
摘要: 【循環神經網絡三十年發展梳理】
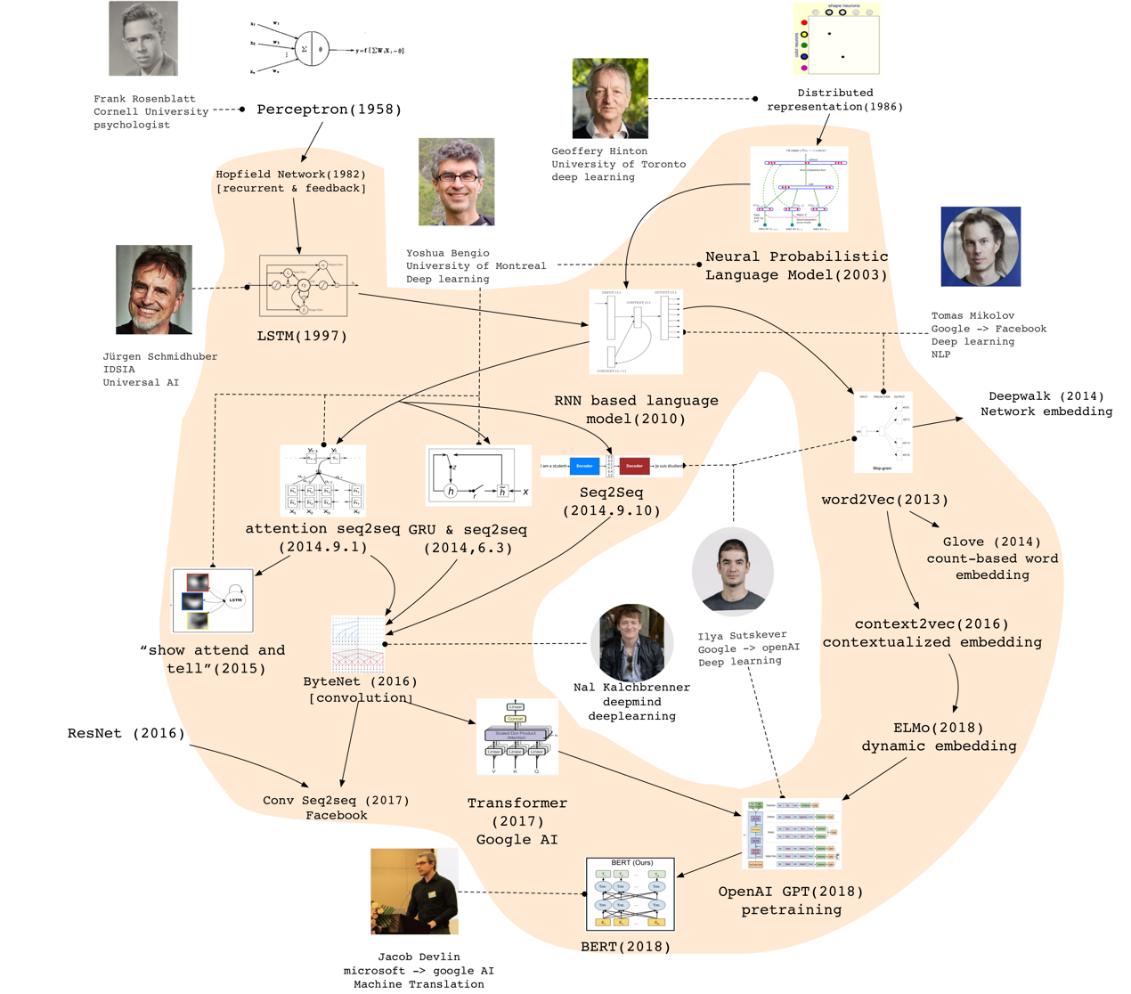
1982年,美國加州理工學院物理學家John Hopfield發明了一種單層反饋神經網絡Hopfield Network,用來解決組合優化問題。這是最早的RNN的雛形。
1986年,另一位機器學習的泰斗Michael I. Jordan定義了Recurrent的概念,提出Jordan Network。
1990年,美國認知科學家Jeffrey L. Elman對Jordan Network進行了簡化,並採用BP算法進行訓練,……
直到1997年,瑞士人工智能研究所的主任Jurgen Schmidhuber提出長短期記憶(LSTM),LSTM使用門控單元及記憶機制大大緩解了早期RNN訓練的問題。
同樣在1997年,Mike Schuster 提出雙向RNN模型(Bidirectional RNN)。
這兩種模型大大改進了早期RNN結構,拓寬了RNN的應用範圍,為後續序列建模的發展奠定了基礎。 ……
2010年,Tomas Mikolov對Bengio等人提出的feedforward Neural network language model (NNLM)進行了改進,提出了基於RNN的語言模型(RNN LM),並將其用在語音識別任務中,大幅提升了識別精度。在此基礎上Tomas Mikolov於2013年提出了大名鼎鼎的word2vec,與NNLM及RNNLM不同,word2vec的目標……
另一方面,2014年Bengio團隊與Google幾乎同時提出了seq2seq架構,將RNN用於機器翻譯。沒過多久,Bengio團隊又提出注意力Attention機制,對seq2seq架構進行改進。自此機器翻譯全面進入到神經機器翻譯(NMT)的時代,……
2017年,Facebook人工智能實驗室提出基於卷積神經網絡的seq2seq架構,將RNN替換為帶有門控單元的CNN,提升效果的同時大幅加快了模型訓練速度。
此後不久,Google提出Transformer架構,使用Self-Attention代替原有的RNN及CNN,更進一步降低了模型複雜度。 ……
不久之後,Google提出BERT模型,將GPT中的單向語言模型拓展為雙向語言模型(Masked Language Model),並在預訓練中引入了sentence prediction任務。 BERT模型在11個任務中取得了最好的效果,是深度學習在NLP領域又一個里程碑式的工作。
BERT自從在arXiv上發表以來獲得了研究界和工業界的極大關注,感覺像是打開了深度學習在NLP應用的潘多拉魔盒。隨後湧現了一大批類似於“BERT”的預訓練(pre-trained)模型,有引入BERT中雙向上下文信息的廣義自回歸模型XLNet,也有改進BERT訓練方式和目標的RoBERTa和SpanBERT,還有結合多任務以及知識蒸餾(Knowledge Distillation)強化BERT的MT-DNN等。這些種種,還被大家稱為 BERTology。
詳見全文: 今日頭條若喜歡本文,請關注我們的臉書 Please Like our Facebook Page:

留下你的回應
以訪客張貼回應