
摘要: 去年NLP領域最火的莫過於BERT了,得益於數據規模和計算力的提升,BERT在大規模語料上預訓練(Masked Language Model + Next Sentence Prediction)之後可以很好地從訓練語料中捕獲豐富的語義信息,對各項任務瘋狂屠榜。我們在對BERT進行微調之後可以很好地適用到自己的任務上。如果想深入了解BERT的運行機制,就需要去仔細地研讀一下BERT的源碼。今天這篇文章我們來看看在BERT提出大半年之後,又有哪些基於BERT的有趣的研究。

ERNIE: Enhanced Representation through Knowledge Integration(Baidu/2019)
百度提出的ERNIE模型主要是針對BERT在中文NLP任務中表現不夠好提出的改進。我們知道,對於中文,bert使用的基於字的處理,在mask時掩蓋的也僅僅是一個單字,舉個例子:
我在上海交通大學玩泥巴-------> 我 在 上 【mask】 交 通 【mask】學 玩 【mask】 巴。
作者們認為通過這種方式學習到的模型能很簡單地推測出字搭配,但是並不會學習到短語或者實體的語義信息, 比如上述中的【上海交通大學】。於是文章提出一種知識集成的BERT模型,別稱ERNIE。 ERNIE模型在BERT的基礎上,加入了海量語料中的實體、短語等先驗語義知識,建模真實世界的語義關係。
在具體模型的構建上,也是使用的Transformer作為特徵抽取器。這裡如果對於特徵抽取不是很熟悉的同學,強烈推薦張俊林老師的"放棄幻想,全面擁抱Transformer:自然語言處理三大特徵抽取器(CNN/RNN/TF)比較"。
那麼怎麼樣才能使得模型學習到文本中蘊含的潛在知識呢?不是直接將知識向量直接丟進模型,而是在訓練時將短語、實體等先驗知識進行mask,強迫模型對其進行建模,學習它們的語義表示。
具體來說, ERNIE採用三種masking策略:
1. Basic-Level Masking: 跟bert一樣對單字進行mask,很難學習到高層次的語義信息
2. Phrase-Level Masking: 輸入仍然是單字級別的,mask連續短語
3. Entity-Level Masking: 首先進行實體識別,然後將識別出的實體進行mask。
經過上述mask訓練後,短語信息就會融入到word embedding中了
此外,為了更好地建模真實世界的語義關係,ERNIE預訓練的語料引入了多源數據知識,包括了中文維基百科,百度百科,百度新聞和百度貼吧(可用於對話訓練)。
ERNIE: Enhanced Language Representation with Informative Entities(THU/ACL2019)
本文的工作也是屬於對BERT錦上添花,將知識圖譜的一些結構化信息融入到BERT中,使其更好地對真實世界進行語義建模。也就是說,原始的bert模型只是機械化地去學習語言相關的“合理性”,而並學習不到語言之間的語義聯繫,打個比喻,就比如掉包xia只會掉包,而不懂每個包裡面具體是什麼含義。於是,作者們的工作就是如何將這些額外的知識告訴bert模型,而讓它更好地適用於NLP任務。
但是要將外部知識融入到模型中,又存在兩個問題:
1. Structured Knowledge Encoding: 對於給定的文本,如何高效地抽取並編碼對應的知識圖譜事實
2. Heterogeneous Information Fusion: 語言表徵的預訓練過程和知識表徵過程有很大的不同,它們會產生兩個獨立的向量空間。因此,如何設計一個特殊的預訓練目標,以融合詞彙、句法和知識信息又是另外一個難題。
為此,作者們提出了ERNIE模型,同時在大規模語料庫和知識圖譜上預訓練語言模型:
1. 抽取+編碼知識信息: 識別文本中的實體,並將這些實體與知識圖譜中已存在的實體進行實體對齊,具體做法是採用知識嵌入算法(如TransE),並將得到的entity embedding作為ERNIE模型的輸入。基於文本和知識圖譜的對齊,ERNIE 將知識模塊的實體表徵整合到語義模塊的隱藏層中。
2. 語言模型訓練: 在訓練語言模型時,除了採用bert的MLM和NSP,另外隨機mask掉了一些實體並要求模型從知識圖譜中找出正確的實體進行對齊(這一點跟baidu的entity-masking有點像)。
接下來看看模型到底長啥樣?
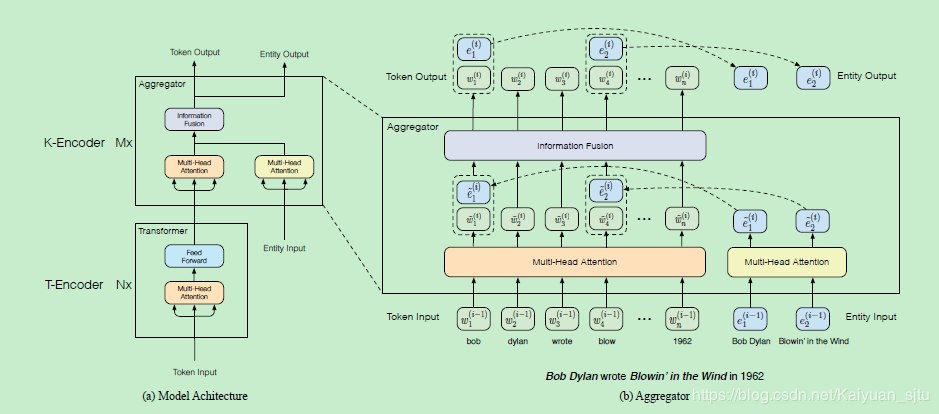
如上圖,整個模型主要由兩個子模塊組成:
1. 底層的textual encoder (T-Encoder),用於提取輸入的基礎詞法和句法信息,N個
2. 高層的knowledgeable encoder (K-Encoder), 用於將外部的知識圖譜的信息融入到模型中,M個。
knowledgeable encoder
knowledgeable encoder
這裡T-encooder跟bert一樣就不再贅述,主要是將文本輸入的三個embedding加和後送入雙向Transformer提取詞法和句法信息:
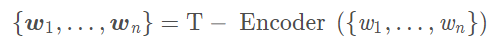
K-encoder中的模型稱為aggregator,輸入分為兩部分:
1. 一部分是底層T-encoder的輸出 :

2. 一部分是利用TransE算法得到的文本中entity embedding :

* 注意以上為第一層aggregator的輸入,後續第K層的輸入為第K-1層aggregator的輸出
接著利用multi-head self-attention對文本和實體分別處理:
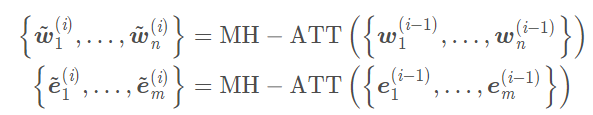
然後就是將實體信息和文本信息進行融合,實體對齊函數為
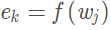
對於有對應實體的輸入:
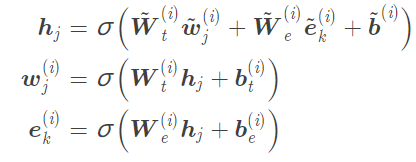
對於沒有對應實體的輸入詞:
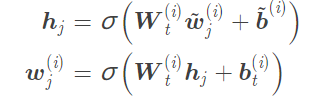
上述過程就是一個aggregator的操作,整個K-encoder會疊加M個這樣的block:
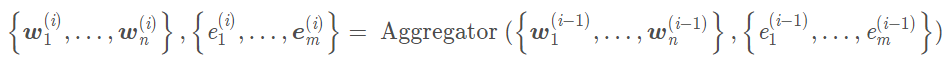
最終的輸出為最頂層的Aggregator的token embedding和entity embedding。
改進的預訓練
除了跟bert一樣的MLM和NSP預訓練任務,本文還提出了另外一種適用於信息融合的預訓練方式,denoising entity auto-encoder (dEA). 跟baidu的還是有點不一樣,這裡是有對齊後的entity sequence輸入的,而百度的是直接去學習entity embedding。 dEA 的目的就是要求模型能夠根據給定的實體序列和文本序列來預測對應的實體:
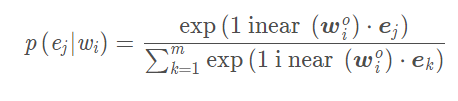
微調
為了使得模型可以更廣泛地適用於不同的NLP任務,作者也學習BERT設計了不同的特殊的token:
【CLS】:該token含有句子信息的表示,可適用於一般任務
【HD】和【TL】:該token表示關係分類任務中的頭實體和尾實體(類似於傳統關係分類模型中的位置向量),然後使用【CLS】來做分類;
【ENT】:該token表示實體類型,用於entity typing等任務。
原文鏈接: CDSN
版权声明:本文為CSDN博主 kaiyuan_sjtu 的原創文章,遵循 CC 4.0 by-sa 版權協議,,轉載請附上原文出處鏈接及本聲明。
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應