
摘要: 近日,Mate Labs 聯合創始人兼 CTO 在 Medium 上撰文《Everything you need to know about Neural Networks》,從神經元到 Epoch,扼要介紹了神經網絡的主要核心術語。
入門 | 瞭解神經網絡,你需要知道的名詞都在這裏
近日,Mate Labs 聯合創始人兼 CTO 在 Medium 上撰文《Everything you need to know about Neural Networks》,從神經元到 Epoch,扼要介紹了神經網絡的主要核心術語。
理解什麼是人工智能,以及機器學習和深度學習如何影響它,是一種不同凡響的體驗。在 Mate Labs 我們有一羣自學有成的工程師,希望本文能夠分享一些學習的經驗和捷徑,幫助機器學習入門者理解一些核心術語的意義。
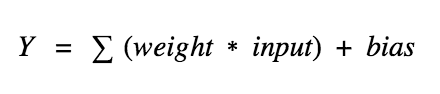
神經元(節點)—神經網絡的基本單元,它包括特定數量的輸入和一個偏置值。當一個信號(值)輸入,它乘以一個權重值。如果一個神經元有 4 個輸入,則有 4 個可在訓練中調節的權重值。
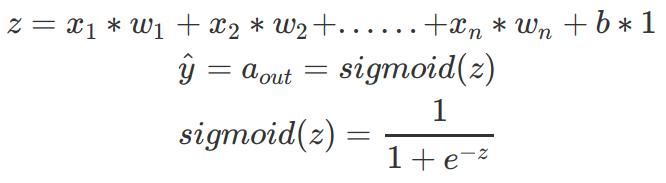
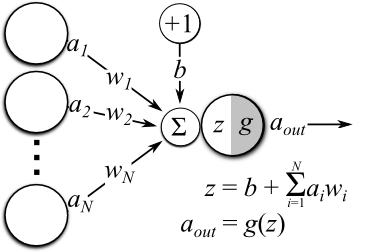
神經網絡中一個神經元的運算
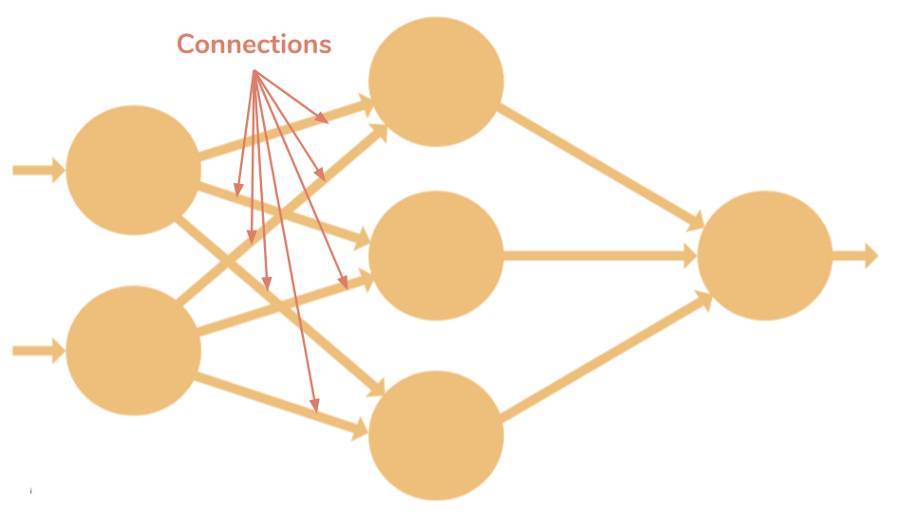
連接—它負責連接同層或兩層之間的神經元,一個連接總是帶有一個權重值。訓練的目標是更新這一權重值以降低損失(誤差)。
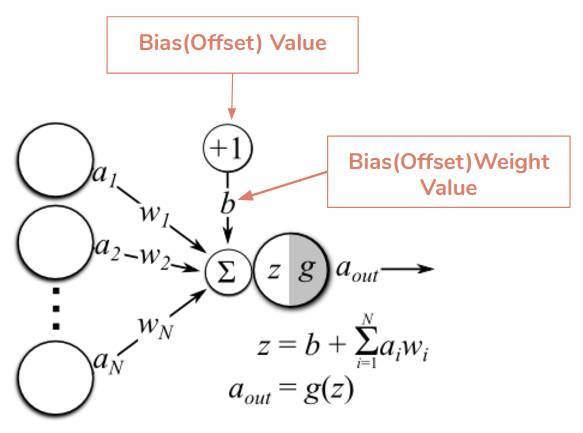
偏置(Offset)—它是神經元的額外輸入,值總是 1,並有自己的連接權重。這確保即使當所有輸入爲 0 時,神經元中也存在一個激活函數。
激活函數(遷移函數)—激活函數負責爲神經網絡引入非線性特徵。它把值壓縮到一個更小範圍,即一個 Sigmoid 激活函數的值區間爲 [0,1]。深度學習中有很多激活函數,ReLU、SeLU 、TanH 較 Sigmoid 更爲常用。更多激活函數,請參見《一文概覽深度學習中的激活函數》。
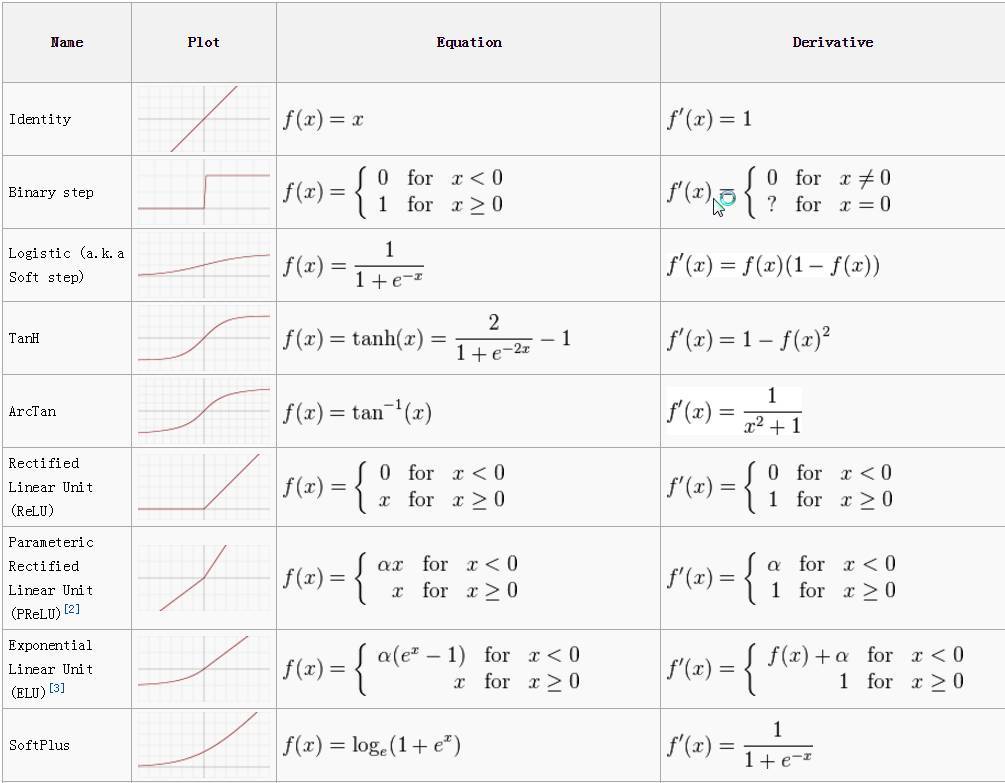
各種激活函數
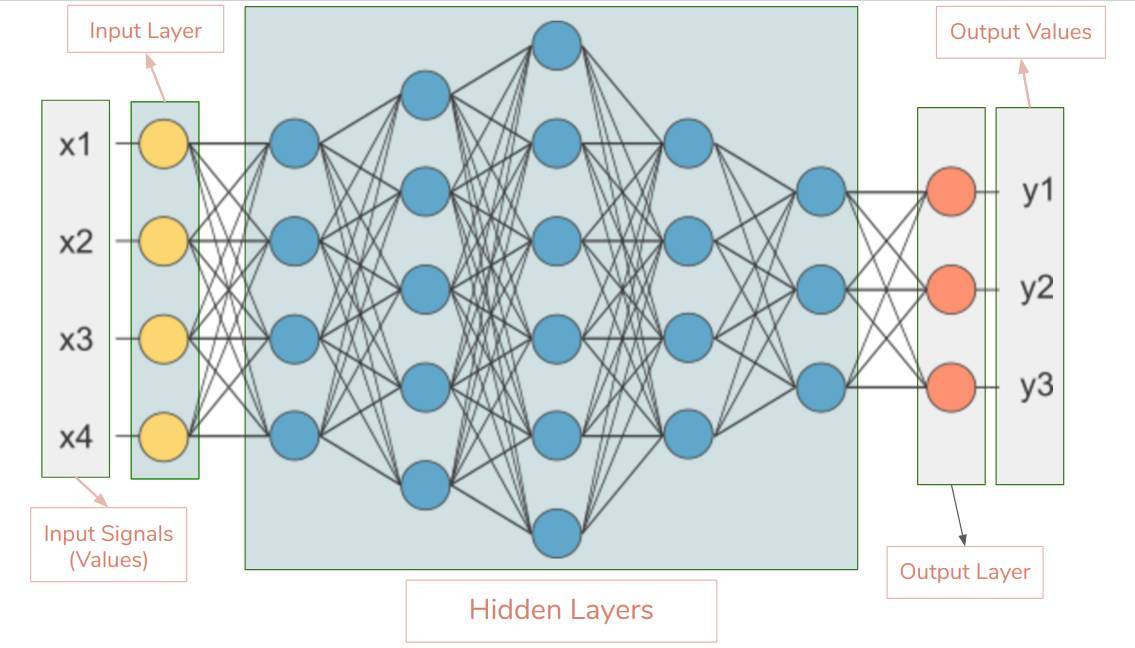
基本的神經網絡設計
輸入層—神經網絡的第一層。它接收輸入信號(值)並將其傳遞至下一層,但不對輸入信號(值)執行任何運算。它沒有自己的權重值和偏置值。我們的網絡中有 4 個輸入信號 x1、x2、x3、x4。
隱藏層—隱藏層的神經元(節點)通過不同方式轉換輸入數據。一個隱藏層是一個垂直堆棧的神經元集。下面的圖像有 5 個隱藏層,第 1 個隱藏層有 4 個神經元(節點),第 2 個 5 個神經元,第 3 個 6 個神經元,第 4 個 4 個神經元,第 5 個 3 個神經元。最後一個隱藏層把值傳遞給輸出層。隱藏層中所有的神經元彼此連接,下一層的每個神經元也是同樣情況,從而我們得到一個全連接的隱藏層。
輸出層—它是神經網絡的最後一層,接收來自最後一個隱藏層的輸入。通過它我們可以得到合理範圍內的理想數值。該神經網絡的輸出層有 3 個神經元,分別輸出 y1、y2、y3。
輸入形狀—它是我們傳遞到輸入層的輸入矩陣的形狀。我們的神經網絡的輸入層有 4 個神經元,它預計 1 個樣本中的 4 個值。該網絡的理想輸入形狀是 (1, 4, 1),如果我們一次饋送它一個樣本。如果我們饋送 100 個樣本,輸入形狀將是 (100, 4, 1)。不同的庫預計有不同格式的形狀。
權重(參數)—權重表徵不同單元之間連接的強度。如果從節點 1 到節點 2 的權重有較大量級,即意味着神將元 1 對神經元 2 有較大的影響力。一個權重降低了輸入值的重要性。權重近於 0 意味着改變這一輸入將不會改變輸出。負權重意味着增加這一輸入將會降低輸出。權重決定着輸入對輸出的影響力。
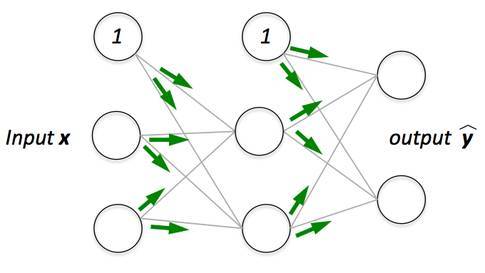
前向傳播
前向傳播—它是把輸入值饋送至神經網絡的過程,並獲得一個我們稱之爲預測值的輸出。有時我們也把前向傳播稱爲推斷。當我們饋送輸入值到神經網絡的第一層時,它不執行任何運算。第二層接收第一層的值,接着執行乘法、加法和激活運算,然後傳遞至下一層。後續的層重複相同過程,最後我們從最後一層獲得輸出值。
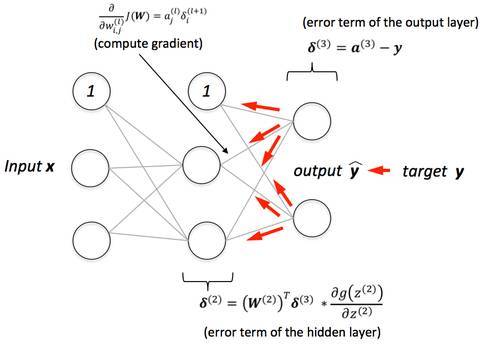
反向傳播
反向傳播—前向傳播之後我們得到一個輸出值,即預測值。爲了計算誤差我們對比了帶有真實輸出值的預測值。我們使用一個損失函數(下文提及)計算誤差值。接着我們計算每個誤差值的導數和神經網絡的每個權重。反向傳播運用微分學中的鏈式法則,在其中我們首先計算最後一層中每個誤差值的導數。我們調用這些導數、梯度,並使用這些梯度值計算倒數第二層的梯度,並重復這一過程直到獲得梯度以及每個權重。接着我們從權重值中減去這一梯度值以降低誤差。通過這種方式我們不斷接近局部最小值(即最小損失)。
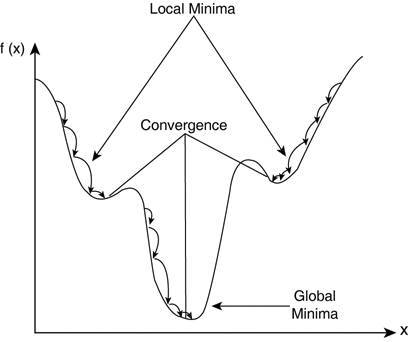
學習率—訓練神經網絡的時候通常會使用梯度下降優化權重。在每一次迭代中使用反向傳播計算損失函數對每一個權重的導數,並從當前權重減去導數和學習率的乘積。學習率決定了更新權重(參數)值的快慢。學習率應該儘可能高而不會花費太多時間達到收斂,也應該儘可能低從而能找到局部最優。
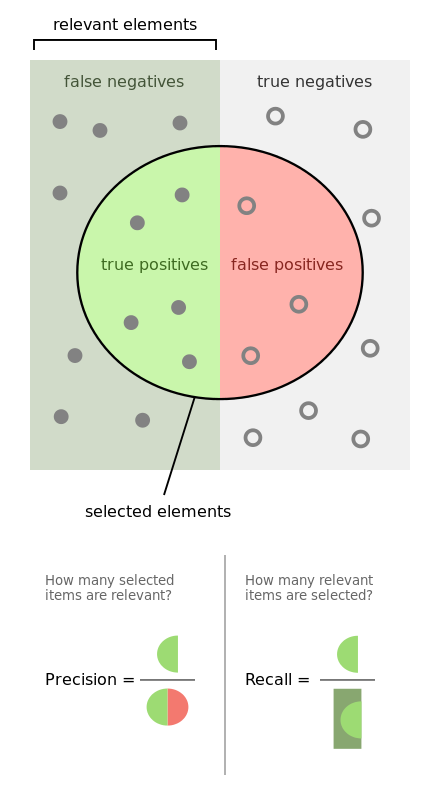
精度和召回率
準確率—測量值對標準(或已知)值的接近程度。
精度—兩個測量值之間的接近程度,表示測量的可重複性或可再現性。
召回率(敏感度)

Tp 指真正,Tn 指真負,Fp 指假正,Fn 指假負。
混淆矩陣—維基百科的解釋是:
機器學習領域和統計分類問題中,混淆矩陣(也稱爲誤差矩陣/error matrix)是一個算法性能的可視化表格,通常在監督學習中使用(無監督學習中混淆矩陣通常稱爲匹配矩陣,/matching matrix)。矩陣的每一行表示一個預測類,每一列表示一個真實類(或相反)。使用真實的名詞使其易於解讀,能簡單地看出系統對兩個類別的混淆程度(即將一個類別的物體標記爲另一個)。
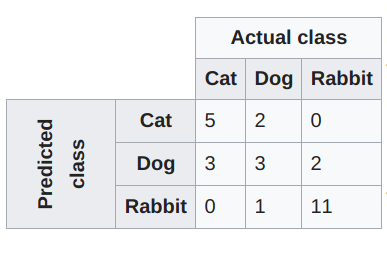
混淆矩陣
收斂—隨着迭代次數增加,輸出越來越接近具體的值。
正則化—用於克服過擬合問題。正則化過程中通過添加一個 L1(LASSO)或 L2(Ridge)規範到權重向量 w(通過給定算法學習到的參數)上以「懲罰」損失項:
L(損失函數)+λN(w)—這裏的λ是正則項,N(w)是 L1 或 L2 規範。
歸一化—數據歸一化是將一個或多個屬性縮放至 0 到 1 的範圍的過程。當不知道數據分佈或分佈不是高斯分佈(鐘形曲線)()的時候,歸一化是很有用的,可加速學習過程。
全連接層—一個層所有的節點的激活函數值作爲下一層的每個節點的輸入,若這對所有的層都成立,則稱這些層爲全連接層。
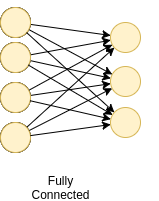
全連接層
損失函數/代價函數—損失函數計算單個訓練樣本的誤差,代價函數是整個訓練集的損失函數的平均。
-
「mse」—平均方差
-
「binary_crossentropy」—二分類對數損失(logloss)
-
「categorical_crossentropy」—多分類對數損失(logloss)
模型優化器—優化器是一種搜索技術,用於更新模型的權重。
-
SGD—隨機梯度下降,支持動量算法。
-
RMSprop—適應性學習率優化方法,由 Geoff Hinton 提出。
-
Adam—適應性矩估計(Adam)並同樣使用了適應性學習率。
性能指標—用於測量神經網絡性能的指標,例如,準確率、損失、驗證準確率、驗證損失、平均絕對誤差、精度、召回率和 f1 分數等等。
批大小—一次前向/反向傳播中適用的樣本數,批大小越大,佔用的內存量越大。
訓練 epochs—模型在訓練數據集上重複訓練的總次數。
一個 epoch= 全部訓練實例的一次前向和一次反向傳播。
原文鏈接:https://medium.com/@matelabs_ai/everything-you-need-to-know-about-neural-networks-8988c3ee4491
轉貼自: 幫趣

留下你的回應
以訪客張貼回應