
摘要: 的Unicode字符集包含了上百萬個字符。最簡單的編碼是UTF-32,每個字符使用32位。這樣做最簡單,因為一直以來,計算機將32位視為數字,而計算機最在行的就是處理數字。但問題是,這樣太浪費空間了.UTF-8可以節省空間,...
...
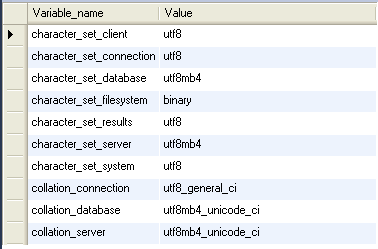
問題的癥結在於,MySQL的的“UTF8”實際上不是真正的UTF-8。
“UTF8”只支持每個字符最多三個字節,而真正的UTF-8是每個字符最多四個字節。
MySQL的一直沒有修復這個漏洞,他們在2010年發布了一個叫作“utf8mb4”的字符集,繞過了這個問題。
當然,他們並沒有對新的字符集廣而告之(可能是因為這個錯誤讓他們覺得很尷尬),以致於現在網絡上仍然在建議開發者使用“UTF8”,但這些建議都是錯誤的。
簡單概括如下: 1.MySQL的“utf8mb4”是真正的“UTF-8”。 2.MySQL的“UTF-8”是一種“專屬的編碼”,它能夠編碼的Unicode的字符並不多。 我要在這裡澄清一下:所有在使用“UTF-8”的MySQL的和MariaDB的用戶都應該改用“utf8mb4”,永遠都不要再使用“UTF-8”。
...
Full Text: 鍊數成金
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應