13 x 0.3, 13 x 0.8)。
Objectness 分數
Object 分數表示目標在邊界框內的概率。紅色網格和相鄰網格的 Object 分數應該接近 1,而角落處的網格的 Object 分數可能接近 0。
objectness 分數的計算也使用 sigmoid 函數,因此它可以被理解爲概率。
類別置信度
類別置信度表示檢測到的對象屬於某個類別的概率(如狗、貓、香蕉、汽車等)。在 v3 之前,YOLO 需要對類別分數執行 softmax 函數操作。
但是,YOLO v3 捨棄了這種設計,作者選擇使用 sigmoid 函數。因爲對類別分數執行 softmax 操作的前提是類別是互斥的。簡言之,如果對象屬於一個類別,那麼必須確保其不屬於另一個類別。這在我們設置檢測器的 COCO 數據集上是正確的。但是,當出現類別「女性」(Women)和「人」(Person)時,該假設不可行。這就是作者選擇不使用 Softmax 激活函數的原因。
在不同尺度上的預測
YOLO v3 在 3 個不同尺度上進行預測。檢測層用於在三個不同大小的特徵圖上執行預測,特徵圖步幅分別是 32、16、8。這意味着,當輸入圖像大小是 416 x 416 時,我們在尺度 13 x 13、26 x 26 和 52 x 52 上執行檢測。
該網絡在第一個檢測層之前對輸入圖像執行下采樣,檢測層使用步幅爲 32 的層的特徵圖執行檢測。隨後在執行因子爲 2 的上採樣後,並與前一個層的特徵圖(特徵圖大小相同)拼接。另一個檢測在步幅爲 16 的層中執行。重複同樣的上採樣步驟,最後一個檢測在步幅爲 8 的層中執行。
在每個尺度上,每個單元使用 3 個錨點預測 3 個邊界框,錨點的總數爲 9(不同尺度的錨點不同)。

作者稱這幫助 YOLO v3 在檢測較小目標時取得更好的性能,而這正是 YOLO 之前版本經常被抱怨的地方。上採樣可以幫助該網絡學習細粒度特徵,幫助檢測較小目標。
輸出處理
對於大小爲 416 x 416 的圖像,YOLO 預測 ((52 x 52) + (26 x 26) + 13 x 13)) x 3 = 10647 個邊界框。但是,我們的示例中只有一個對象——一隻狗。那麼我們怎麼才能將檢測次數從 10647 減少到 1 呢?
目標置信度閾值:首先,我們根據它們的 objectness 分數過濾邊界框。通常,分數低於閾值的邊界框會被忽略。
非極大值抑制:非極大值抑制(NMS)可解決對同一個圖像的多次檢測的問題。例如,紅色網格單元的 3 個邊界框可以檢測一個框,或者臨近網格可檢測相同對象。

實現
YOLO 只能檢測出屬於訓練所用數據集中類別的對象。我們的檢測器將使用官方權重文件,這些權重通過在 COCO 數據集上訓練網絡而獲得,因此我們可以檢測 80 個對象類別。
該教程的第一部分到此結束。這部分詳細講解了 YOLO 算法。如果你想深度瞭解 YOLO 的工作原理、訓練過程和與其他檢測器的性能規避,可閱讀原始論文:
1. YOLO V1: You Only Look Once: Unified, Real-Time Object Detection (https://arxiv.org/pdf/1506.02640.pdf)
2. YOLO V2: YOLO9000: Better, Faster, Stronger (https://arxiv.org/pdf/1612.08242.pdf)
3. YOLO V3: An Incremental Improvement (https://pjreddie.com/media/files/papers/YOLOv3.pdf)
4. Convolutional Neural Networks (http://cs231n.github.io/convolutional-networks/)
5. Bounding Box Regression (Appendix C) (https://arxiv.org/pdf/1311.2524.pdf)
6. IoU (https://www.youtube.com/watch?v=DNEm4fJ-rto)
7. Non maximum suppresion (https://www.youtube.com/watch?v=A46HZGR5fMw)
8. PyTorch Official Tutorial (http://pytorch.org/tutorials/beginner/deep_learning_60min_blitz.html)
第二部分:創建 YOLO 網絡層級
以下是從頭實現 YOLO v3 檢測器的第二部分教程,我們將基於前面所述的基本概念使用 PyTorch 實現 YOLO 的層級,即創建整個模型的基本構建塊。
這一部分要求讀者已經基本瞭解 YOLO 的運行方式和原理,以及關於 PyTorch 的基本知識,例如如何通過 nn.Module、nn.Sequential 和 torch.nn.parameter 等類來構建自定義的神經網絡架構。
開始旅程
首先創建一個存放檢測器代碼的文件夾,然後再創建 Python 文件 darknet.py。Darknet 是構建 YOLO 底層架構的環境,這個文件將包含實現 YOLO 網絡的所有代碼。同樣我們還需要補充一個名爲 util.py 的文件,它會包含多種需要調用的函數。在將所有這些文件保存在檢測器文件夾下後,我們就能使用 git 追蹤它們的改變。
配置文件
官方代碼(authored in C)使用一個配置文件來構建網絡,即 cfg 文件一塊塊地描述了網絡架構。如果你使用過 caffe 後端,那麼它就相當於描述網絡的.protxt 文件。
我們將使用官方的 cfg 文件構建網絡,它是由 YOLO 的作者發佈的。我們可以在以下地址下載,並將其放在檢測器目錄下的 cfg 文件夾下。
配置文件下載:https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg
當然,如果你使用 Linux,那麼就可以先 cd 到檢測器網絡的目錄,然後運行以下命令行。
如果你打開配置文件,你將看到如下一些網絡架構:
我們看到上面有四塊配置,其中 3 個描述了卷積層,最後描述了 ResNet 中常用的捷徑層或跳過連接。下面是 YOLO 中使用的 5 種層級:
1. 卷積層
2. 跳過連接
跳過連接與殘差網絡中使用的結構相似,參數 from 爲-3 表示捷徑層的輸出會通過將之前層的和之前第三個層的輸出的特徵圖與模塊的輸入相加而得出。
3.上採樣
通過參數 stride 在前面層級中雙線性上採樣特徵圖。
4.路由層(Route)
路由層需要一些解釋,它的參數 layers 有一個或兩個值。當只有一個值時,它輸出這一層通過該值索引的特徵圖。在我們的實驗中設置爲了-4,所以層級將輸出路由層之前第四個層的特徵圖。
當層級有兩個值時,它將返回由這兩個值索引的拼接特徵圖。在我們的實驗中爲-1 和 61,因此該層級將輸出從前一層級(-1)到第 61 層的特徵圖,並將它們按深度拼接。
5.YOLO
YOLO 層級對應於上文所描述的檢測層級。參數 anchors 定義了 9 組錨點,但是它們只是由 mask 標籤使用的屬性所索引的錨點。這裏,mask 的值爲 0、1、2 表示了第一個、第二個和第三個使用的錨點。而掩碼錶示檢測層中的每一個單元預測三個框。總而言之,我們檢測層的規模爲 3,並裝配總共 9 個錨點。
Net
配置文件中存在另一種塊 net,不過我不認爲它是層,因爲它只描述網絡輸入和訓練參數的相關信息,並未用於 YOLO 的前向傳播。但是,它爲我們提供了網絡輸入大小等信息,可用於調整前向傳播中的錨點。
解析配置文件
在開始之前,我們先在 darknet.py 文件頂部添加必要的導入項。
我們定義一個函數 parse_cfg,該函數使用配置文件的路徑作爲輸入。
這裏的思路是解析 cfg,將每個塊存儲爲詞典。這些塊的屬性和值都以鍵值對的形式存儲在詞典中。解析過程中,我們將這些詞典(由代碼中的變量 block 表示)添加到列表 blocks 中。我們的函數將返回該 block。
我們首先將配置文件內容保存在字符串列表中。下面的代碼對該列表執行預處理:
然後,我們遍歷預處理後的列表,得到塊。
創建構建塊
現在我們將使用上面 parse_cfg 返回的列表來構建 PyTorch 模塊,作爲配置文件中的構建塊。
列表中有 5 種類型的層。PyTorch 爲 convolutional 和 upsample 提供預置層。我們將通過擴展 nn.Module 類爲其餘層寫自己的模塊。
create_modules 函數使用 parse_cfg 函數返回的 blocks 列表:
在迭代該列表之前,我們先定義變量 net_info,來存儲該網絡的信息。
nn.ModuleList
我們的函數將會返回一個 nn.ModuleList。這個類幾乎等同於一個包含 nn.Module 對象的普通列表。然而,當添加 nn.ModuleList 作爲 nn.Module 對象的一個成員時(即當我們添加模塊到我們的網絡時),所有 nn.ModuleList 內部的 nn.Module 對象(模塊)的 parameter 也被添加作爲 nn.Module 對象(即我們的網絡,添加 nn.ModuleList 作爲其成員)的 parameter。
當我們定義一個新的卷積層時,我們必須定義它的卷積核維度。雖然卷積核的高度和寬度由 cfg 文件提供,但卷積核的深度是由上一層的卷積核數量(或特徵圖深度)決定的。這意味着我們需要持續追蹤被應用卷積層的卷積核數量。我們使用變量 prev_filter 來做這件事。我們將其初始化爲 3,因爲圖像有對應 RGB 通道的 3 個通道。
路由層(route layer)從前面層得到特徵圖(可能是拼接的)。如果在路由層之後有一個卷積層,那麼卷積核將被應用到前面層的特徵圖上,精確來說是路由層得到的特徵圖。因此,我們不僅需要追蹤前一層的卷積核數量,還需要追蹤之前每個層。隨着不斷地迭代,我們將每個模塊的輸出卷積核數量添加到 output_filters 列表上。
現在,我們的思路是迭代模塊的列表,併爲每個模塊創建一個 PyTorch 模塊。
nn.Sequential 類被用於按順序地執行 nn.Module 對象的一個數字。如果你查看 cfg 文件,你會發現,一個模塊可能包含多於一個層。例如,一個 convolutional 類型的模塊有一個批量歸一化層、一個 leaky ReLU 激活層以及一個卷積層。我們使用 nn.Sequential 將這些層串聯起來,得到 add_module 函數。例如,以下展示了我們如何創建卷積層和上採樣層的例子:
路由層/捷徑層
接下來,我們來寫創建路由層(Route Layer)和捷徑層(Shortcut Layer)的代碼:
創建路由層的代碼需要做一些解釋。首先,我們提取關於層屬性的值,將其表示爲一個整數,並保存在一個列表中。
然後我們得到一個新的稱爲 EmptyLayer 的層,顧名思義,就是空的層。
其定義如下:
等等,一個空的層?
現在,一個空的層可能會令人困惑,因爲它沒有做任何事情。而 Route Layer 正如其它層將執行某種操作(獲取之前層的拼接)。在 PyTorch 中,當我們定義了一個新的層,我們在子類 nn.Module 中寫入層在 nn.Module 對象的 forward 函數的運算。
對於在 Route 模塊中設計一個層,我們必須建立一個 nn.Module 對象,其作爲 layers 的成員被初始化。然後,我們可以寫下代碼,將 forward 函數中的特徵圖拼接起來並向前饋送。最後,我們執行網絡的某個 forward 函數的這個層。
但拼接操作的代碼相當地短和簡單(在特徵圖上調用 torch.cat),像上述過程那樣設計一個層將導致不必要的抽象,增加樣板代碼。取而代之,我們可以將一個假的層置於之前提出的路由層的位置上,然後直接在代表 darknet 的 nn.Module 對象的 forward 函數中執行拼接運算。(如果感到困惑,我建議你讀一下 nn.Module 類在 PyTorch 中的使用)。
在路由層之後的卷積層會把它的卷積核應用到之前層的特徵圖(可能是拼接的)上。以下的代碼更新了 filters 變量以保存路由層輸出的卷積核數量。
捷徑層也使用空的層,因爲它還要執行一個非常簡單的操作(加)。沒必要更新 filters 變量,因爲它只是將前一層的特徵圖添加到後面的層上而已。
YOLO 層
最後,我們將編寫創建 YOLO 層的代碼:
我們定義一個新的層 DetectionLayer 保存用於檢測邊界框的錨點。
檢測層的定義如下:
在這個迴路結束時,我們做了一些統計(bookkeeping.)。
這總結了此迴路的主體。在 create_modules 函數後,我們獲得了包含 net_info 和 module_list 的元組。
測試代碼
你可以在 darknet.py 後通過輸入以下命令行測試代碼,運行文件。
你會看到一個長列表(確切來說包含 106 條),其中元素看起來如下所示:
第三部分:實現網絡的前向傳播
第二部分中,我們實現了 YOLO 架構中使用的層。這部分,我們計劃用 PyTorch 實現 YOLO 網絡架構,這樣我們就能生成給定圖像的輸出了。
我們的目標是設計網絡的前向傳播。
先決條件
-
閱讀本教程前兩部分;
-
PyTorch 基礎知識,包括如何使用 nn.Module、nn.Sequential 和 torch.nn.parameter 創建自定義架構;
-
在 PyTorch 中處理圖像。
定義網絡
如前所述,我們使用 nn.Module 在 PyTorch 中構建自定義架構。這裏,我們可以爲檢測器定義一個網絡。在 darknet.py 文件中,我們添加了以下類別:
這裏,我們對 nn.Module 類別進行子分類,並將我們的類別命名爲 Darknet。我們用 members、blocks、net_info 和 module_list 對網絡進行初始化。
實現該網絡的前向傳播
該網絡的前向傳播通過覆寫 nn.Module 類別的 forward 方法而實現。
forward 主要有兩個目的。一,計算輸出;二,儘早處理的方式轉換輸出檢測特徵圖(例如轉換之後,這些不同尺度的檢測圖就能夠串聯,不然會因爲不同維度不可能實現串聯)。
forward 函數有三個參數:self、輸入 x 和 CUDA(如果是 true,則使用 GPU 來加速前向傳播)。
這裏,我們迭代 self.block[1:] 而不是 self.blocks,因爲 self.blocks 的第一個元素是一個 net 塊,它不屬於前向傳播。
由於路由層和捷徑層需要之前層的輸出特徵圖,我們在字典 outputs 中緩存每個層的輸出特徵圖。關鍵在於層的索引,且值對應特徵圖。
正如 create_module 函數中的案例,我們現在迭代 module_list,它包含了網絡的模塊。需要注意的是這些模塊是以在配置文件中相同的順序添加的。這意味着,我們可以簡單地讓輸入通過每個模塊來得到輸出。
卷積層和上採樣層
如果該模塊是一個卷積層或上採樣層,那麼前向傳播應該按如下方式工作:
路由層/捷徑層
如果你查看路由層的代碼,我們必須說明兩個案例(正如第二部分中所描述的)。對於第一個案例,我們必須使用 torch.cat 函數將兩個特徵圖級聯起來,第二個參數設爲 1。這是因爲我們希望將特徵圖沿深度級聯起來。(在 PyTorch 中,卷積層的輸入和輸出的格式爲`B X C X H X W。深度對應通道維度)。
YOLO(檢測層)
YOLO 的輸出是一個卷積特徵圖,包含沿特徵圖深度的邊界框屬性。邊界框屬性由彼此堆疊的單元格預測得出。因此,如果你需要在 (5,6) 處訪問單元格的第二個邊框,那麼你需要通過 map[5,6, (5+C): 2*(5+C)] 將其編入索引。這種格式對於輸出處理過程(例如通過目標置信度進行閾值處理、添加對中心的網格偏移、應用錨點等)很不方便。
另一個問題是由於檢測是在三個尺度上進行的,預測圖的維度將是不同的。雖然三個特徵圖的維度不同,但對它們執行的輸出處理過程是相似的。如果能在單個張量而不是三個單獨張量上執行這些運算,就太好了。
爲了解決這些問題,我們引入了函數 predict_transform。
變換輸出
函數 predict_transform 在文件 util.py 中,我們在 Darknet 類別的 forward 中使用該函數時,將導入該函數。
在 util.py 頂部添加導入項:
predict_transform 使用 5 個參數:prediction(我們的輸出)、inp_dim(輸入圖像的維度)、anchors、num_classes、CUDA flag(可選)。
predict_transform 函數把檢測特徵圖轉換成二維張量,張量的每一行對應邊界框的屬性,如下所示:

上述變換所使用的代碼:
錨點的維度與 net 塊的 height 和 width 屬性一致。這些屬性描述了輸入圖像的維度,比檢測圖的規模大(二者之商即是步幅)。因此,我們必須使用檢測特徵圖的步幅分割錨點。
現在,我們需要根據第一部分討論的公式變換輸出。
對 (x,y) 座標和 objectness 分數執行 Sigmoid 函數操作。
將網格偏移添加到中心座標預測中:
將錨點應用到邊界框維度中:
將 sigmoid 激活函數應用到類別分數中:
最後,我們要將檢測圖的大小調整到與輸入圖像大小一致。邊界框屬性根據特徵圖的大小而定(如 13 x 13)。如果輸入圖像大小是 416 x 416,那麼我們將屬性乘 32,或乘 stride 變量。
loop 部分到這裏就大致結束了。
函數結束時會返回預測結果:
重新訪問的檢測層
我們已經變換了輸出張量,現在可以將三個不同尺度的檢測圖級聯成一個大的張量。注意這必須在變換之後進行,因爲你無法級聯不同空間維度的特徵圖。變換之後,我們的輸出張量把邊界框表格呈現爲行,級聯就比較可行了。
一個阻礙是我們無法初始化空的張量,再向其級聯一個(不同形態的)非空張量。因此,我們推遲收集器(容納檢測的張量)的初始化,直到獲得第一個檢測圖,再把這些檢測圖級聯起來。
注意 write = 0 在函數 forward 的 loop 之前。write flag 表示我們是否遇到第一個檢測。如果 write 是 0,則收集器尚未初始化。如果 write 是 1,則收集器已經初始化,我們只需要將檢測圖與收集器級聯起來即可。
現在,我們具備了 predict_transform 函數,我們可以寫代碼,處理 forward 函數中的檢測特徵圖。
在 darknet.py 文件的頂部,添加以下導入項:
然後在 forward 函數中定義:
現在,只需返回檢測結果。
測試前向傳播
下面的函數將創建一個僞造的輸入,我們可以將該輸入傳入我們的網絡。在寫該函數之前,我們可以使用以下命令行將這張圖像保存到工作目錄:
也可以直接下載圖像:https://github.com/ayooshkathuria/pytorch-yolo-v3/raw/master/dog-cycle-car.png
現在,在 darknet.py 文件的頂部定義以下函數:
我們需要鍵入以下代碼:
你將看到如下輸出:
張量的形狀爲 1×10647×85,第一個維度爲批量大小,這裏我們只使用了單張圖像。對於批量中的圖像,我們會有一個 100647×85 的表,它的每一行表示一個邊界框(4 個邊界框屬性、1 個 objectness 分數和 80 個類別分數)。
現在,我們的網絡有隨機權重,並且不會輸出正確的類別。我們需要爲網絡加載權重文件,因此可以利用官方權重文件。
下載預訓練權重
下載權重文件並放入檢測器目錄下,我們可以直接使用命令行下載:
也可以通過該地址下載:https://pjreddie.com/media/files/yolov3.weights
理解權重文件
官方的權重文件是一個二進制文件,它以序列方式儲存神經網絡權重。
我們必須小心地讀取權重,因爲權重只是以浮點形式儲存,沒有其它信息能告訴我們到底它們屬於哪一層。所以如果讀取錯誤,那麼很可能權重加載就全錯了,模型也完全不能用。因此,只閱讀浮點數,無法區別權重屬於哪一層。因此,我們必須瞭解權重是如何存儲的。
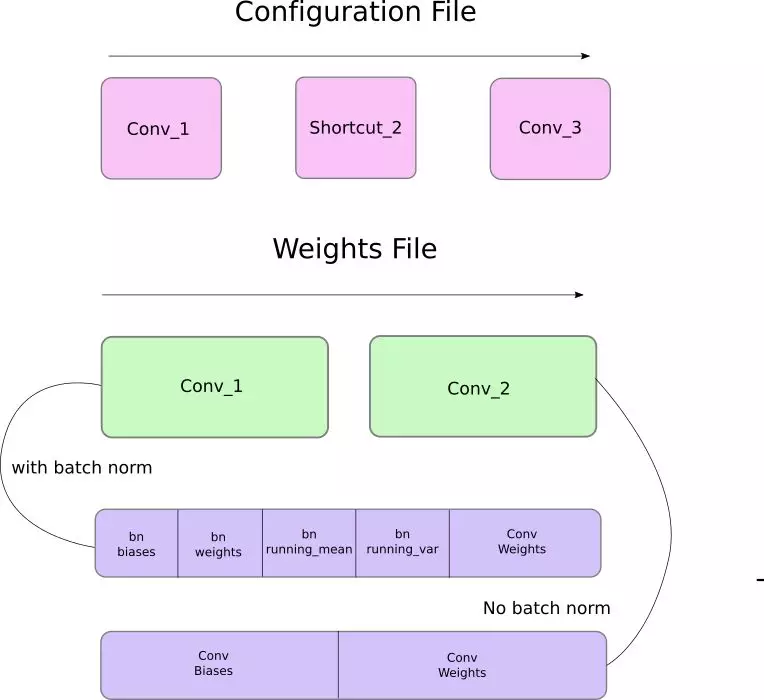
首先,權重只屬於兩種類型的層,即批歸一化層(batch norm layer)和卷積層。這些層的權重儲存順序和配置文件中定義層級的順序完全相同。所以,如果一個 convolutional 後面跟隨着 shortcut 塊,而 shortcut 連接了另一個 convolutional 塊,則你會期望文件包含了先前 convolutional 塊的權重,其後則是後者的權重。
當批歸一化層出現在卷積模塊中時,它是不帶有偏置項的。然而,當卷積模塊不存在批歸一化,則偏置項的「權重」就會從文件中讀取。下圖展示了權重是如何儲存的。
加載權重
我們寫一個函數來加載權重,它是 Darknet 類的成員函數。它使用 self 以外的一個參數作爲權重文件的路徑。
第一個 160 比特的權重文件保存了 5 個 int32 值,它們構成了文件的標頭。
之後的比特代表權重,按上述順序排列。權重被保存爲 float32 或 32 位浮點數。我們來加載 np.ndarray 中的剩餘權重。
現在,我們迭代地加載權重文件到網絡的模塊上。
在循環過程中,我們首先檢查 convolutional 模塊是否有 batch_normalize(True)。基於此,我們加載權重。
我們保持一個稱爲 ptr 的變量來追蹤我們在權重數組中的位置。現在,如果 batch_normalize 檢查結果是 True,則我們按以下方式加載權重:
如果 batch_normalize 的檢查結果不是 True,只需要加載卷積層的偏置項。
最後,我們加載卷積層的權重。
該函數的介紹到此爲止,你現在可以通過調用 darknet 對象上的 load_weights 函數來加載 Darknet 對象中的權重。
通過模型構建和權重加載,我們終於可以開始進行目標檢測了。未來,我們還將介紹如何利用 objectness 置信度閾值和非極大值抑制生成最終的檢測結果。
原文鏈接:https://medium.com/paperspace/tutorial-on-implementing-yolo-v3-from-scratch-in-pytorch-part-1-a0054d38ec78
轉貼自: 幫趣


留下你的回應
以訪客張貼回應