
摘要: Human-in-the-loop machine learning takes advantage of human feedback to eliminate errors in training data and improve the accuracy of models.

▲圖片來源:Thinkstock
Machine learning models are often far from perfect. When using model predictions for purposes that affect people’s lives, such as loan approval classification, it’s advisable for a human to review at least some of the predictions: those that have low confidence, those that are out of range, and a random sample for quality control.
In addition, the lack of good tagged (annotated) data often makes supervised learning hard to bootstrap (unless you’re a professor with idle grad students, as the joke goes). One way to implement semi-supervised learning from untagged data is to have humans tag some data to seed a model, apply the high-confidence predictions of an interim model (or a transfer-learning model) to tag more data (auto-labeling), and send low-confidence predictions for human review (active learning). This process can be iterated, and in practice tends to improve from pass to pass.
In a nutshell, human-in-the-loop machine learning relies on human feedback to improve the quality of the data used to train machine learning models. In general, a human-in-the-loop machine learning process involves sampling good data for humans to label (annotation), using that data to train a model, and using that model to sample more data for annotation. A number of services are available to manage this process.
Amazon SageMaker Ground Truth
Amazon SageMaker provides two data labeling services, Amazon SageMaker Ground Truth Plus and Amazon SageMaker Ground Truth. Both options allow you to identify raw data, such as images, text files, and videos, and add informative labels to create high-quality training datasets for your machine learning models. In Ground Truth Plus, Amazon experts set up your data labeling workflows on your behalf, and the process applies pre-learning and machine validation of human labeling.
Amazon Augmented AI
While Amazon SageMaker Ground Truth handles initial data labeling, Amazon Augmented AI (Amazon A2I) provides human review of low-confidence predictions or random prediction samples from deployed models. Augmented AI manages both review workflow creation and the human reviewers. It integrates with AWS AI and machine learning services in addition to models deployed to an Amazon SageMaker endpoint.
DataRobot human-in-the-loop
DataRobot has a Humble AI feature that allows you to set rules to detect uncertain predictions, outlying inputs, and low observation regions. These rules can trigger three possible actions: no operation (just monitor); override the prediction (typically with a “safe” value); or return an error (discard the prediction). DataRobot has written papers about human-in-the-loop, but I find no implementation on their site other than the humility rules.
Google Cloud Human-in-the-Loop
Google Cloud offers Human-in-the-Loop (HITL) processing integrated with its Document AI service, but as if this writing, nothing for image or video processing. Currently, Google supports the HITL review workflow for the following processors:
Procurement processors:
- Invoices
- Receipts
Lending processors:
- 1003 Parser
- 1040 Parser
- 1040 Schedule C Parser
- 1040 Schedule E Parser
- 1099-DIV Parser
- 1099-G Parser
- 1099-INT Parser
- 1099-MISC Parser
- Bank Statement Parser
- HOA Statement Parser
- Mortgage Statement Parser
- Pay Slip Parser
- Retirement/Investment Statement Parser
- W2 Parser
- W9 Parser
Human-in-the-loop software
Human image annotation, such as image classification, object detection, and semantic segmentation, can be hard to set up for dataset labelling. Fortunately, there are many good open source and commercial tools that taggers can use.
Humans in the Loop, a company that describes itself as “a social enterprise which provides ethical human-in-the-loop workforce solutions to power the AI industry,” blogs periodically about their favorite annotation tools. In the latest of these blog posts, they list 10 open source annotation tools for computer vision: Label Studio, Diffgram, LabelImg, CVAT, ImageTagger, LabelMe, VIA, Make Sense, COCO Annotator, and DataTurks. These tools are mostly used for initial training set annotation, and some can manage teams of annotators.
To pick one of these annotation tools as an example, the Computer Vision Annotation Tool (CVAT) “has very powerful and up-to-date features and functionalities and runs in Chrome. It still is among the main tools that both we and our clients use for labeling, given that it’s much faster than many of the available tools on the market.”
The CVAT README on GitHub says “CVAT is a free, online, interactive video and image annotation tool for computer vision. It is being used by our team to annotate millions of objects with different properties. Many UI and UX decisions are based on feedback from professional data annotation teams. Try it online at cvat.org.” Note that you need to create a login to run the demo.
CVAT was released to open source under the MIT license. Most of the active committers work for Intel in Nizhny Novgorod, Russia. To see a run-through of the tagging process, watch the CVAT intro video.
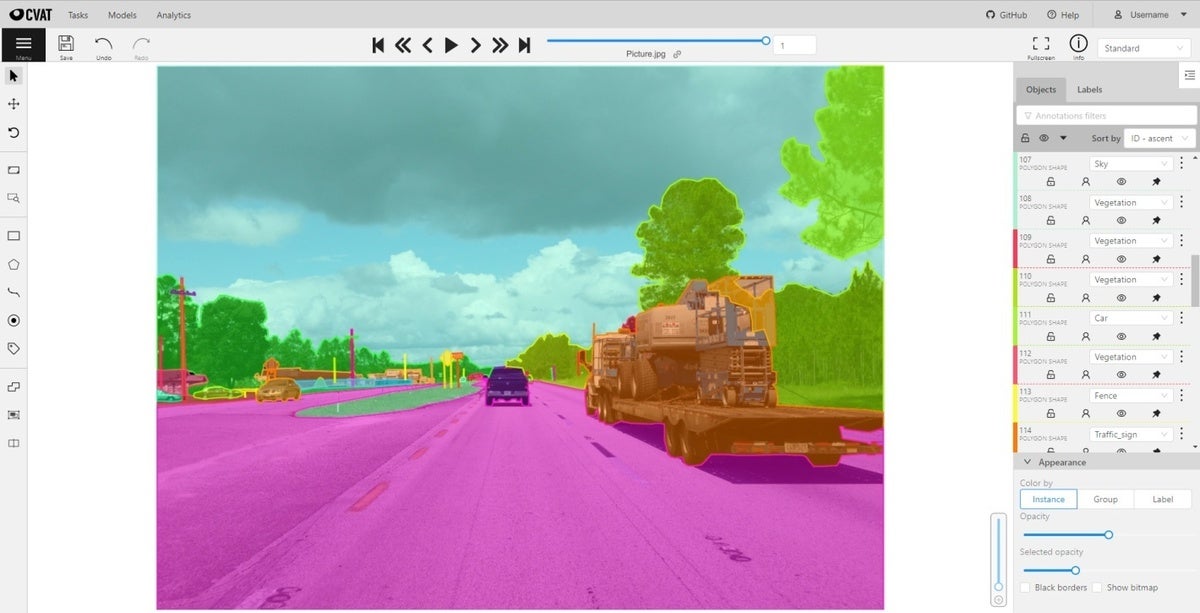
As we’ve seen, human-in-the-loop processing can contribute to the machine learning process at two points: the initial creation of tagged datasets for supervised learning, and the review and correction of possibly problematic predictions when running the model. The first use case helps you bootstrap the model, and the second helps you tune the model.
轉貼自Source: infoworld.com
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應