
摘要: 部署Hadoop時,存儲擴展可能很困難且成本高昂,因為存儲和計算位於同一硬件節點上。通過使用S3兼容存儲軟件並使用S3連接器而不是HDFS來實現存儲層,可以獨立地分離存儲,計算和擴展存儲。這提供了更大的靈活性和成本效益,但提出了性能如何受到影響的問題。
部署Hadoop時,存儲擴展可能很困難且成本高昂,因為存儲和計算位於同一硬件節點上。通過使用S3兼容存儲軟件並使用S3連接器而不是HDFS來實現存儲層,可以獨立地分離存儲,計算和擴展存儲。這提供了更大的靈活性和成本效益,但提出了性能如何受到影響的問題。
作者們(Gary Ogasawara and Tatsuya Kawano)最近領導了一個項目,通過檢查查詢類型和存儲類型的四種不同組合的性能來回答這個問題:
1.Hive+HDFS
2.Hive+S3 (Cloudian HyperStore)
3.Presto+HDFS
4.Presto+S3 (Cloudian HyperStore)
他們使用HiBench的SQL(Hive-QL)工作負載,大約1100萬條記錄(~1.8GB)和TPC-H基準測試,大約8.66億條記錄(~100GB)。 CDH5(Cloudera Distribution Hadoop v5.14.4)用於Hadoop和HDFS實現。對於S3兼容存儲,我們使用Cloudian HyperStore v7.1在可以部署在Linux上的軟件包中實現Amazon S3 API。
匯總基準測試結果,從最佳到最差的相對表現為:
1.Presto+HDFS (best)
2.Presto+S3
3.Hive+HDFS
Hive+S3 (worst)
兩種Presto配置都大約比兩種Hive配置好10倍,此外,Presto+S3組合和最佳的Presto+ HDFS顯示出非常接近的性能結果,所以Hadoop的用戶,可以實現與S3存儲和軟件分開計算的靈活性和成本優勢,在性能上沒有任何顯著的權衡。
本文的其餘部分將更詳細地介紹四種配置中的每一種的基本數據流,性能基準和結果。
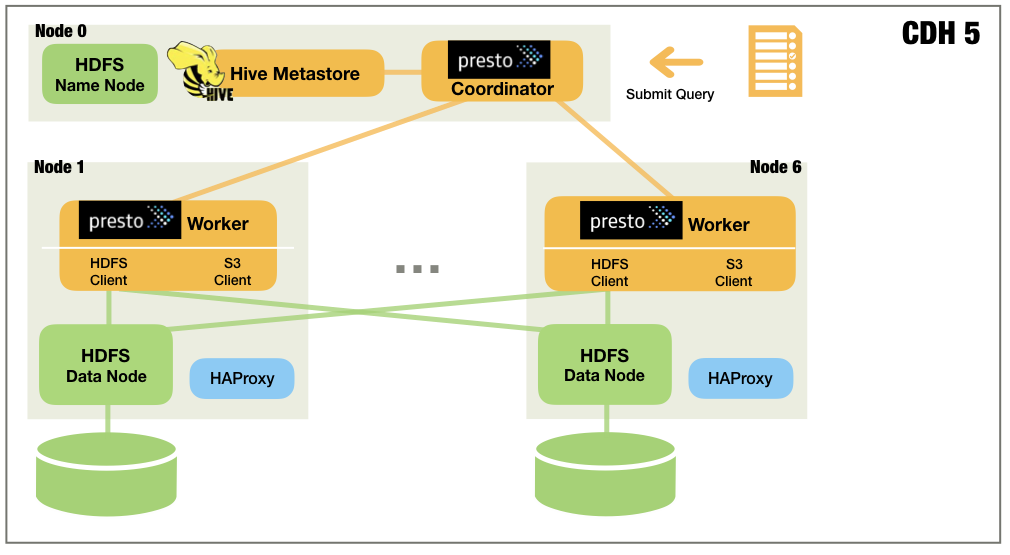
case1:基本數據流

1.輸入和輸出的Hive表存儲在HDFS上。 (此時輸出表應為空值)
2.HiBench或TPC-H查詢從節點0上的Hive客戶端提交到同一節點上的HiveServer2。
3.Hive從其Metastore中定位表,並為查詢調度一系列MapReduce(M/R)作業。 (Hive將每個工作稱為“階段”)
4.Hadoop YARN(未在圖中顯示)運行M / R作業中的任務。每個任務都有一個嵌入式HDFS客戶端,並在HDFS上讀/寫數據。中間結果存儲在HDFS上。
5.當所有階段完成後,Hive會將查詢結果返回給客戶端。
case2:Hive+S3
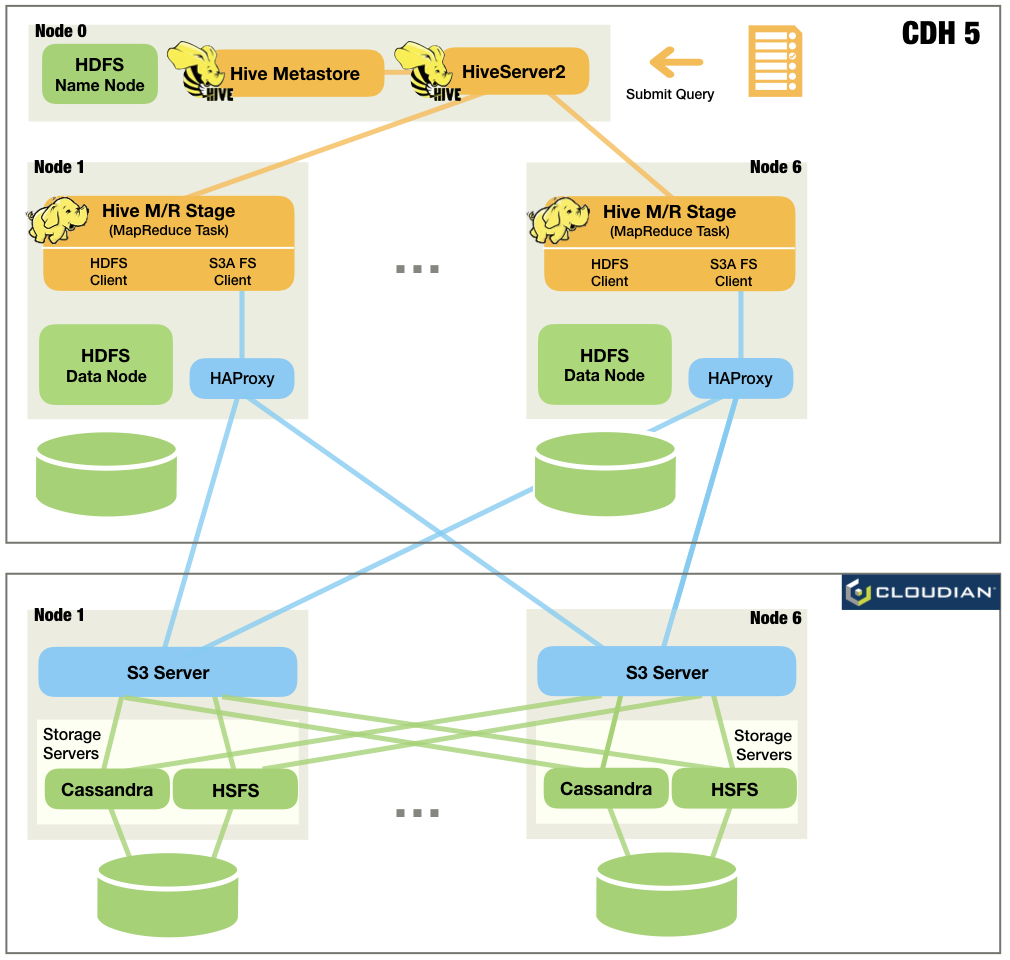
1.輸入和輸出的Hive表存儲在S3上。 (此時輸出表應為空值)
2.HiBench或TPC-H查詢從節點0上的Hive客戶端提交到同一節點上的HiveServer2。
3.Hive從其Metastore中查找表,並為查詢計劃一系列M/R作業。
4.Hadoop YARN在M / R作業中運行任務。每個任務都嵌入了S3A文件系統客戶端,並在HyperStore S3上讀/寫數據。 HAProxy用作循環負載平衡器,將S3請求轉發到不同的S3服務器。中間結果存儲在默認的分佈式文件系統實例上,對於作者的案例就是HDFS。
5.當所有階段完成後,Hive會將查詢結果返回給客戶端。
case3:Presto+HDFS
1.輸入和輸出的Hive表存儲在HDFS上。 (此時輸出表應為空值)
2.HiBench或TPC-H查詢從節點0上的Presto客戶端提交到同一節點上的Presto協調器。
3.Presto Coordinator詢問Hive Metastore以找到Hive表。
4.Presto Coordinator為查詢安排一系列任務。
5.Presto Workers使用其嵌入式HDFS客戶端執行任務,在HDFS上讀取/寫入數據。中間結果保存在內存中並在Presto Workers之間流式傳輸。
6.完成所有任務後,Presto Coordinator會將查詢結果返回給客戶端。
Case 4: Presto+S3
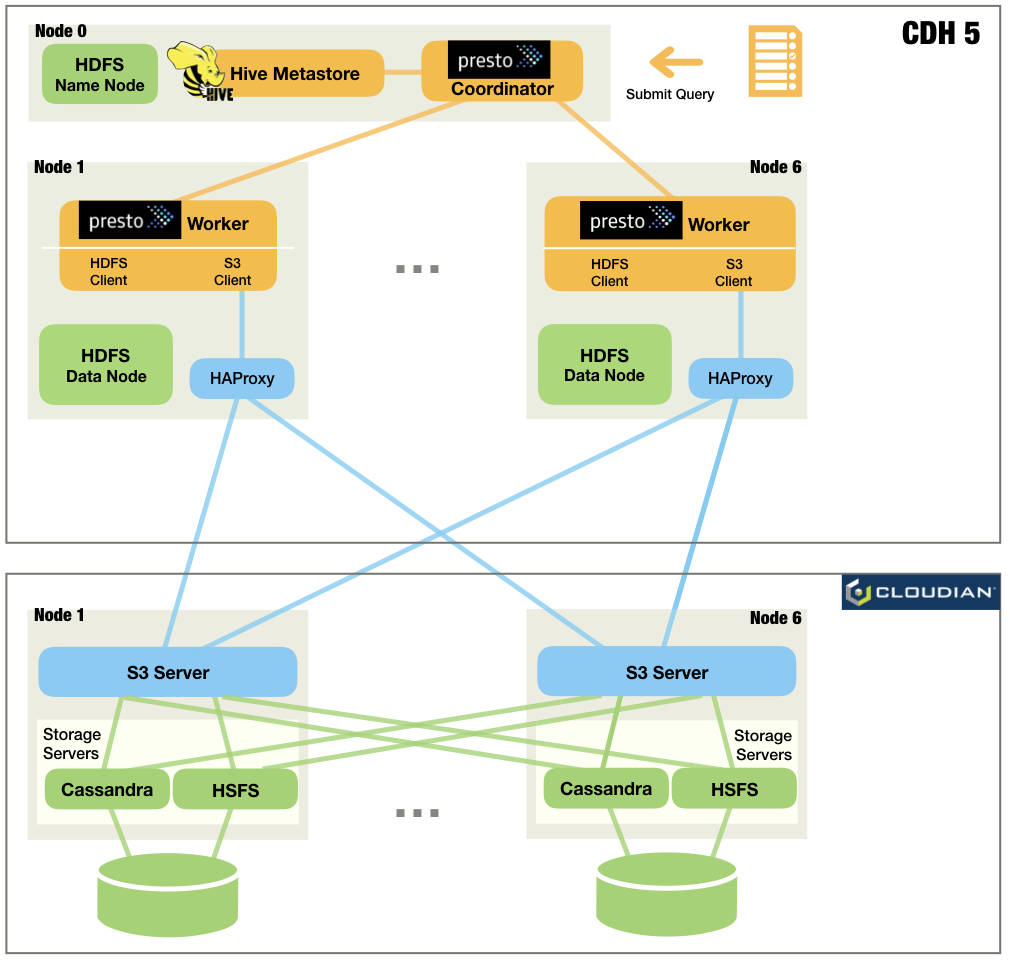
1.輸入和輸出的Hive表存儲在S3上。 (此時輸出表應為空)
2.HiBench或TPC-H查詢從節點0上的Presto客戶端提交到同一節點上的Presto Coordinator。
3.Presto Coordinator詢問Hive Metastore以找到Hive表。
4.Presto Coordinator為查詢安排一系列任務。
5.很快,工人使用其嵌入式S3客戶端執行這些任務,在HyperStore S3上讀取/寫入數據。中間結果保存在內存中並在Presto Workers之間流式傳輸。
完成所有任務後,Presto Coordinator會將查詢結果返回給客戶端。
衡量績效
為了在Hive和Presto上生成負載,我們使用了以下基準:
英特爾HiBench是一款出色的數據基準測試套件,可幫助評估速度方面的各種大數據產品。它有三個Hive工作負載,它們是基於SIGMOD 09報告“大規模數據分析方法的比較(A Comparison of Approaches to Large Scale Data Analysis)”開發的。
TPC-H是一種OLAP(在線分析處理)工作負載,用於衡量數據倉庫上下文中的分析查詢性能。很快你就可以運行未經修改的TPC-H查詢(符合ANSI SQL)並且它具有可以生成TPC-H數據集的TPC-H連接器。 Hive不能直接運行TPC-H查詢,但作者們在GitHub上發現了幾個TPC-H的Hive-QL實現,他們使用了其中一個。
HiBench工作負載提供非常簡單的重寫和重讀查詢。它們將幫助我們理解產品在讀/寫性能方面的差異。
TPC-H提供複雜的重讀查詢。這些查詢將為我們提供有關實際性能差異的更多信息。
HiBench Hive負載量
HiBench數據集是使用HiBench的數據生成器創建的,並以SequenceFile格式存儲。我們將hibench.scale.profile設置為large,將hibench.default.map.parallelism設置為48,我們得到以下數量的輸入數據:
所有2個表的總計約1,100萬條記錄
所有48個存儲文件組合~1.8 GB(每個約37 MB)
我們將Hive-QL移植到Presto可以執行的SQL。很快通過Hive連接器訪問Hive表。
我們通過手動執行每個查詢來測量性能,並以毫秒為單位記錄查詢時間。結果如下:
HiBench查詢時間
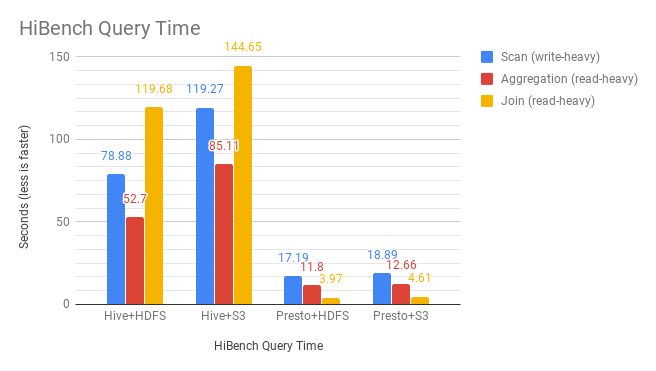
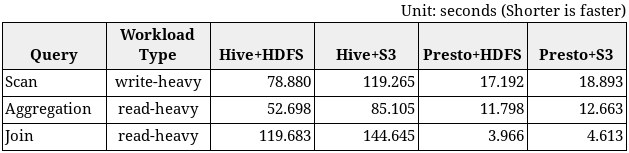
發現
儘管有名稱,“掃描”查詢不僅會讀取輸入表中的所有記錄,還會將所有記錄複製到輸出表中。所以它寫得很重。
HiBench結果摘要:
輸入數據大小約為1,100萬條記錄(~1.8GB),以SequenceFile格式存儲。
HiBench適用於測量基本讀/寫性能。
對於大量寫入查詢,Presto + S3比Hive + HDFS快4.2倍。
對於讀取繁重的查詢,Presto + S3比Hive + HDFS快15.1倍。
TPC-H基準
TPC-H數據集是使用Presto的TPC-H連接器創建的,並使用ZLIB壓縮以ORC(優化行列式)格式存儲。 ORC類似於Parquet並廣泛用於Hive。我們無法使用Parquet,因為Hive 1.1不支持Parquet文件中的“日期”列類型。
我們選擇TPC-H比例因子為100來生成100GB數據集。我們得到了以下數量的輸入數據:所有8個表的總計約8.66億條記錄。很快就可以運行未經修改的TPC-H查詢。它通過Hive連接器訪問存儲TPC-H數據集的Hive表。
TPC-H查詢時間
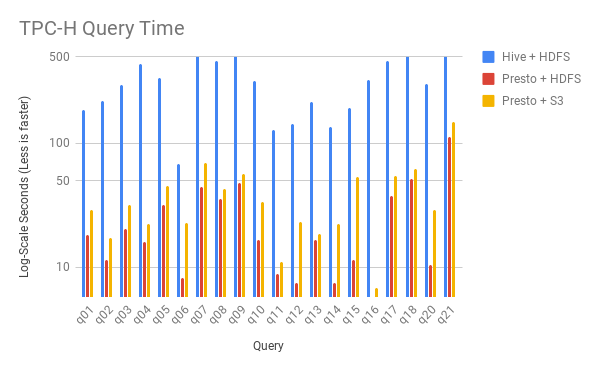
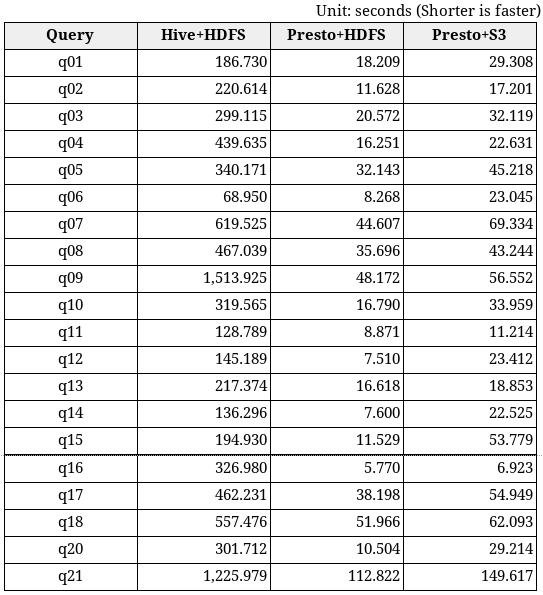
發現
所有TPC-H查詢都是重讀的(read-heavy)。
作者們沒有測量Hive + S3性能,因為從HiBench結果來看,我們預計它會比所有其他組合慢,我們可能對結果不感興趣。
也沒有在100GB數據集上運行查詢“q19”,因為Hive和Presto在1GB數據集上返回了不同的查詢結果。
我們跳過查詢“q22”,因為它在Hive上100GB數據集上失敗了。
如前所述,我們將Presto coordinator / worker的query.max-memory-per-node設置為12GB以處理內存中的查詢。大多數查詢在每個節點8GB內存內完成,但“q09”和“q21”分別需要每個節點10GB和12GB內存。
TPC-H結果摘要:
輸入數據大小:〜8.66億條記錄(~100GB),以ORC格式存儲,具有ZLIB壓縮。
TPC-H適用於測量分析查詢的實際性能。
Presto + S3平均比Hive + HDFS快11.8倍。
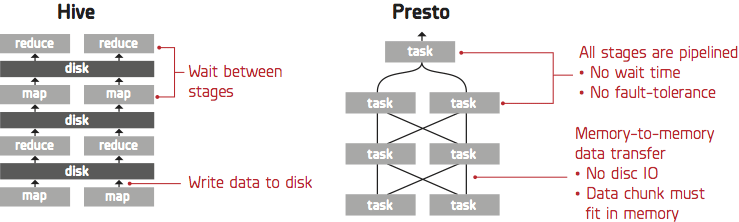
為什麼Presto在基準測試中比Hive更快
Presto是內存中的查詢引擎,因此它不會將中間結果寫入存儲(S3)。 Presto比Hive做的S3請求少得多。此外,與Hive M / R作業不同,Presto在寫入後不執行重命名文件操作。重命名在S3存儲中非常昂貴,因為它是通過複製和刪除文件操作實現的。最後,Hive的架構要求它在各個階段之間等待(M/R作業),這使得難以繼續利用所有CPU和磁盤資源。
結論
匯總基準測試結果,從最佳到最差的相對表現為:
Presto + HDFS(最好的)
Presto + S3
Hive + HDFS
Hive + S3(最差)
Presto + S3組合顯示出與最佳Presto + HDFS組合非常相似的性能結果,證明Hadoop用戶可以實現靈活性使用S3軟件分離存儲和計算的成本優勢,沒有任何顯著的性能折衷。
轉貼自: DATAVERSITY

留下你的回應
以訪客張貼回應