摘要: In addition to the myriad cybersecurity risks organizations already face, another vulnerability has emerged that affects most enterprises: the presence of sensitive data stored in unsecured files, i.e. unstructured data.
摘要: “The Snowflake Private Data Exchange represents the future of managing and sharing data broadly and securely inside enterprise and institutional boundaries,” Snowflake CEO, Frank Slootman said. “The data exchange model will become the deployment standard for exploring, discovering and sharing data enterprise-wide.”
摘要: Veeva OpenData Explorer is a new web-based portal to access approximately 16 million healthcare professionals (HCPs), healthcare organizations (HCOs), and their affiliations spanning 34 countries. The open API simplifies integration of Veeva OpenData with third-party applications and services so companies can leverage their customer data where they need it. With these latest innovations, Veeva is giving customers greater choice in how they use Veeva OpenData and making it even easier to access accurate customer data.”
摘要: Netflix has open sourced Metaflow, an internally developed tool for building and managing Python-based data science projects. Metaflow addresses the entire data science workflow, from prototype to model deployment, and provides built-in integrations to AWS cloud services.
摘要: In the banking or pharmacy industry where regulations compel companies to have good governance in place, in industries such as publishing and telecom Data Governance often seems complicated and theoretical. That’s according to Sara Willovit, Product Data Governance at Becton Dickenson.
摘要: Data can be anywhere. Companies store data in the cloud, in data warehouses, in data lakes, on old mainframes, in applications, on drives — even on paper spreadsheets. Every day we create 2.5 quintillion bytes of data, and there are no signs of this slowing down anytime soon.
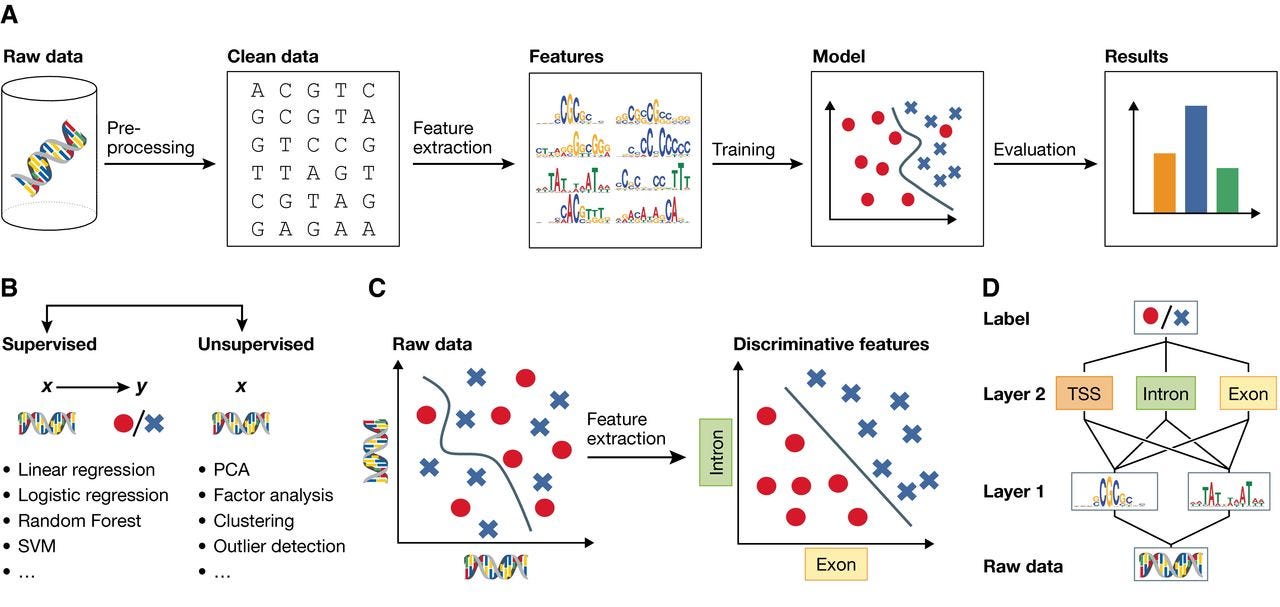
摘要: To build an effective learning model, it is must to understand the quality issues exist in data & how to detect and deal with it. In general, data quality issues are categories in four major sets.
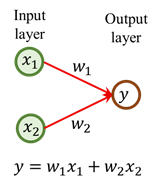
摘要: Below picture represents the machine learning & data mining process in general. Data cleaning and Feature extraction is the most tedious job but you need to be good at it make your model more accurate.
摘要: Bayesian Target Encoding is a feature engineering technique used to map categorical variables into numeric variables. The Bayesian framework requires only minimal updates as new data is acquired and is thus well-suited for online learning. Furthermore, the Bayesian approach makes choosing and interpreting hyperparameters intuitive. I developed this technique in the recent Avito Kaggle Competition, where my team and I took 14th place out of 1,917 teams. We found that the Bayesian target encoding outperforms the built-in categorical encoding provided by the LightGBM package.
摘要: It is important to actually work on different kinds of data and projects along with learning the data science concepts. Some datasets are very popular and a lot more are easily available on the web