
摘要: 在本文中,作者列出了 2017 年 GitHub 平臺上最爲熱門的知識庫,囊括了數據科學、機器學習、深度學習中的各種項目,希望能對大家學習、使用有所幫助。
GitHub 是計算機科學領域最爲活躍的社區,在 GitHub 上,來自不同背景的人們分享越來越多的軟件工具和資源庫。在其中,你不僅可以獲取自己所需的工具,還可以觀看代碼是如何寫成並實現的。
作爲一名機器學習愛好者,作者在本文中列出了 2017 年 GitHub 平臺上最爲熱門的知識庫,其中包含了學習資料與工具。希望對你的學習和研究有所幫助。
目錄
1. 學習資源
1. Awesome Data Science
2. Machine Learning / Deep Learning Cheat Sheet
3. Oxford Deep Natural Language Processing Course Lectures
4. PyTorch – Tutorial
5. Resources of NIPS 2017
2. 開源工具
1. TensorFlow
2. TuriCreate – A Simplified Machine Learning Library
3. OpenPose
4. DeepSpeech
5. Mobile Deep Learning
6. Visdom
7. Deep Photo Style Transfer
8. CycleGAN
9. Seq2seq
10. Pix2code
3. 項目
1. AI00-百家影響人工智能未來的公司
2. Artificial-Intelligence-Terminology
3. ML-Tutorial-Experiment
1. 學習資源
1.1 Awesome Data Science
資源網址: https://github.com/bulutyazilim/awesome-datascience
該 repo 是數據科學的基本資源。多年來的無數貢獻構建了此 repo 裏面的各種資源,從入門指導、信息圖,到社交網絡上你需要 follow 的賬號。無論你是初學者還是業內老兵,裏面都有大量的資源需要學習。
從該 repo 的目錄可以看出其深度。
1.2 Machine Learning / Deep Learning Cheat Sheet
資源網址:https://github.com/kailashahirwar/cheatsheets-ai
該項目以 cheatsheet 的形式介紹了機器學習/深度學習中常用的工具與技術,從 pandas 這樣的簡單工具到深度學習技術都涵蓋其中。在收藏或者 fork 該項目之後,你就不用再費事搜索常用的技巧和注意事項了。
簡單介紹下,cheatsheets 類型包括 pandas、numpy、scikit learn、matplotlib、ggplot、dplyr、tidyr、pySpark 和神經網絡。
1.3 Oxford Deep Natural Language Processing Course Lectures
資源網址:https://github.com/oxford-cs-deepnlp-2017/lectures
斯坦福的 NLP 課程一直是自然語言處理領域的金牌教程。但是近期隨着深度學習的發展,在 RNN 和 LSTM 等深度學習架構的幫助下,NLP 出現了大量進步。
該 repo 基於牛津大學的 NLP 課程,涵蓋先進技術和術語,如使用 RNN 進行語言建模、語音識別、文本轉語音(TTS)等。該 repo 包含該課程從課程材料到實踐聯繫的所有內容。
1.4 PyTorch – Tutorial
資源網址:https://github.com/yunjey/pytorch-tutorial

截至今天,PyTorch 仍是 TensorFlow 的唯一競爭對手,它的功能和聲譽使其成爲了頗具競爭力的深度學習框架。因其 Pythonic 風格的編程、動態計算圖和更快的原型開發,Pytorch 已經獲得了深度學習社區的廣泛關注。
該知識庫包含 PyTorch 上大量的深度學習任務代碼,包括 RNN、GAN 和神經風格遷移。其中的大多數模型在實現上僅需 30 餘行代碼。這充分說明了 PyTorch 的抽象能力,它讓研究人員可以專注於找到正確的模型,而無需糾纏於編程語言和工具選擇等細節。
1.5 Resources of NIPS 2017
資源網址:https://github.com/hindupuravinash/nips2017
該 repo 包含 NIPS 2017 的資源和所有受邀演講、教程和研討會的幻燈片。NIPS 是一年一度的機器學習和計算神經科學會議。
過去幾年中,數據科學領域內的大部分突破性研究都曾作爲研究結果出現在 NIPS 大會上。如果你想站在領域前沿,那這就是很好的資源!
2. 開源軟件庫
2.1 TensorFlow

資源網址:https://github.com/tensorflow/tensorflow
TensorFlow 是一種採用數據流圖(data flow graph)進行數值計算的開源軟件庫。其中 Tensor 代表傳遞的數據爲張量(多維數組),Flow 代表使用計算圖進行運算。數據流圖用「結點」(node)和「邊」(edge)組成的有向圖來描述數學運算。「結點」一般用來表示施加的數學操作,但也可以表示數據輸入的起點和輸出的終點,或者是讀取/寫入持久變量(persistent variable)的終點。邊表示結點之間的輸入/輸出關係。這些數據邊可以傳送維度可動態調整的多維數據數組,即張量(tensor)。
TensorFlow 自正式發佈以來,一直保持着「深度學習/機器學習」頂尖庫的位置。谷歌大腦團隊和機器學習社區也一直在積極地貢獻並保持最新的進展,尤其是在深度學習領域。
TensorFlow 最初是使用數據流圖進行數值計算的開源軟件庫,但從目前來看,它已經成爲構建深度學習模型的完整框架。它目前主要支持 TensorFlow,但也支持 C、C++ 和 Java 等語言。此外,今年 11 月谷歌終於發佈了新工具的開發者預覽版本,這是一款 TensorFlow 用於移動設備和嵌入式設備的輕量級解決方案。
2.2 TuriCreate:一個簡化的機器學習庫

資源網址:https://github.com/apple/turicreate
TuriCreate 是蘋果最近貢獻的一個開源項目,它爲機器學習模型提供易於使用的創建方法和部署方法,這些機器學習模型包括目標檢測、人體姿勢識別和推薦系統等複雜任務。
可能我們作爲機器學習愛好者會比較熟悉 GraphLab Create,一個非常簡便高效的機器學習庫,而當初創建該庫的公司 TuriCreate 被蘋果收購時,造成了很大反響。
TuriCreate 是針對 Python 開發的,且它最強的的特徵是將機器學習模型部署到 Core ML 中,用於開發 iOS、macOS、watchOS 和 tvOS 等應用程序。
2.3 OpenPose
資源網址: https://github.com/CMU-Perceptual-Computing-Lab/openpose
OpenPose 是一個多人關鍵點檢測庫,它可以幫助我們實時地檢測圖像或視頻中某個人的位置。OpenPose 軟件庫由 CMU 的感知計算實驗室開發並維護,對於說明開源研究如何快速應用於部署到工業中,它是非常好的一個案例。

OpenPose 的一個使用案例是幫助解決活動檢測問題,即演員完成的動作或活動能被實時捕捉到。然後這些關鍵點和它們的動作可用來製作動畫片。OpenPose 不僅有 C++的 API 以使開發者能快速地訪問它,同時它還有簡單的命令行界面用來處理圖像或視頻。
2.4 DeepSpeech
資源網址: https://github.com/mozilla/DeepSpeech
DeepSpeech 是百度開發的開源實現庫,它提供了當前頂尖的語音轉文本合成技術。它基於 TensorFlow 和 Python,但也可以綁定到 NodeJS 或使用命令行運行。
Mozilla 一直是構建 DeepSpeech 和開源軟件庫的主要研究力量,Mozilla 技術戰略副總裁 Sean White 在一篇博文中寫道:「目前只有少數商用質量的語音識別引擎是開源的,它們大多數由大型公司主宰。這樣就減少了初創公司、研究人員和傳統企業爲它們的用戶定製特定的產品與服務。但我們與機器學習社區的衆多開發者和研究者共同完善了該開源庫,因此目前 DeepSpeech 已經使用了複雜和前沿的機器學習技術創建語音到文本的引擎。」
2.5 Mobile Deep Learning
資源網址:https://github.com/baidu/mobile-deep-learning
該 repo 將數據科學中的當前最佳技術移植到了移動平臺上。該 repo 由百度研究院開發,目的是將深度學習模型以低複雜性和高速度部署到移動設備(例如 Android 和 IOS)上。
該 repo 解釋了一個簡單的用例,即目標檢測。它可以識別目標(例如一張圖像中的手機)的準確位置,很棒不是嗎?

2.6 Visdom
資源網址:https://github.com/facebookresearch/visdom
Visdom 支持圖表、圖像和文本在協作者之間進行傳播。你可以用編程的方式組織可視化空間,或者通過 UI 爲實時數據創建儀表盤,檢查實驗結果,或者調試實驗代碼。
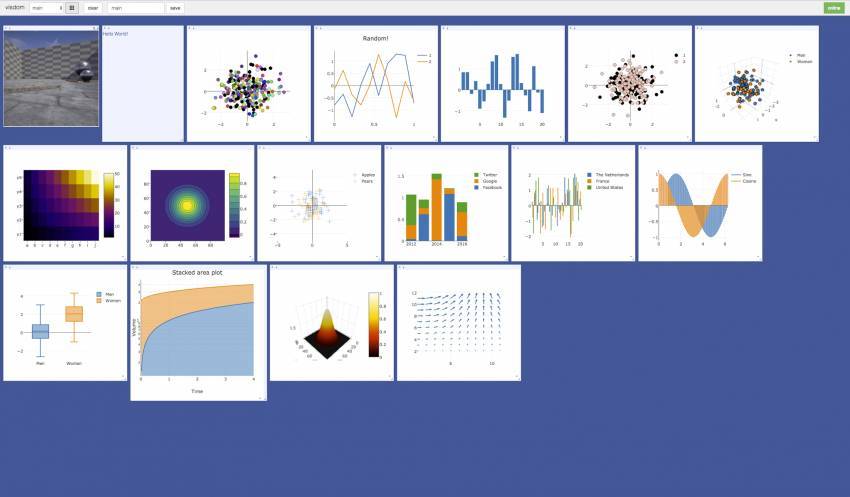
繪圖函數中的輸入會發生改變,儘管大部分輸入是數據的張量 X(而非數據本身)和(可選)張量 Y(包含可選數據變量,如標籤或時間戳)。它支持所有基本圖表類型,以創建 Plotly 支持的可視化。
Visdom 支持使用 PyTorch 和 Numpy。
2.7 Deep Photo Style Transfer
資源網址:https://github.com/luanfujun/deep-photo-styletransfer
該 repo 基於近期論文《Deep Photo Style Transfer》,該論文介紹了一種用於攝影風格遷移的深度學習方法,可處理大量圖像內容,同時有效遷移參考風格。該方法成功克服了失真,滿足了大量場景中的攝影風格遷移需求,包括時間、天氣、季節、藝術編輯等場景。

2.8 CycleGAN
資源網址:https://github.com/junyanz/CycleGAN
CycleGAN 是一個有趣且強大的庫,展現了該頂尖技術的潛力。舉例來說,下圖大致展示了該庫的能力:調整圖像景深。這裏有趣的點在於你事先並沒有告訴算法需要注意圖像的哪一部分。算法完全依靠自己做到了!

目前該庫用 Lua 編寫,但是它也可以在命令行中使用。
2.9 Seq2seq
資源網址:https://github.com/google/seq2seq
Seq2seq 最初是爲機器翻譯而建立的,但已經被開發用於多種其它任務,包括摘要生成、對話建模和圖像捕捉。只要一個問題的結構是將輸入數據編碼爲一種格式,並將其解碼爲另一種格式,就可以使用 Seq2seq 框架。它使用了所有流行的基於 Python 的 TensorFlow 庫進行編程。
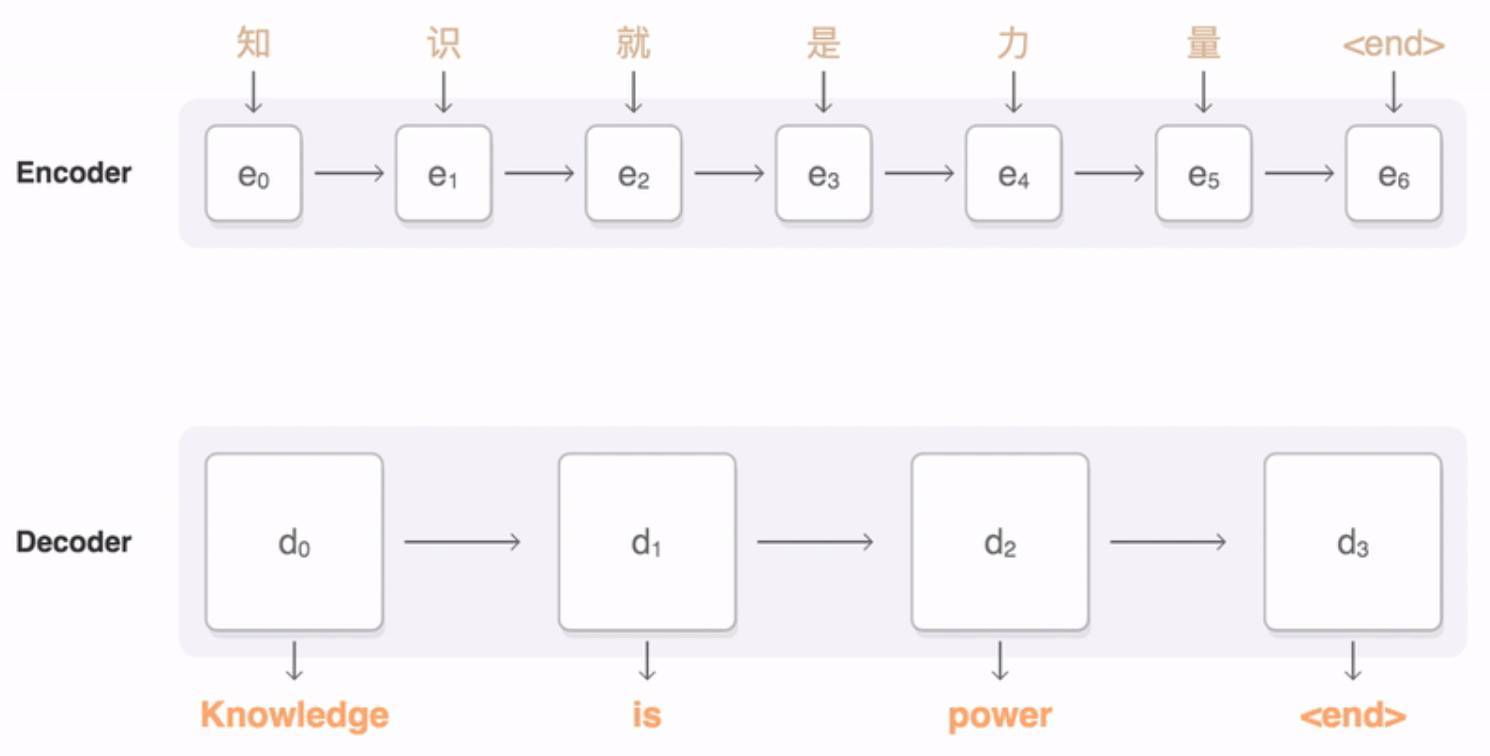
2.10 Pix2code
資源網址:https://github.com/tonybeltramelli/pix2code
這個深度學習項目非常令人振奮,它嘗試爲給定的 GUI 自動生成代碼。當建立網站或移動設備界面的時候,通常前端工程師必須編寫大量枯燥的代碼,這很費時和低效。這阻礙了開發者將主要的時間用於實現真正的功能和軟件邏輯。Pix2code 的目的是通過將過程自動化來克服這一困難。它基於一種新方法,允許以單個 GUI 截圖作爲輸入來生成計算機 token。
Pix2code 使用 Python 編寫,可將移動設備和網站界面的捕捉圖像轉換成代碼。
3. 項目
目前在 GitHub 上也有三個項目,分別是評估人工智能各領域優秀公司的 AI00、人工智能領域中英術語集和模型試驗與解釋項目。
3.1 AI00——百家影響人工智能未來的公司榜單
資源網址:https://github.com/jiqizhixin/AI00
人工智能是一個複雜龐大的體系,涉及衆多學科,也關乎技術、產品、行業和資本等衆多要素,本報告的寫作團隊只代表他們的專業觀點,有自己的侷限性,需要更多行業專家參與進來加以修正和完善。
我們深刻地理解在沒有專業用戶反饋的情況下所做出報告的質量侷限性,所以希望用工程界「Agile Development」的理念來對待我們的報告,不斷收集專業反饋來持續提升報告質量。
爲此,我們將邀請人工智能領域的科學家、技術專家、產業專家、專業投資人和讀者加入進來,共同完成這項人工智能的長期研究。我們將對參與者提供的信息進行彙總和整理,以月度爲單位更新此份報告。
3.2 Artificial-Intelligence-Terminology
資源網址:https://github.com/jiqizhixin/Artificial-Intelligence-Terminology
我們在編譯技術文章和論文過程中所遇到的專業術語記錄下來,希望有助於大家查閱和翻譯(第二版)。
本詞彙庫目前擁有的專業詞彙共計 760 個,主要爲機器學習基礎概念和術語,同時也是該項目的基本詞彙。我們將繼續完善術語的收錄和擴展閱讀的構建。
詞彙更新主要分爲兩個階段,第一階段將繼續完善基礎詞彙的構建,即通過權威教科書或其它有公信力的資料抽取常見術語。第二階段將持續性地把編譯論文或其他資料所出現的非常見術語更新到詞彙表中。
讀者的反饋意見和更新建議將貫穿整個階段,並且我們將在項目致謝頁中展示對該項目起積極作用的讀者。因爲我們希望術語的更新更具準確度和置信度,所以我們希望讀者能附上該術語的來源地址與擴展地址。因此,我們能更客觀地更新詞彙,並附上可信的來源與擴展。

3.3 ML-Tutorial-Experiment
資源網址:https://github.com/jiqizhixin/ML-Tutorial-Experiment
該項目主要是展示我們在實驗機器學習模型中所獲得的經驗與解釋,目前我們解釋並實現了卷積神經網絡、生成對抗網絡和 CapsNet。這些實現都有非常詳細的文章以說明模型的結構與實現代碼。如下所示爲這三個實現項目的說明:
原文網址:https://www.analyticsvidhya.com/blog/2017/12/15-data-science-repositories-github-2017/
轉貼自: 壹讀



留下你的回應
以訪客張貼回應