
摘要: 編程時遇到問題大部分的人會習慣性去查找資料,但本篇作者認為,相較於快速找到答案缺法思考過程,應學習如何用函數和概念理解每次遇到的問題;調整學習法或編程習慣,才能真正提升效率、也能幫助我們對語法更加熟知。

如果你發覺自己在編程時一次又一次地查找相同的問題、概念或是語法,你不是一個人!
雖然我們在 StackOverflow 或其他網站上查找答案是很正常的事情,但這樣做確實比較花時間,也讓人懷疑你是否完全理解了這門編程語言。
我們現在生活的世界裡,似乎有著無限的免費資源,而你只需要一次搜索即可獲得。
然而,這既是這個時代的幸事,也是一種詛咒。如果沒能有效利用資源,而是對它們過度依賴,你就會養成不良的習慣,長期處於不利境地。
當我谷歌一個問題,發現有人提了同樣問題,但下面只有一個回答,而且 2003 年以後就再也沒有新的答案的時候,我真是和那個提問者同病相憐!弱小,可憐又無助!
就個人而言,我發現自己也是多次從類似的技術問答中找代碼;而不是花時間學習和鞏固概念,以便下次可以自己把代碼寫出來。
網上搜索答案是一種懶惰的行為,雖然在短期內它可能是最簡便的途徑,但它終究不利於你的成長,並且會降低工作效率和對語法的熟知能力 。
目標
最近,我一直在 Udemy 學習名為 Python for Data Science and Machine Learning 的數據科學在線課程。在該系列課程的早期課件中,我想起了用 Python 做數據分析時一直被我忽略的一些概念和語法。
為了一勞永逸地鞏固我對這些概念的理解,並為大家免去一些 StackOverflow 的搜索,我在文章中整理了自己在使用 Python,NumPy 和 Pandas 時總是忘記的東西。
我為每個要點提供了簡短的描述和示例。為了給讀者帶來福利,我還添加了視頻和其他資源的鏈接,以便大家更深入地了解各個概念。
單行 List Comprehension
每次需要定義某種列表時都要寫 for 循環是很乏味的,好在 Python 有一種內置的方法可以用一行代碼解決這個問題。該語法可能有點難以理解,但是一旦熟悉了這種技巧,你就會經常使用它。

* Line 8 是對 for loop 的單行簡化
請參閱上圖和下文的示例,比較一下在創建列表時,你通常使用的 for 循環樣板和以單行代碼創建這二者之間的差別。
x = [1,2,3,4]out = []foritem in x: out.append(item**2)print(out)[1,4,9,16]# vs.x = [1,2 ,3,4]out = [item**2 foritem in x]print(out)[1,4,9,16]
Lambda 函數
編程的過程中經常為了實現最後的功能,創建一個又一個階段性的函數,這些函數往往就只用一兩次。這個過程很煩人。這時候 Lambda 函數來搭救你了!
Lambda 函數用於在 Python 中創建小型的,一次性的和匿名的函數對象。
基本上,它們可以讓你「在不創建新函數的情況下」創建一個函數。
lambda 函數的基本語法如下:
lambda arguments: expression
所以,只要給它一個表達式,lambda 函數可以執行所有常規函數可執行的操作。請看下面的簡單示例和後文中的視頻,以更好地感受 lambda 函數強大的功能。
double= lambda x: x *2print(double(5))10
Map 和 Filter
一旦掌握了 lambda 函數,並學會將它們與 map 和 filter 函數配合使用,你將擁有一個強大的工具。
具體來說,map 函數接受一個列表並通過對每個元素執行某種操作來將其轉換為新列表。在下面的示例中,它遍歷每個元素並將其乘以 2 的結果映射到新列表。請注意,這裡的 list 函數只是將輸出轉換為列表類型。
# Mapseq = [1,2,3,4,5]result =list(map(lambda var: var*2, seq))print(result)[2,4,6,8,10]
filter 函數需要的輸入是列表和規則,非常類似於 map,但它通過將每個元素與布爾過濾規則進行比較來返回原始列表的子集。
點擊觀看視頻
https://v.qq.com/x/page/v073178iyd7.html
# Filterseq = [1,2,3,4,5]result =list(filter(lambda x: x >2, seq))print(result)[3,4,5]
Arange 和 Linspace
要創建快速簡單的 NumPy 數組,可以查看 arange 和 linspace 函數。它們都有特定的用途,但在這裡我們看中的是它們都輸出 Numpy 數組(而非其使用範圍),這通常更容易用於數據科學。
Arange 在給定的範圍內返回間隔均勻的值。除了起始值和終止值,你還可以根據需要定義步長或數據類型。請注意,終止值是一個「截止」值,因此它不會被包含在數組輸出中。
# np.arange(start, stop, step)np.arange(3,7,2)array([3,5])
Linspace 與 Arange 非常相似,但略有不同。Linspace 是在指定的範圍內返回指定個數的間隔均勻的數字。所以給定一個起始值和終止值,並指定返回值的個數,linspace 將根據你指定的個數在 NumPy 數組中劃好等分。這對於數據可視化和在定義圖表坐標軸時特別有用。
# np.linspace(start, stop, num)np.linspace(2.0,3.0, num=5)array([2.0,2.25,2.5,2.75,3.0])
Axis 的真正意義
在 Pandas 中刪除列或在 NumPy 矩陣中對值進行求和時,可能會遇到這問題。即使沒有,那麼你也肯定會在將來的某個時候碰到。我們現在來看看刪除列的示例:
df.drop(‘Row A’, axis=)df.drop(‘Column A’, axis=1)
在我知道自己為什麼要這樣定義坐標軸之前,我不知道我寫了多少次這行代碼。你可以從上面看出,如果要處理列,就將 axis 設為 1,如果要處理行,則將其設為 0。
但為什麼會這樣呢?我記得我最喜歡的解釋是這個:
df.shape(# of Rows, # of Columns)
從 Pandas 的 dataframe 調用 shape 屬性時會返回一個元組,其中第一個值表示行數,第二個值表示列數。如果你想想在 Python 中是如何建立索引的,即行為 0,列為 1,會發現這與我們定義坐標軸值的方式非常相似。很有趣吧!
點擊查看視頻
https://v.qq.com/x/page/l0731dgtsn4.html
Concat, Merge, 和 Join
如果你熟悉 SQL,那麼這些概念對你來說可能會更容易。無論如何,這些功能基本上就是以特定方式組合 dataframe 的方法。可能很難評判在什麼時候使用哪個最好,所以讓我們都回顧一下。
Concat 允許用戶在其下方或旁邊附加一個或多個 dataframe(取決於你如何定義軸)。
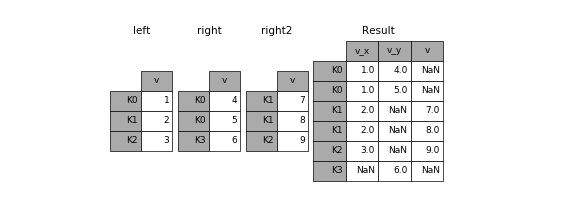
Merge 可以基於特定的、共有的主鍵(Primary Key)組合多個 dataframe。
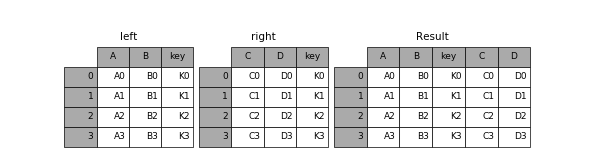
Join,就像 merge 一樣,可以組合兩個 dataframe。但是,它根據它們的索引進行組合,而不是某些特定的主鍵。
大家可以查看很有幫助的 Pandas 文檔,了解語法和具體示例和你可能會遇到的特殊情況。
Pandas Apply
apply 類似於 map 函數,不過它是用於 Pandas DataFrames 的,或者更具體地說是用於 Series 的。如果你不熟悉也沒關係,Series 在很大程度上與 NumPy 中的陣列(array)非常相似。
Apply 會根據你指定的內容向列或行中的每個元素發送一個函數。你可以想像這是多麼有用,特別是在對整個 DataFrame 的列處理格式或運算數值的時候,可以省去循環。
點擊觀看視頻
https://v.qq.com/x/page/q0731vakmj0.html
透視表
最後要說到的是透視表。如果你熟悉 Microsoft Excel,那麼你可能已經聽說過數據透視表。Pandas 內置的 pivot_table 函數將電子表格樣式的數據透視表創建為 DataFrame。請注意,透視表中的維度存儲在 MultiIndex 對像中,用來聲明 DataFrame 的 index 和 columns。
結語
我的這些 Python 編程小幫肘就到此為止啦。我希望我介紹的這些在使用 Python 做數據科學時經常遇到的重要但又有點棘手的方法、函數和概念能給你帶來幫助。
而我自己在整理這些內容並試圖用簡單的術語來闡述它們的過程中也受益良多。
轉貼自: 科技報橘


留下你的回應
以訪客張貼回應