
摘要: 初步理解遷移學習、強化學習
一、深度學習及其適用範圍
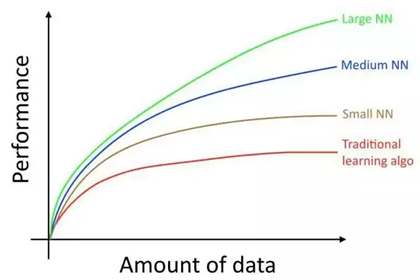
大數據造就了深度學習,通過大量的數據訓練,我們能夠輕易的發現數據的規律,從而實現基於監督學習的數據預測。
沒錯,這裡要強調的是基於監督學習的,也是迄今為止我在講完深度學習基礎所給出的知識範圍。
基於卷積神經網絡的深度學習(包括CNN、RNN),主要解決的領域是 圖像、文本、語音,問題聚焦在 分類、回歸。然而這裡並沒有提到推理,顯然我們用之前的這些知識無法造一個 AlphaGo 出來,通過一張圖來了解深度學習的問題域:
2016年的 NIPS 會議上,吳恩達 給出了一個未來 AI方向的技術發展圖,還是很客觀的:
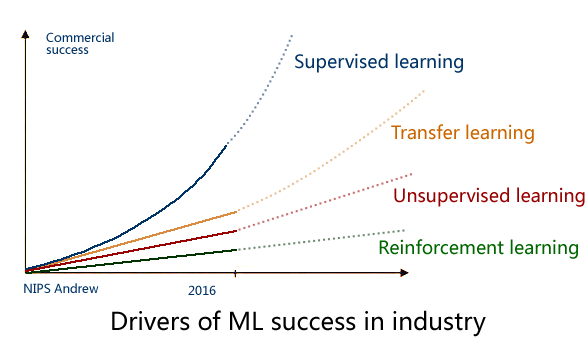
毋庸置疑,監督學習是目前成熟度最高的,可以說已經成功商用,而下一個商用的技術 將會是 遷移學習(Transfer Learning),這也是 Andrew 預測未來五年最有可能走向商用的 AI技術。
二、遷移學習(舉一反三的智能)
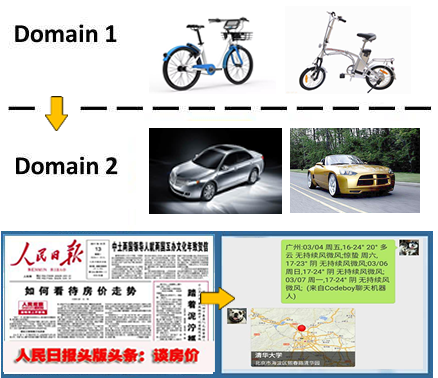
遷移學習解決的問題是 如何將學習到知識 從一個場景遷移到另一個場景?
拿圖像識別來說,從白天到晚上,從 Bottom View 到 Top View,從冬天到夏天,從識別中國人到 識別外國人……
這是一個普遍存在的問題,問題源自於你所關注的場景缺少足夠的數據來完成訓練,在這種情況下你需要 通過遷移學習來實現 模型本身的泛化能力。
用一張示意圖(From:A Survey on Transfer Learning)來進行說明:
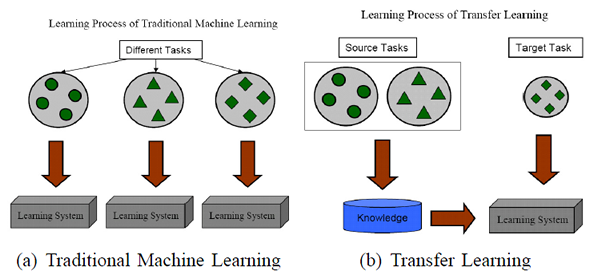
實際上,你可能在不知不覺中使用到了 遷移學習,比如所用到的預訓練模型,在此基礎所做的 Fine-Turning,再比如你做 Tracking 所用的 online learning。
遷移學習的必要性和價值體現在:
1. 重複用現有知識域數據,已有的大量工作不至於完全丟棄;
2. 不需要再去花費巨大代價去重新採集和標記龐大的新數據集,也有可能數據根本無法獲取;
3. 對於快速出現的新領域,能夠快速遷移和應用,體現時效性優勢;
關於遷移學習算法 有許多不同的思路,我們總結為:
1. 通過 原有數據 和 少量新領域數據混合訓練;
2. 將原訓練模型進行分割,保留基礎模型(數據)部分作為新領域的遷移基礎;
3. 通過三維仿真來得到新的場景圖像(OpenAI的Universe平台借助賽車遊戲來訓練);
4. 借助對抗網絡 GAN 進行遷移學習 的方法;
三、強化學習(反饋,修正)
強化學習全稱是Deep Reinforcement Learning(DRL),其所帶來的推理能力是智能的一個關鍵特徵衡量,真正的讓機器有了自我學習、自我思考的能力,毫無疑問Google DeepMind 是該領域的執牛耳者,其發表的DQN 堪稱是該領域的破冰之作。
目前強化學習主要用在遊戲AI 領域(有我們老生常談的AlphaGo)和機器人領域,除此之外,Google宣稱通過強化學習將數據中心的冷卻費用降低了40%,雖無法考證真偽,但我願意相信他的價值。
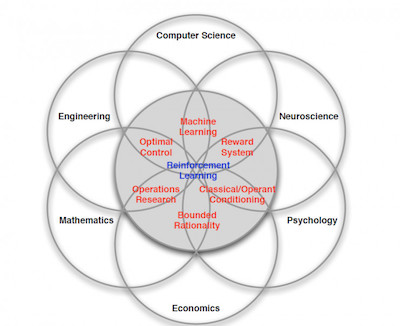
強化學習 是個複雜的命題,Deepmind 大神 David Silver 將其理解為這樣一種交叉學科:
實際上,強化學習是一種探索式的學習方法,通過不斷“試錯” 來得到改進,不同於監督學習的地方是強化學習本身沒有Label,每一步的Action 之後它無法得到明確的反饋(在這一點上,監督學習每一步都能進行Label 比對,得到True or False)。
強化學習是通過以下幾個元素來進行組合描述的:
1. 對象(Agent): 也就是我們的智能主題,比如 AlphaGo。
2. 環境(Environment): Agent 所處的場景-比如下圍棋的棋盤,以及其所對應的狀態(State)-比如當前所對應的棋局。 Agent 需要從 Environment 感知來獲取反饋(當前局勢對我是否更有利)。
3. 動作 (Actions) : 在每個State下,可以採取什麼行動,針對每一個 Action 分析其影響。
4. 獎勵 (Rewards) 執行 Action 之後,得到的獎勵或懲罰,Reward 是通過對 環境的觀察得到。
通過強化學習,我們得到的輸出就是:Next Action?下一步該怎麼走,這就是 AlphaGo 的棋局,你能夠想到,對應圍棋的 Action 數量嗎?
關於強化學習的具體算法,大多從 馬爾可夫鏈 講起,本節只做普及性說明
原文鏈接: CDSN
版权声明:本文為CSDN博主「linolzhang」的原創文章,遵循 CC 4.0 by-sa 版權協議,,轉載請附上原文出處鏈接及本聲明。
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應