
摘要: Rendezvous Architecture helps you run and choose outputs from a Champion model and many Challenger models running in parallel without many overheads. The original approach works well for smaller data sets, so how can this idea adapt to big data pipelines?

▲來源:kdnuggets.com
The Rendezvous architecture proposed by Ted Dunning and Ellen Friedman in their book on Machine Learning Logistics was a wonderful solution I found for a specific architectural problem I was working on. I was looking for a tried and tested design pattern or architectural pattern that helps me run Challenger and Champion models together in a maintainable and supportable way. The rendezvous architecture was significantly more useful in the big data world because you are dealing with heavy data and large pipelines.
The ability to run Challenger and Champion models together on all data is a very genuine need in machine learning, where the model performance can drift over time and where you want to keep improving on the performance of your models to something better always.
So, before I delve deeper into this architecture, I would like to clarify some of the jargon I have used above. What is a Champion model? What is a Challenger model? What is model drift, and why does it occur? Then, we can look at the rendezvous architecture itself and the problems it solves.
Model Drift
Once you put your model into production, assuming it will always perform well is a mistake. In fact, it is said - "The moment you put a model into production, it starts degrading." (Note, most often 'performance' in ML is used to mean statistical performance -- be it accuracy, precision, recall, sensitivity, specificity or whatever the appropriate metric is for your use case).
Why does this happen? The model is trained on some past data. It performs excellently for any data with the same characteristics. However, as time progresses, the actual data characteristics can keep changing, and the model is not aware of these changes at all. This causes model drift, i.e., degradation in model performance.
For example, you trained a model to detect spam mail versus ham mail. The model performs well when deployed. Over time, the types of spam keep morphing, and hence the accuracy of the prediction comes down. This is called model drift.
The model drift could happen because of a concept drift or a data drift. I am not getting into these today, so it will suffice us to understand that the performance of a model does not remain constant. Hence we need to continuously monitor the performance of a model. Most often, it is best to retrain the model with fresher data more frequently or probably based on a threshold level in performance degradation.
Sometimes, even retraining the model does not improve the performance further. This would imply that you might have to understand the changes in the characteristics of the problem and go through the whole process of data analysis, feature creation, and model building with more appropriate models.
This cycle can be shortened if you can work with Challenger models even while we have one model in production currently. This is a continuous improvement process of machine learning and is very much required.
Champion-Challenger Models
Typically, the model in production is called the Champion model. And any other model that seems to work well in your smaller trials and is ready for going into production is a Challenger model. These Challenger models have been proposed because we assume there is a chance that they perform better than the Champion model. But how do we prove it?
A Champion model typically runs on all the incoming data to provide the predictions. However, on what data does the Challenger model run?
There are two ways that the Challenger models can be tested. The ideal case would be to run the Challenger model in parallel with the Champion model on all data and compare the results. This would truly prove the Challenger model can perform better or not. However, this seems prohibitive, especially in the big data world, and hence the Challenger is always trialed out on a subset of the incoming data. Once that seems to perform well, it is gradually rolled out to more and more data, almost like alpha-beta testing.
As you might be aware, in alpha-beta testing, a small percentage of users or incoming data, in this case, is sent through a new test or Challenger pipeline, and the rest all go through the original Champion pipeline. This kind of alpha-beta testing is good for some applications but clearly not very impressive in the world of machine learning. You are not comparing the models on the same data and hence can rarely say with confidence that one is better than the other for the whole data. There could be lurking surprises once you roll it out for all data, and the model drift can start sooner than expected.
A typical alpha-beta pipeline would look like this:
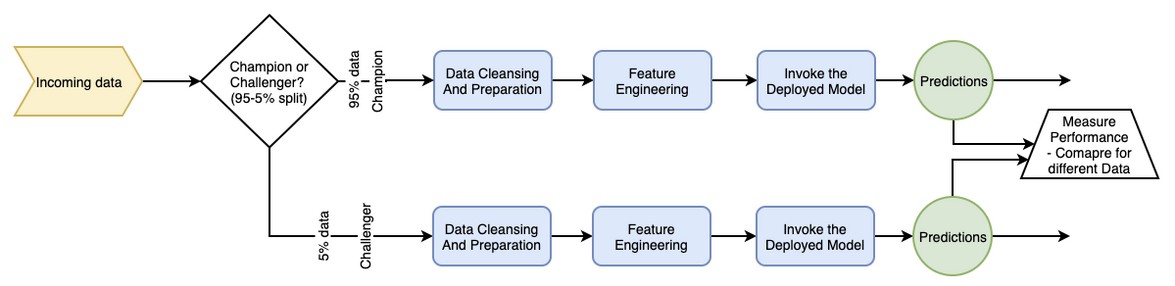
▲來源:kdnuggets.com
The data is split between the two pipelines based on some criteria, like the category of a product. This data split keeps increasing towards Challenger as the confidence in the performance of the Challenger model grows.
From a data scientist's perspective, this is not ideal. The ideal would be to be able to run the Challenger model in parallel for all the data along with the Champion model. As I earlier said, this is very expensive.
Consider the worst-case scenario. If you want them to run in parallel, you have to set up two data pipelines that run through all the steps independently.
It would look something like this:
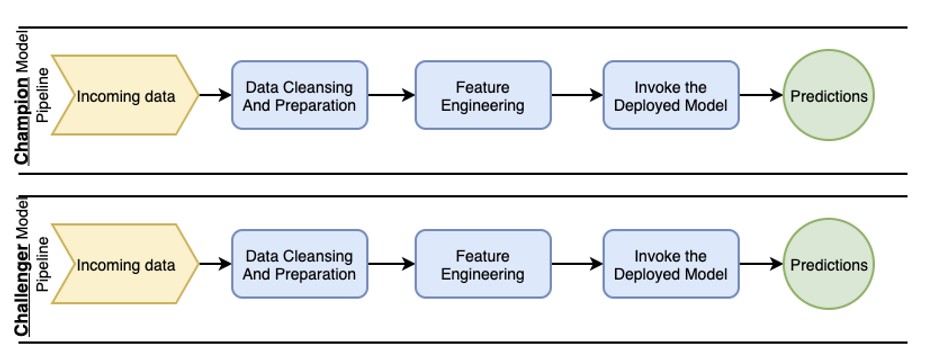
▲來源:kdnuggets.com
This has huge engineering implications and, hence, time to market implications. The cost of this can get prohibitive over time.
A few of the top implications are the time and effort in building these pipelines over and over again without being sure if the Challenger model is indeed going to perform as expected. The CI/CD process, the deployments, the monitoring, authentication mechanisms, etc., are a few to mention. In addition, the other cost is around the infrastructure that has to be doubly provisioned.
Considering if these pipelines are big data pipelines, it becomes all the more significant. Very soon, you realise that this is not a scalable model. We certainly have to see how we can move away from parallel pipelines or even from the alpha-beta testing method.
As a corollary, the best-case scenario would be when we can reuse much of the data pipelines. The idea is to minimize the amount one has to develop and deploy again into production. This would also ensure optimization of infrastructure usage. This is one line of thinking about how to optimize.
Even better would be to be able to just plug in the Challenger model, and the rest of the pipeline plays as if nothing has changed. Wouldn't that be fantastic? And this is what is made possible by the Rendezvous architecture.
Rendezvous Architecture
The Rendezvous architecture, as written in the book, is tilted towards ML with smaller data. I have tweaked it to meet the needs of the big data world and associated pipelines as shown in the diagram below: (References to the book and another article are given below in the references section)
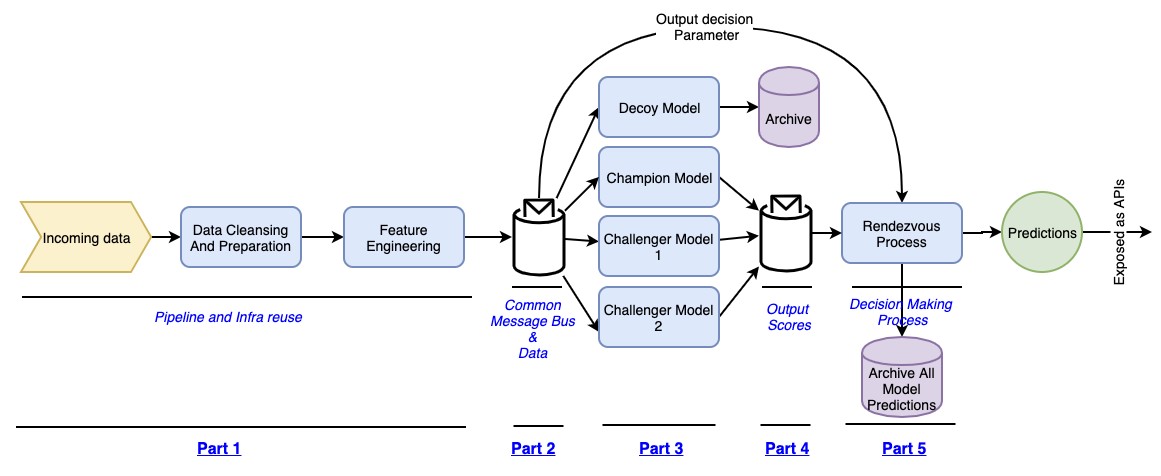
▲來源:kdnuggets.com
Let me now explain section by section of this architecture.
Part 1:
This consists of the standard data pipeline for receiving incoming data, cleansing it, preparing it, and creating the required features. This should be just one pipeline for every model that is to be deployed. The prepared data should maintain a standard interface that has all the features that may be required in that domain irrespective of the model on hand. (I understand this is not always possible and may need tweaking piecemeal over time. But we can deal with that piece in isolation when required.)
Part 2:
This is a messaging infrastructure like Kafka that comes into play by bringing in the sense of asynchronicity. The data that is prepared as features are published onto the message bus. Now, every model listens to this message bus and triggers off, executing itself with the prepared data. This message bus is what enables a plug-and-play architecture here.
Part 3:
This is the part where all models are deployed one by one. A new Challenger model can be deployed and made to listen to the message bus, and as data flows in, it can execute. Any number of models can be deployed here and not just one Challenger model! Also, the infra requirement is only for the extra model to run. Neither the pre-model pipelines nor the post-model pipelines need to be separately developed or deployed.
As you can see in the figure, you can have many challenger models as long as the data scientist sees them mature enough to be tested against real data.
Also, there is a special model called the decoy model. In order to ensure that each of the model processes is not burdened with persistence, the prepared data is also read by what is called a decoy model, whose only job is to read the prepared data and persist. This helps for audit purposes, tracing, and debugging when required.
Part 4:
All these models again output their predictions or scores into another message bus, thus not bringing any dependency between themselves. Also, again this plays an important role in ensuring the pluggability of a model without disrupting anything else in the pipeline.
From there, the rendezvous process picks up the scores and decides what needs to be done, as described in Part 5.
Part 5:
This is where the new concept of a Rendezvous process is introduced, which has two important sub-processes. One immediate subprocess takes care of streaming out the correct output from the pipeline for a consumer from among the many scores it has received, and the other process is to persist the output from all models for further comparison and analysis.
So, we have achieved two things here:
- The best output is provided to the consumer.
- All the data has gone through all the models, and hence they are totally comparable in like circumstances on their performance.
How does it decide which model's output should be sent out? This can be based on multiple criteria like a subset of data should always be from Challenger, and another subset should always be from Champion. This is almost like achieving the alpha-beta testing. However, the advantage here is that while it sounds like alpha-beta testing for a consumer, for the data scientist, all data has been through both the models and so they can compare the two outputs and understand which is performing better.
Another criterion could be that the output should be based on model performance. In this case, the rendezvous process waits for all models to complete and publish to the message bus. Then, it seeks the best performance metric and sends out that as the result.
Yes, another criterion can be that of time or latency. If we need to have the result in, say, less than 5 seconds, for example, the process waits for all the results from models, up to 5 seconds, compares only those, and returns the best data. Even though another model comes back in the 6th second that may have performed much better, that is ignored as it does not meet the latency criteria.
But how does this process know what is the criteria to follow for which data or which model? This can be put in as part of the input data into the message bus in Part 2. Note that the Rendezvous process is also listening to these messages and gets to know what to do with the output that corresponds to an input. There could be other clever ways too, but this is one of the ways proposed.
Conclusion
By introducing asynchronicity through message buses, a level of decoupling has been introduced, bringing in the ability to plug-and-play models into an otherwise rigid data pipeline.
By introducing the rendezvous process, the ability to select between various model outputs, persist them, compare them were all introduced. And with this, it now does not seem a herculean task to introduce or support any number of new models for the same data set.
Summary
The rendezvous architecture gives great flexibility at various levels.
- A variety of criteria can be used to decide what score, output, or prediction can be sent out of the prediction process. These criteria could be latency-based, model performance-based, or simple time-based.
- It provides the ability to define and change these criteria dynamically through the rendezvous process. You can take it to another level by introducing a rule engine here.
- It provides the ability to make all the data go through all the pipelines or choose only a subset to go through many pipelines. For example, if you have grocery and general merchandising products for which you are forecasting, groceries could go through their own Champion and Challenger models, while general merchandise, which are typically slow sellers, can have their own pipelines.
- It also provides the ability to run many models at a time without redeveloping or redeploying a large part of a big data pipeline. Apart from effort and time savings, the infrastructure costs are also optimised.
By Sai Geetha, an expert in Big Data Engineering and Data Science.
轉貼自Source: kdnuggets.com
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應