
摘要: 並不是每個網站都歡迎爬蟲,本文教你如何爬不歡迎一般爬蟲的網站文章
Goodinfo!台灣股市資訊網相信您不陌生,上頭不只是股票價格資訊,就廉直利率、盈餘分配、董監持股等,資訊極為豐富,但著手寫爬蟲時,卻發現爬下其資料並不如想像那般容易。
並不是每個網站都歡迎爬蟲,雖然爬蟲爬的都是屬於公開資料,但是這些股票網站的資料來源,基本上都是向證券交易所買的,這必須支付一筆費用,即使不是用買的,即時取得資料還是有其需要付出的成本,還花錢花時間見機台架網站,並且付出勞力維護,被一隻爬蟲簡簡單單的拉下資料對網站來說實在太不划算了。
但不是不可能取得使用爬蟲,就從網路的原理來告訴您!
網路封包傳送:
這原因來自於封包傳送的差異性,封包傳送的方式分為Get與Post,就分別解釋讓您深入的了解。
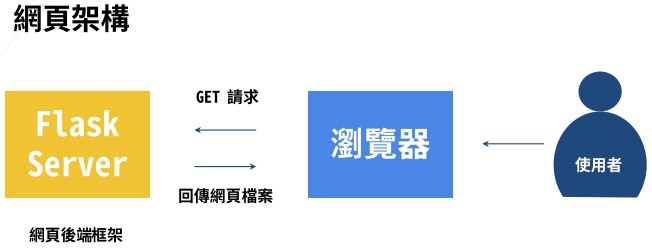
上圖為網路架構,使用者在向瀏覽器請求時,瀏覽器會與遠方網站的伺服器溝通,其溝通就是利用封包來傳送,而封包的內容如下圖,裡面會記錄傳送者IP、收件者IP、雙方位置、時間、協定,當然最重要的就是裡頭的傳送內容,每個毫秒都會有大量的封包流進流出,因為不可能一個網頁只用一個封包就傳遞出去,這樣這個封包的檔案會非常的大,因此封包的傳遞會如同線上影音平台一般,分成許多段載入,因此如果您的網速較慢,也會發現載入網站時,網站會一塊一塊的補齊(有少部分網站不是這樣設計),就是因為有些封包資料還沒到,導致還未顯示部分畫面。
Get資料傳送方式:
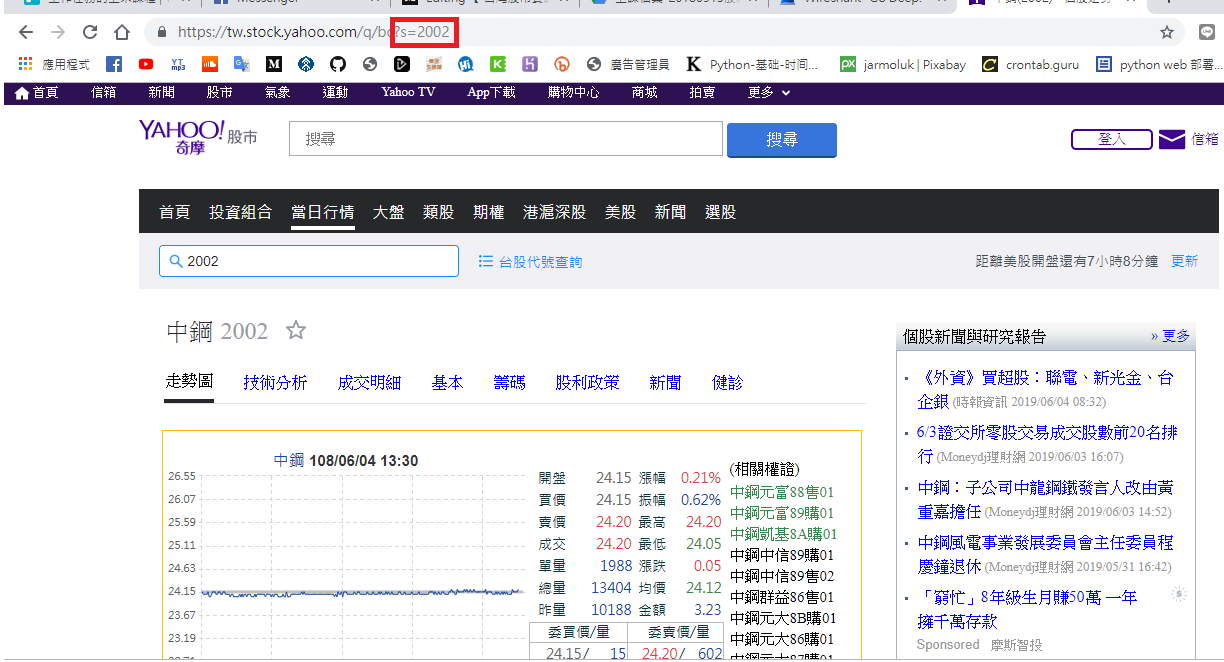
了解網路的基本架構後,就來深入了解兩種不同的資料傳遞方式。Get是最常見的一種資料傳送方式,其實一般最簡單的爬蟲,就是利用這個方式取得的,如何辨別呢?非常的簡單,只要您發現該網站網址的地方,後方有一個「?」然後再接上''某個變數''=''數字'',這就是一個Get的傳送,例如我們常見的Yahoo股票網站,先前的文章也是以這個方式進行爬蟲,只要改變等號後的數字,就會改變整個網頁。
其優點為傳遞資訊快速且方便,但缺點為傳遞的內容一目瞭然,因此通常只會用來傳遞不具隱私性的資料。
Post資料傳送方式:
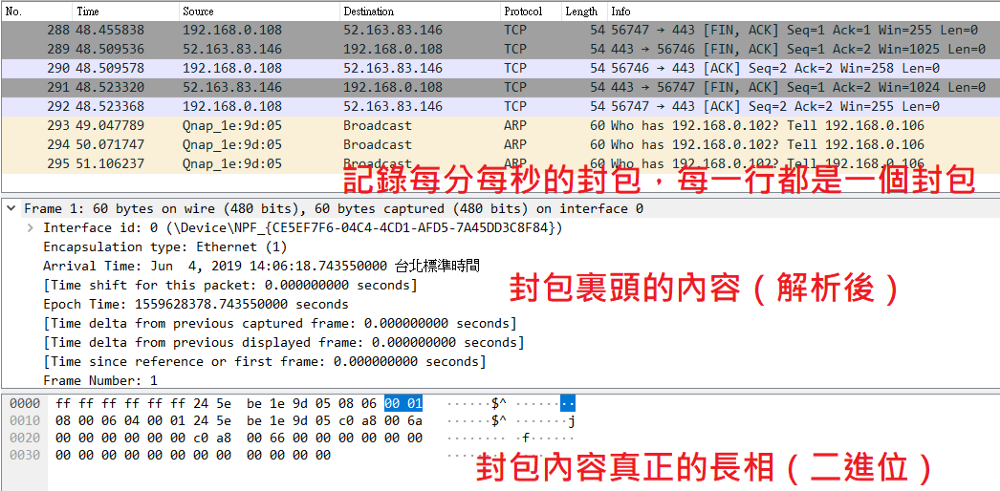
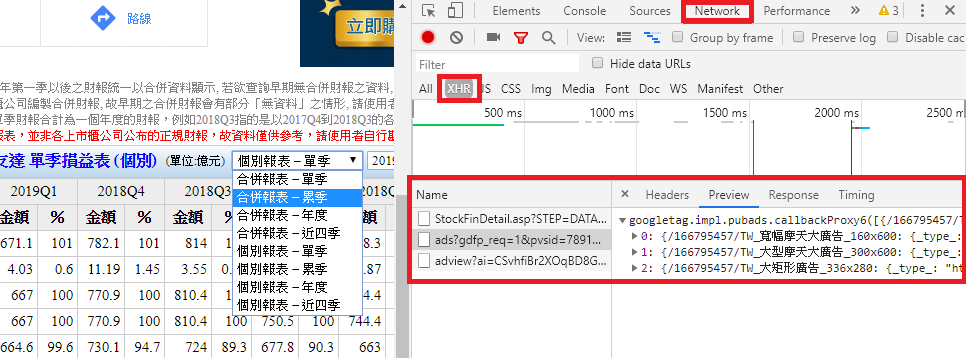
這個傳送方式是本篇文章的主角了,也是造成台灣股市資訊網無法爬下來的原因。如下圖所示,不管選擇何種損益表的模式,網址都不會有任何的改變,因為您的每一個請求,是以Post的封包傳遞出去,要如何看到呢?在您還未選擇之前,直接按下「F12」按鍵,右方(有的會在下方,可依自己設定)會出現一塊欄位,一開始欄位都會是空白的,請重新整理網頁,就會出現大量的封包資料;上方選單選擇「Network」,往下一層選擇XHR的封包類型(選擇All也找的到,可是會參雜很多其類型的封包),最下方的欄位就會顯示所有剛剛的封包了,如下圖中有三個封包。
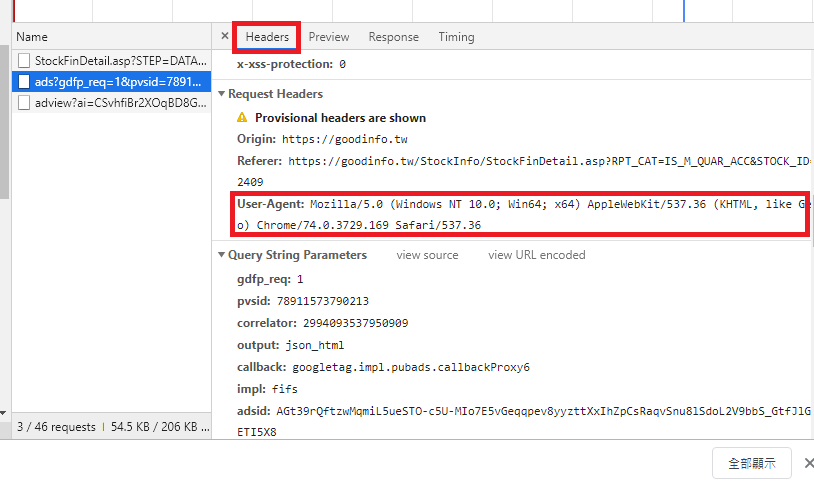
點選「Headers」可以看到封包的標頭訊息(如下圖),裏頭有傳送Post封包必要的資訊,其中紅框的部分,「User-Agent」便是爬蟲的關鍵,台灣股市資訊網是依照封包內有無這個資訊,來判斷是否為機器人,引此在程式碼中加入這項資訊,便可以騙過伺服器,每個伺服器判斷的方式不同,或許還需要更多的判斷資訊,當然這樣的網站就會更加嚴謹,先前爬蟲的文章也有使用Post的方式擷取。
其優點為訊息的隱密性變高,但不代表就看不到內容,下圖的示範還是可以看到內容,要隱私還是必須要加密,但缺點是資料的打包變得比較慢,若一般資訊都使用這種方式,網路會打結。
下圖的表格給您一個清楚的整理。

已經找到問題,並理解其原理,現在就開始動手打造吧。其實程式碼就如同一般的爬蟲,只要更改headers的部分,將其換成自己的headers即可,headers的內容可以看到您電腦的相關內容,例如作業系統、系統位元數、瀏覽器以及版本等。

會發現在requests的部分,不再是requests.get而是reguests.post,即是換使用Post的方法來傳送,這個方法才能將headers帶上一並傳送。
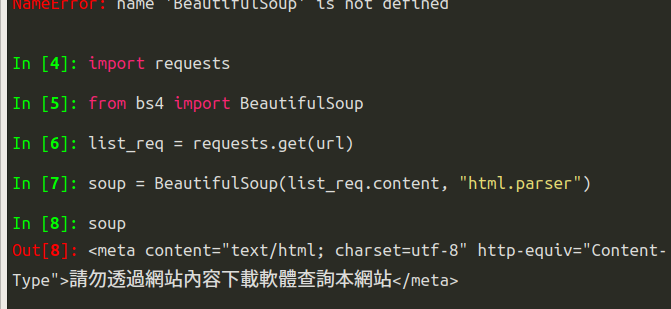
完成後可以執行soup,即可看到,將整個網站的html拉下來了。
您可能會覺得,既然都是表格的話,可否使用Pandas的爬蟲套件來擷取表格,但經過實驗後,Pandas無法成功解析出其中的

標籤,因此這個方法不可行,還是得要用BeautifulSoup套件爬取後,再進行資料整理。
轉貼自: 行銷資料科學
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應