
▲圖片標題(來源:Shaan Ray)
One way to view technological advancement is through the lens of hardware: as new needs and use-cases emerge, chip manufacturers design special-purpose GPUs, FPGAs, and ASICs optimized for specific functions and software. All major industries in tech — from cloud computing, to computer graphics, to artificial intelligence, and machine learning — have evolved to demand hardware that accelerates the speed and efficiency with which computations can run. Often, the chips for an initial function (be it storing memory, rendering graphics, or running large-scale simulations) will start out quite simply before a generalizable pattern is identified and special-purpose hardware is developed. Ideally, this hardware becomes cheaper and more accessible to consumers over time.
A good historical example of this phenomenon is the evolution of the digital camera. In the 1960s, semiconductors were integrated into film cameras to automate simple functions like metering shutter speed or adjusting the size of an aperture depending on the quality of light a person was trying to capture — but the act of capturing an image in-memory was not yet possible. The first experiments with digital cameras in the 1970s evolved from the realization that you could take the concept of magnetic bubbles (a primitive form of storing single bits of data in-memory) and architect a charge coupled device (CCD) to absorb and store light in the form of electrons on silicon. Initial outlines of digital camera technology don’t even invoke the concept of megapixels, but camera resolution (not to mention speed and storage) was quite poor due to the limitations of semiconductors at the time: the first cameras had a resolution of around 0.0001 megapixels, and it took about 23 seconds for an image to pass from the buffer into memory. Tradeoffs between megapixel quantity and camera memory were tense until the 1990s when a newer sensor, the complementary metal oxide semiconductor (CMOS) became cheaper to manufacture and more mainstream (by comparison, modern iPhones use CMOS and offer camera quality of around 12 megapixels).
Over the course of several decades, digital cameras evolved from hacked-together contraptions engineered by researchers with access to expensive semiconductors, to devices that reached the tens of thousands of dollars, to being embedded in every mobile phone, available to anyone for a few hundred or thousand dollars.
Other fields follow a similar trajectory from general to application-specific hardware. A more recent example of hardware optimization within the crypto space specifically is in cryptocurrency mining: when bitcoin mining launched in 2009, it was common for anyone to run the SHA256 hashing algorithm on a standard multi-core CPU. Over time, as mining grew more competitive, block rewards dropped, and a general understanding of why people might want a global, censorship-resistant currency grew more mainstream, an entire industry around developing more efficient hardware for mining developed. First we transitioned to GPU mining which allowed scaling from single digit mining parallelism to five digit mining parallelism, which sped up the process. And today, an ASIC rig for mining Bitcoin can compute around 90-100 terahashes/second — about 5 billion times more powerful than a CPU chip.
In other words, you might view mining as just the beginning — a proof-of-concept that decentralized currencies are not only possible, but desirable. Even if we’re at an advanced stage of what ASICs for mining look like, we’re at the very beginning of what hardware for web3 will become. As blockchains have attracted millions of users, and the complexity of applications they host continues to grow more advanced, two key demands around privacy and scalability have emerged.
A crucial trend to identify is that, while special-purpose hardware is being developed for many of these applications, there is also a movement to optimize algorithms for consumer-grade hardware in an effort to preserve decentralization and privacy. One area that exemplifies this trend particularly well is in zero-knowledge proofs.
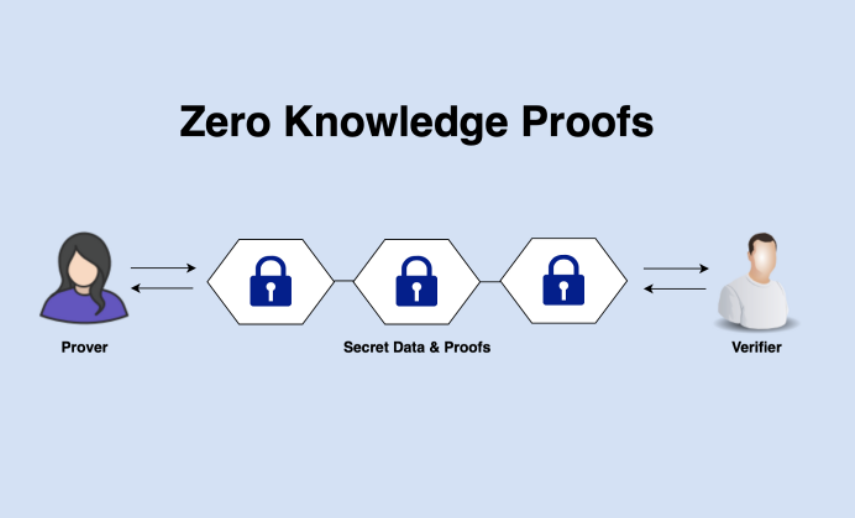
A brief overview of zero-knowledge proofs today
Zero-knowledge proofs provide a way to cryptographically prove knowledge of a particular set of information or data without actually revealing what that information is. Without getting too in the weeds, zero-knowledge proof constructions involve a “prover” and a “verifier”; the prover creates a proof from the knowledge of a system’s inputs, while the verifier has the ability to confirm that the prover has evaluated a computation authentically without knowing inputs or recomputing themselves. Zero-knowledge proofs have a variety of use-cases in blockchains today – the ones encountered most commonly are in the field of privacy (examples include IronFish, TornadoCash, Worldcoin, Zcash) or for scaling Ethereum by computationally verifying state transitions off-chain (examples include Polygon’s suite of zero-knowledge rollups, Starknet, and zkSync). Some, like Aleo and Aztec, propose to solve both privacy and scalability.
It’s worth taking a look under the hood at the cryptographic advancements — just in the past decade — that have made all of these applications feasible, faster, and perhaps most importantly, censorship-resistant and decentralized. Through a combination of advancements in algorithms and hardware, generating and verifying proofs has become cheaper and less computationally intensive. In many ways, these advancements mirror the democratization of technologies like the digital camera: you start out with an expensive and inefficient process before figuring out how to make things cheaper and faster. Perhaps most critically, advancements in zero-knowledge algorithms are beginning to provide alternatives to generating proof computation in servers and other centralized contexts.
Proof setups involve arithmetic circuits that gate the computation of a set of polynomials (which represent programs); these gates grow more complex as you attempt to scale the amount of information represented by those polynomials. Ideally, you want the range of possible outputs of a prover to be very large to decrease the likelihood that a prover will be able to computationally brute-force its way to the same number that the verifier is anticipating. (This is a concept known as collision resistance.) By increasing these numbers you increase the probabilistic security of the proof, just as in proof-of-work mining. A large number of outputs, however, can be very expensive and computationally slow to generate. This is where advancements in proving algorithms and hardware come in.
zkSNARKs, first introduced in 2011, are a key ingredient of these advancements. zkSNARKs essentially made it possible to efficiently scale the number of polynomials that can be gated, unlocking speed and more complex potential applications for zero-knowledge proofs.
The “SNARK” part of zkSNARK stands for “Succinct Non-Interactive Arguments of Knowledge”, and the words most crucial here in the context of web3 are “succinct” and “non-interactive.” A proof in a zkSNARK is only a few hundred bytes, which makes it easy for a verifier to quickly check that a proof is correct (though, as you will see, the proof itself may take a long time to generate, for reasons I’ll explain below). The non-interactive component is also critical: a non-interactive proof saves verifiers from needing to challenge statements submitted by provers; in the blockchain context, this would require clients to go back-and-forth with a verifier, which would be time-intensive and difficult to architect. It’s important to note that when zkSNARKs were first introduced, the idea of using them for privacy-preserving blockchains or to scale transactions was not mentioned; the original paper suggests things like a third-party efficiently running computations on a large set of data without needing to download or compile the dataset. While this example is theoretically similar to the kinds of use-cases in privacy and scaling, it took a few years for people in the field to apply zkSNARKs to cryptocurrencies.
轉貼自: a16z.com

留下你的回應
以訪客張貼回應