
摘要: 以色列就有一個案例,因為機器翻譯的錯誤,一名建築工人在他facebook上發了條狀態後,“成功”進了局子。
Facebook翻譯錯誤導致一名建築工人被抓,機器翻譯到底有多脆弱
這是最近幾年非常流行的一個句子,試試看能不能讀懂——
“Aoccdrnig to a rscheearch at Cmabrigde Uinervtisy, it deosn't mttaer in waht oredr the ltteers in a wrod are, the olny iprmoetnt tihng is taht the frist and lsat ltteer be at the rghit pclae.”
雖然大部分單詞都是拼寫錯誤的,但似乎並不會影響我們理解它的意思。
這說明:人在理解語言時,魯棒性是很強的,文本中即使漏掉一兩個字母或者拼寫錯誤,很多時候都不會影響人的閱讀。
但對機器翻譯(MT)系統來說,這些文本就幾乎是不可理喻的了。甚至!一不小心還會造成惡劣的影響。
近日在以色列就有一個案例,因為機器翻譯的錯誤,一名建築工人在他facebook上發了條狀態後,“成功”進了局子。
故事大概就是,這名建築工人10月15日在自己的facebook上發了一條狀態:“يصبحهم”(ySbHhm,阿拉伯語)並配了一張照片:

照片中他斜靠在一輛推土機上。這條狀態的原意是“good morning”,但facebook的MT 卻將它和“يؤذيهم”(y*bHhm)混淆了,兩者只差一個字母,但後者在希伯來語中的意思卻是“attack them”(用中文理解就是“宰了他們”)。

以色列警方此刻正監管網絡來找一群稱為“lone-wolf”的恐怖分子,所以立馬就注意到了這條狀態。
推土機+“宰了他們”(過去曾有恐怖分子用推土機進行恐怖襲擊),警方懷疑這個人很有可能要進行恐怖襲擊,於是立即就逮捕了他。審問幾個小時後才發現原來是機器翻譯的烏龍。
一、噪聲對機器翻譯影響有多大?
在我們的文本當中,拼寫錯誤(或者稱為噪聲)是很常見的現象,而在自然語言處理的各種神經網絡的訓練系統(包括翻譯系統)中卻並沒有一個明確的方案來解決這類問題。大家能夠抱希望的方式就是,通過在訓練數據中引入噪聲來減小翻譯過程中噪聲帶來的破壞。
但是在訓練數據集中引入噪聲或者不引入噪聲會帶來多大的影響呢?在不同的語言機器翻譯訓練中引入噪聲結果是否一致呢?似乎目前並沒有對這一問題嚴格的研究。
最近來自MIT的Yonatan Belinkov和來自華盛頓大學的Yonatan Bisk就此問題在arXiv上發表了一篇有意思的論文。

論文中,他們利用多種噪聲討論了目前神經網絡機器翻譯的脆弱性,並提出兩種增強翻譯系統魯棒性的方法:結構不變詞表示和基於噪聲文本的魯棒性訓練。他們發現一種基於字母卷積神經網絡的charCNN模型在多種噪聲中表現良好。
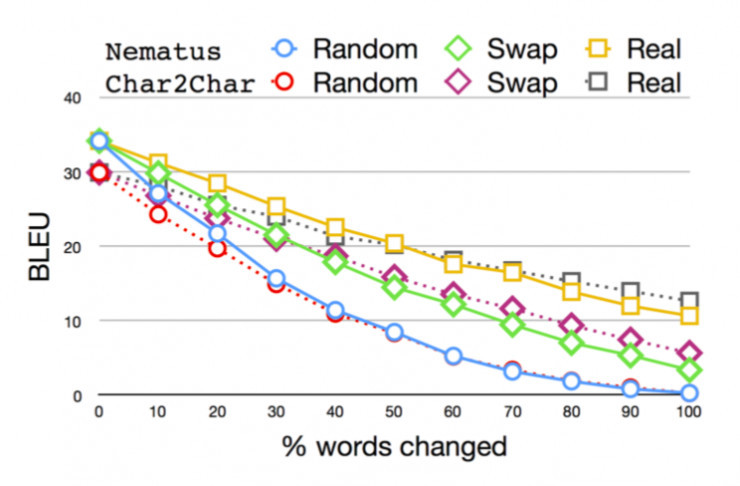
BLEU為機器翻譯結果與人工翻譯結果對比值(縱坐標應為%,作者忘記標註,下同)。可以看到隨著文本中加入噪聲的比例增加,機器翻譯的結果快速下降。
二、模型
作者選擇了三種不同的神經機器翻譯(NMT)模型以做對比,分別為:
1、char2char。這是一個seq-2-seq的模型,它有一個複雜的捲積編碼器、highway、循環層以及一個標準的循環解碼器。細節參見Lee等人(2017)的研究。這個模型在德-英、捷克-英之間的語言對翻譯上表現非常好。
2、Nematus。這也是一個seq-2-seq的模型,在去年的WMT和IWSLT上是一種較為流行的NMT工具包。
3、charCNN。作者用詞表示訓練了一個基於character卷積神經網絡(CNN)的seq-2-seq的模型。這個模型保留了一個單詞的概念,能夠學習一個依賴於字符的詞表示。因為它可以學習詞的形態信息表示,所以這個模型在形態豐富的語言上表現非常好。
三、數據
數據集來源:作者選用了TED為IWSLT 2016準備的測試數據。
噪聲來源:分為自然噪聲和人工噪聲。
1、自然噪聲
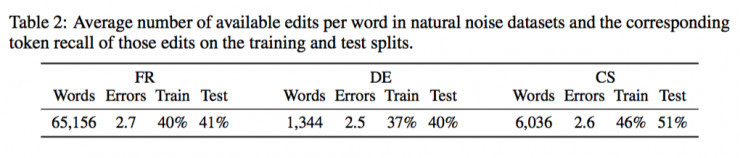
由於上面的數據集沒有帶有自然噪聲的平行語料庫,因此作者選擇了其他的可用的語料庫,例如:
法語:Max&Wisniewski在2010年從Wikipedia的編輯歷史中收集的“維基百科更正和解釋語料庫”(WiCoPaCo),在本文中僅僅提取了單詞更正的數據。
德語:由RWSE 維基百科修訂數據集(Zesch,2012)和MERLIN語言學習者語料庫(Wisniewski et al., 2013)。
捷克語:數據來源於非母語者手動註釋的散文。
2、人工噪聲
作者生成人工噪聲的方法有四種,分別為交換(Swap)、中間隨機(Middle Random)、完全隨機(Fully Random)和字母錯誤(Key Typo)。
交換(Swap):對一個字母個數大於4的單詞,除了第一個和最後一個字母不變外,隨機交換中間的任兩個字母一次。
中間隨機(Mid):對一個字母個數大於4的單詞,除了第一個和最後一個字母不變外,隨機排列中間所有的字母。
完全隨機(Rand):所有單詞的字母隨機排列。
字母錯誤(Key):在單詞中隨機選取一個字母,用鍵盤中和它臨近的字母替換(例如noise-noide)
四、乾淨文本訓練翻譯模型
作者首先測試了用乾淨(Vanilla)文本訓練出的模型是否能夠經受住噪聲的考驗。
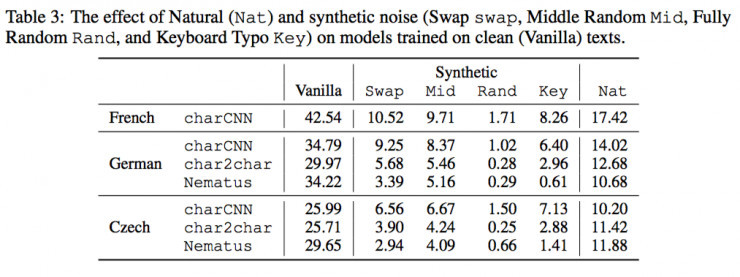
通過上表的結果,我們可以看出所有模型在有噪聲(不管是自然的還是合成的)BLEU值都會顯著下降。
或許通過下面這個例子,可以更明顯地感受到人類理解噪聲文本的能力與機器翻譯的能力有多大差別。

輸入文本是亂七八糟的德語文本,但人類翻譯仍然能夠根據文本猜測到意思,而目前幾個優秀的機器翻譯模型則表現很差。
五、兩種方法改進模型
1、meanChar模型
從上面的結果我們可以看到,三種NMT模型對單詞的結構都很敏感。Char2char和charCNN模型在字符序列上都有捲積層用來捕獲字符n-gram;Nematus模型則基於由BPE獲得的sub-word單元。因此所有這些模型對字符亂置(Swap、Mid、Rand)產生的噪聲都會敏感。
那麼可以通過對這樣的噪聲添加不變性來提高模型的魯棒性嗎?
最簡單的方法就是將一個單詞的embedding的平均值作為這個單詞的表示。作者將這種模型稱之為meanChar模型,也即先將單詞表示為一個平均embedding的單詞表示,然後在使用例如charCNN模型的字級編碼器。
很顯然,根據定義meanChar模型對字符亂置不再敏感,但是對其他類型的噪聲(Key和Nat)仍然敏感。
用Vanilla文本訓練meanChar模型,然後用噪聲文本測試(由於字符亂置不影響結果,將Swap、Mid、Rand合為Scr)。結果如下表第一行所示,可以看出的是,meanChar模型用在法語和德語中對Scrambled文本表現提高了7個百分點,但捷克語表現很糟糕,這可能是由於其語言複雜的形態。
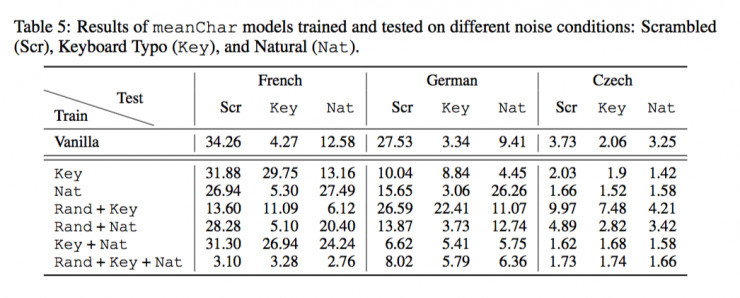
2、黑箱對抗訓練
為了提高模型的魯棒性,作者採用了黑箱對抗訓練的方法,也即用帶噪聲文本訓練翻譯模型。
首先用如上表,用噪聲文本訓練在某些語言(例如法語)上表現良好,但是其魯棒性並不具有穩定的提高。這也很明顯,meanChar模型並不一定能解決key或者Nat噪聲的問題。
那麼如果我們用更複雜的charCNN模型就會提高模型對不同種類噪聲的魯棒性嗎?作者將用於訓練的Scr文本拆開來訓練模型——

發現:
1)儘管模型在不同的噪聲下仍然表現不一,但整體平均的表現有所提升。
2)用Rand數據訓練出的模型,對Swap和Mid文本測試結果都表現良好;而反之則不成立。這說明在訓練數據中更多的噪聲能夠提高模型的魯棒性。
3)只有用Nat數據集來訓練,才能提高Nat數據集測試的魯棒性。這個結果表明了計算模型和人類的表現之間的一個重要區別——在學習語言時,人類並沒有明確地暴露在噪聲樣本中。
4)作者將三種噪聲(Rand+Key+Nat)混合起來訓練模型,發現雖然針對每一個樣本的測試都表現略差,但整體上的魯棒性卻是較高的,而且對於多種噪聲具有普遍性。
六、對結果的分析
從上面的結果可以看出,多種噪聲同時訓練charCNN的模型的魯棒性更好。But why?
作者猜測可能是不同的捲積濾波器在不同種類的噪聲中學到了魯棒性。一個卷積濾波器原則上可以通過採用相等或接近相等的權重來捕獲平均(或總和)的操作。
為了檢驗這個猜測,他們分析了分別用Rand數據和Rand+Key+Nat數據訓練的兩個charCNN模型學習到的權重。針對每個模型,他們計算了1000個過濾器中每一個過濾器維度上的方差,然後對這些變量做以平均。結果如下圖
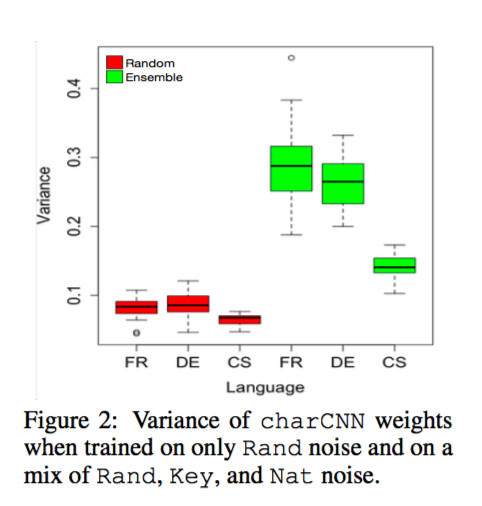
從圖上可以看出,Rand模型學到的權重方差要遠小於混合噪聲模型學到的權重方差。換句話說,混合噪聲訓練的模型學習了更多不同的權重,除了平均表示(meanChar)外,還有助於捕捉形態屬性。
而另一方面,混合噪聲模型中方差的變化則較大,表明不同字符嵌入維度的濾波器之間存在較大的差異。相比之下Rand模型中方差的變化就接近零。
另一方面,我們還看到合成噪聲訓練的模型沒有一個在Nat數據的測試中表現較好的。這表明自然噪聲合成噪聲有很大的不同。作者人工地檢測了德語的Nat數據集中大約40個樣本後,發現在Nat數據集中最常見的噪聲來源是語言中的語音或音韻錯誤(34%)和字母遺漏(32%)。這些在合成噪聲中並沒有,所以這表明要生成更好合成噪聲可能需要更多關於音素以及相應語言的知識。
七、總結
讓我們用Rand+key+Nat的charCNN模型來翻譯一下前面那個混亂的德語翻譯吧:
“According to a study of Cambridge University, it doesn't matter which technology in a word is going to get the letters in a word that is the only important thing for the first and last letter.”
當然,他們的結果並不完美,但非常值得借鑒。
轉貼自: 煉數成金





留下你的回應
以訪客張貼回應