
摘要: 深度學習(或生活中大部分領域)的關鍵在於實踐。你需要練習解決各種問題,包括圖像處理、語音識別等。每個問題都有其獨特的細微差別和解決方法。
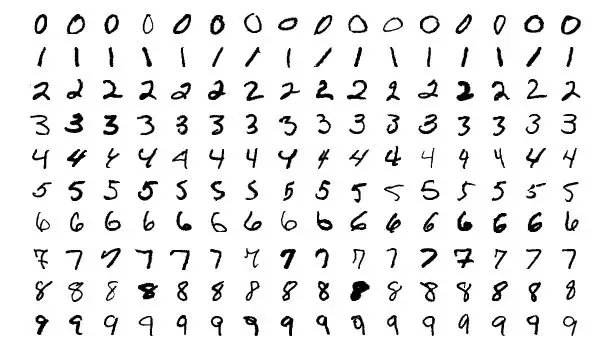
但是,從哪裏獲得數據呢?現在許多論文都使用專有數據集,這些數據集通常並不對公衆開放。如果你想學習並應用技能,那麼無法獲取合適數據集是個問題。
如果你面臨着這個問題,本文可以爲你提供解決方案。本文介紹了一系列公開可用的高質量數據集,每個深度學習愛好者都應該試試這些數據集從而提升自己的能力。在這些數據集上進行工作將讓你成爲一名更好的數據科學家,你在其中學到的知識將成爲你職業生涯中的無價之寶。我們同樣介紹了具備當前最優結果的論文,供讀者閱讀,改善自己的模型。
如何使用這些數據集?
首先,你得明白這些數據集的規模非常大!因此,請確保你的網絡連接順暢,在下載時數據量沒有或幾乎沒有限制。
使用這些數據集的方法多種多樣,你可以應用各種深度學習技術。你可以用它們磨鍊技能、瞭解如何識別和構建各個問題、思考獨特的使用案例,也可以將你的發現公開給大家!
數據集分爲三類——圖像處理、自然語言處理和音頻/語音處理。
圖像處理數據集
MNIST
MNIST 是最流行的深度學習數據集之一。這是一個手寫數字數據集,包含一個有着 60000 樣本的訓練集和一個有着 10000 樣本的測試集。對於在現實世界數據上嘗試學習技術和深度識別模式而言,這是一個非常好的數據庫,且無需花費過多時間和精力進行數據預處理。
大小:約 50 MB
數量:70000 張圖像,共分爲 10 個類別。
MS-COCO
COCO 是一個大型數據集,用於目標檢測、分割和標題生成。它有以下幾個特徵:
-
目標分割
-
在語境中識別
-
超像素物品分割
-
33 萬張圖像(其中超過 20 萬張是標註圖像)
-
150 萬個目標實例
-
80 個目標類別
-
91 個物品分類
-
每張圖像有 5 個標題
-
25 萬張帶有關鍵點的人像
大小:約 25 GB(壓縮後)
數量:33 萬張圖像、80 個目標類別、每張圖像 5 個標題、25 萬張帶有關鍵點的人像
ImageNet
mageNet 是根據 WordNet 層次來組織的圖像數據集。WordNet 包含大約 10 萬個短語,而 ImageNet 爲每個短語提供平均約 1000 張描述圖像。
大小:約 150 GB
數量:圖像的總數約爲 1,500,000;每一張圖像都具備多個邊界框和各自的類別標籤。
Open Images 數據集
Open Images 是一個包含近 900 萬個圖像 URL 的數據集。這些圖像使用包含數千個類別的圖像級標籤邊界框進行了標註。該數據集的訓練集包含 9,011,219 張圖像,驗證集包含 41,260 張圖像,測試集包含 125,436 張圖像。
大小:500GB(壓縮後)
數量:9,011,219 張圖像,帶有超過 5000 個標籤
VisualQA
VQA 是一個包含圖像開放式問題的數據集。這些問題的解答需要視覺和語言的理解。該數據集擁有下列有趣的特徵:
-
265,016 張圖像(COCO 和抽象場景)
-
每張圖像至少包含 3 個問題(平均有 5.4 個問題)
-
每個問題有 10 個正確答案
-
每個問題有 3 個看似合理(卻不太正確)的答案
-
自動評估指標
大小:25GB(壓縮後)
數量:265,016 張圖像,每張圖像至少 3 個問題,每個問題 10 個正確答案
街景門牌號數據集(SVHN)
這是一個現實世界數據集,用於開發目標檢測算法。它需要最少的數據預處理過程。它與 MNIST 數據集有些類似,但是有着更多的標註數據(超過 600,000 張圖像)。這些數據是從谷歌街景中的房屋門牌號中收集而來的。
大小:2.5GB
數量:6,30,420 張圖像,共 10 類
這篇論文中,日本京都大學提出了局部分佈式平滑度(LDS),一個關於統計模型平滑度的新理念。它可被用作正則化從而提升模型分佈的平滑度。該方法不僅在 MNIST 數據集上解決有監督和半監督學習任務時表現優異,而且在 SVHN 和 NORB 數據上,Test Error 分別取得了 24.63 和 9.88 的分值。以上證明了該方法在半監督學習任務上的表現明顯優於當前最佳結果。
CIFAR-10
該數據集也用於圖像分類。它由 10 個類別共計 60,000 張圖像組成(每個類在上圖中表示爲一行)。該數據集共有 50,000 張訓練集圖像和 10,000 個測試集圖像。數據集分爲 6 個部分——5 個訓練批和 1 個測試批。每批含有 10,000 張圖像。
大小:170MB
數量:60,000 張圖像,共 10 類
Fashion-MNIST
Fashion-MNIST 包含 60,000 個訓練集圖像和 10,000 個測試集圖像。它是一個類似 MNIST 的時尚產品數據庫。開發人員認爲 MNIST 的使用次數太多了,因此他們把這個數據集用作 MNIST 的直接替代品。每張圖像都以灰度顯示,並具備一個標籤(10 個類別之一)。
大小:30MB
數量:70,000 張圖像,共 10 類
自然語言處理
IMDB 電影評論數據集
該數據集對於電影愛好者而言非常贊。它用於二元情感分類,目前所含數據超過該領域其他數據集。除了訓練集評論樣本和測試集評論樣本之外,還有一些未標註數據可供使用。此外,該數據集還包括原始文本和預處理詞袋格式。
大小:80 MB
數量:訓練集和測試集各包含 25,000 個高度兩極化的電影評論
Twenty Newsgroups 數據集
顧名思義,該數據集涵蓋新聞組相關信息,包含從 20 個不同新聞組獲取的 20000 篇新聞組文檔彙編(每個新聞組選取 1000 篇)。這些文章有着典型的特徵,例如標題、導語。
大小:20MB
數量:來自 20 個新聞組的 20,000 篇報道
Sentiment140
Sentiment140 是一個用於情感分析的數據集。這個流行的數據集能讓你完美地開啓自然語言處理之旅。數據中的情緒已經被預先清空。最終的數據集具備以下六個特徵:
-
推文的情緒極性
-
推文的 ID
-
推文的日期
-
查詢
-
推特的用戶名
-
推文的文本
大小:80MB(壓縮後)
數量: 1,60,000 篇推文
WordNet
上文介紹 ImageNet 數據集時提到,WordNet 是一個大型英語 synset 數據庫。Synset 也就是同義詞組,每組描述的概念不同。WordNet 的結構讓它成爲 NLP 中非常有用的工具。
大小:10 MB
數量:117,000 個同義詞集,它們通過少量的「概念關係」與其他同義詞集相互關聯
Yelp 數據集
這是 Yelp 出於學習目的而發佈的開放數據集。它包含數百萬個用戶評論、商業屬性(businesses attribute)和來自多個大都市地區的超過 20 萬張照片。該數據集是全球範圍內非常常用的 NLP 挑戰賽數據集。
大小:2.66 GB JSON、2.9 GB SQL 和 7.5 GB 的照片(全部壓縮後)
數量:5,200,000 個評論、174,000 份商業屬性、200,000 張照片和 11 個大都市地區
Wikipedia Corpus
該數據集是維基百科全文的集合,包含來自超過 400 萬篇文章的將近 19 億單詞。你能逐單詞、逐短語、逐段地對其進行檢索,這使它成爲強大的 NLP 數據集。
大小:20 MB
數量:4,400,000 篇文章,包含 19 億單詞
Blog Authorship Corpus
該數據集包含從數千名博主那裏收集到的博客文章,這些數據從 blogger.com 中收集而來。每篇博客都以一個單獨的文件形式提供。每篇博客至少出現 200 個常用的英語單詞。
大小:300 MB
數量:681,288 篇博文,共計超過 1.4 億單詞。
歐洲語言機器翻譯數據集
該數據集包含四種歐洲語言的訓練數據,旨在改進當前的翻譯方法。你可以使用以下任意語言對:
-
法語 - 英語
-
西班牙語 - 英語
-
德語 - 英語
-
捷克語 - 英語
大小: 約 15 GB
數量:約 30,000,000 個句子及對應的譯文
音頻/語音數據集
Free Spoken Digit 數據集
這是本文又一個受 MNIST 數據集啓發而創建的數據集!該數據集旨在解決識別音頻樣本中口述數字的任務。這是一個公開數據集,所以希望隨着人們繼續提供數據,它會不斷髮展。目前,它具備以下特點:
-
3 種人聲
-
1500 段錄音(每個人口述 0- 9 各 50 次)
-
英語發音
大小: 10 MB
數量: 1500 個音頻樣本
Free Music Archive (FMA)
FMA 是音樂分析數據集,由整首 HQ 音頻、預計算的特徵,以及音軌和用戶級元數據組成。它是一個公開數據集,用於評估 MIR 中的多項任務。以下是該數據集包含的 csv 文件及其內容:
-
tracks.csv:記錄每首歌每個音軌的元數據,例如 ID、歌名、演唱者、流派、標籤和播放次數,共計 106,574 首歌。
-
genres.csv:記錄所有 163 種流派的 ID 與名稱及上層風格名(用於推斷流派層次和上層流派)。
-
features.csv:記錄用 librosa 提取的常見特徵。
-
echonest.csv:由 Echonest(現在的 Spotify)爲 13,129 首音軌的子集提供的音頻功能。
大小:約 1000 GB
數量:約 100,000 個音軌
Ballroom
該數據集包含舞廳的舞曲音頻文件。它以真實音頻格式提供了許多舞蹈風格的一些特徵片段。以下是該數據集的一些特點:
-
實例總數:698
-
單段時長:約 30 秒
-
總時長:約 20940 秒
大小:14 GB(壓縮後)
數量:約 700 個音頻樣本
Million Song 數據集
Million Song 數據集包含一百萬首當代流行音樂的音頻特徵和元數據,可免費獲取。其目的是:
-
鼓勵研究商業規模的算法
-
爲評估研究提供參考數據集
-
作爲使用 API 創建大型數據集的捷徑(例如 The Echo Nest API)
-
幫助入門級研究人員在 MIR 領域展開工作
數據集的核心是一百萬首歌曲的特徵分析和元數據。該數據集不包含任何音頻,只包含導出要素。示例音頻可通過哥倫比亞大學提供的代碼(https://github.com/tb2332/MSongsDB/tree/master/Tasks_Demos/Preview7digital)從 7digital 等服務中獲取。
大小:280 GB
數量:一百萬首歌曲!
LibriSpeech
該數據集是一個包含約 1000 小時英語語音的大型語料庫。數據來源爲 LibriVox 項目的音頻書籍。該數據集已經得到了合理地分割和對齊。如果你還在尋找起始點,那麼點擊 http://www.kaldi-asr.org/downloads/build/6/trunk/egs/查看在該數據集上訓練好的聲學模型,點擊 http://www.openslr.org/11/查看適合評估的語言模型。
大小:約 60 GB
數量:1000 小時的語音
VoxCeleb
VoxCeleb 是一個大型人聲識別數據集。它包含來自 YouTube 視頻的 1251 位名人的約 10 萬段語音。數據基本上是性別平衡的(男性佔 55%)。這些名人有不同的口音、職業和年齡。開發集和測試集之間沒有重疊。對大明星所說的話進行分類並識別——這是一項有趣的工作。
大小:150 MB
數量:1251 位名人的 100,000 條語音
推特情感分析數據集
涉及種族主義和性別歧視的偏激言論已成爲 Twitter 的難題,因此將這類推文與其它推文分開已十分重要。在這個實際問題中,我們提供的 Twitter 數據包含普通言論和偏激言論。作爲數據科學家,你的任務是確定哪些推文是偏激型推文,哪些不是。
大小: 3 MB
數量: 31,962 篇推文
印度演員年齡檢測數據集
對於深度學習愛好者來說,這是一個令人着迷的挑戰。該數據集包含數千名印度演員的圖像,你的任務是確定他們的年齡。所有圖像都由人工從視頻幀中挑選和剪切而來,這導致規模、姿勢、表情、亮度、年齡、分辨率、遮擋和妝容具有高度可變性。
大小:48 MB(壓縮後)
數量:訓練集中有 19,906 幅圖像,測試集中有 6636 幅圖像
城市聲音分類數據集
該數據集包含超過 8000 個來自 10 個類別的城市聲音片段。這個實際問題旨在向你介紹常見分類場景中的音頻處理。
大小:訓練集 - 3 GB(壓縮後)、測試集 - 2 GB(壓縮後)
數量:來自 10 個類別的 8732 個標註城市聲音片段(單個片段音頻時長 <= 4s)
轉貼自: 幫趣


留下你的回應
以訪客張貼回應