
摘要: Is machine learning killing the planet? Probably not, but let's make sure it doesn't.
Machine learning (ML) often mimics how human brains operate by attaching virtual neurons with virtual synapses. Deep learning (DL) is a subset of ML putting steroids into the virtual brain and growing it orders of magnitude larger. This neuron count has skyrocketed hand-in-hand with the advances in computational power. Most headlines about ML solving hard problems like self-driving cars or facial recognition use DL, but the steroids come with a cost. Increasing the model size increases computational cost, which correlates with energy cost, leading to a larger carbon footprint.
Global warming is arguably the most critical problem our generation has to solve in the following years. It is a polarizing topic that can generate a lot of emotion, which is fantastic. This emotional component is a prerequisite for solving our society's most challenging problem but, unfortunately, also a prime target for clickbaity headlines and misinformation.
In 2019, the University of Massachusetts Amherst scholars studied the energy cost and carbon footprint of some of the state-of-the-art DL models. The paper reported dizzying greenhouse gas emissions and rightfully elevated the discussion around the carbon emissions of ML. Other scientists and science journalists picked it up, and the report has been quoted time and time again in thousands of studies and news articles in the past three years.
Scholars at MIT extrapolated the original paper in their famous article "Deep Learning's Diminishing Returns." It anticipated that beating the accuracy of the current models would be based on increasing the model size the same way as it has been in the past. The authors predicted that a single state-of-the-art model would soon cost $100 billion to train and produce as much carbon emissions as New York City in a month. They did not believe it would ever happen, as spending $100 billion on a model in 2025 would be absurd even with the current inflation climate, but this didn't stop the emotional impact on the readers. Machine learning would be killing the planet!
The controversy caused Google and the University of California, Berkeley scholars to launch an investigation in cooperation with the authors of the original 2019 paper. The team revisited the estimates in the original paper and ultimately concluded that they were inaccurate. The ML footprint is smaller than we thought, and there is a reason for being cautiously optimistic about the future, too.
The problem with the original paper was creating estimates on top of estimates. ML studies generally only report the benefits and are silent about costs. Extrapolating over multiple inaccurate assumptions can accumulate into exponential errors in the final results, which is what happened. In the 2019 paper, the authors assumed legacy hardware, an average US data center efficiency, and misunderstood how neural architecture search (NAS) was used. The 2022 investigation revealed that the latest tensor processing units (TPUv2) were much more efficient, a highly efficient hyperscale data center was used, and NAS employed tiny models as a proxy. With these combined, the magnitude of error in the original paper was 88x.
The 2022 paper also outlines best practices to make sure we don't kill the planet in the future. There is no silver bullet, but optimizing the hardware for ML, innovating on sparse models with better "neural topology," and allowing customers to pick the geographical location where the greenest computation is will be the key. They argue that using these methodologies between 2017-2021 has already reduced the carbon footprint of training the famous Transformer NLP model by a staggering 747x or 99.998%. It doesn't mean that the problem is forever solved as the models keep growing, but it gives a more balanced outlook.
The fundamental insight is not to estimate but measure. Wild extrapolations can raise awareness, but one needs a reliable metric to solve the problem. While the largest cloud providers have released tools to reveal the overall carbon footprint, having an accurate picture of the climate impact of ML operations requires a cloud-agnostic tool, like an MLOps platform.
▲圖片來源:kdnuggets
"Everyone should worry about the carbon footprint, but make sure to measure it correctly first," CEO Eero Laaksonen from Valohai says. Valohai is a cloud-agnostic MLOps platform sitting in the layer between the cloud providers and the data scientists. The problem with the cloud is that companies lock themselves into a single cloud provider. The engineers write code for a single target, and "flipping the cloud" becomes impossible. Valohai abstracts the cloud provider, and spreading computation across different targets becomes a one-click operation. "Once you have a reliable metric, make sure you can react to it," says Laaksonen. "You spread the computation across multiple providers, choosing the greenest one depending on the task," he adds.
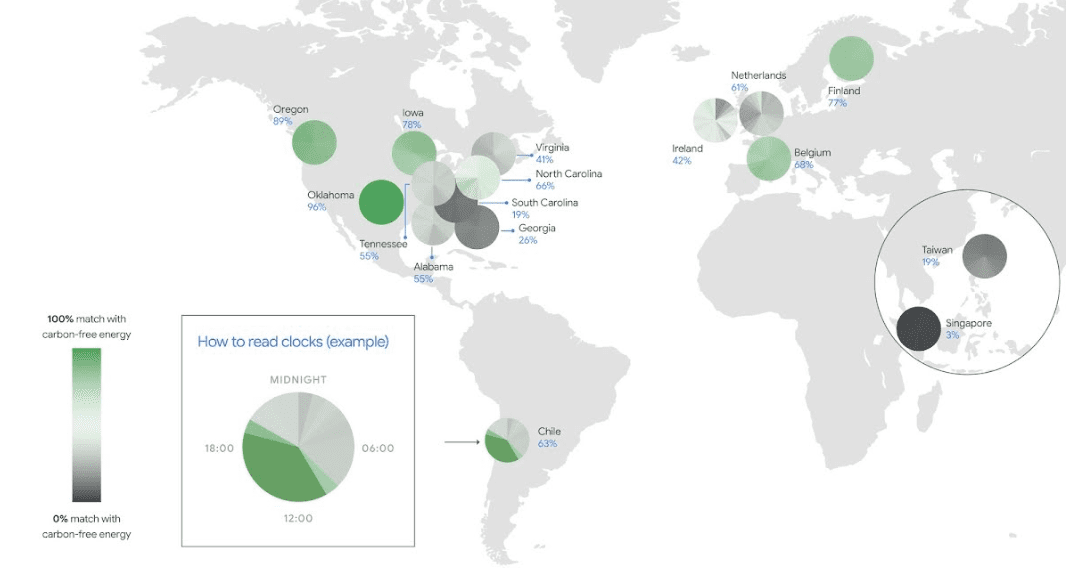
ML and DL models may keep growing in size, but the future is brighter and greener than it may seem by reading the headlines. Advancements in hardware and data science will hopefully offset the increased costs, and big cloud providers like Google are committed to operating on 100% carbon-free energy by 2030. In the meantime, let's keep our heads cool and our metrics sharp.
轉貼自: kdnuggets.com
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應