
摘要: 本文重點介紹了在測試機器學習模型時遇到的一個關鍵主題。
1. 什麼是過度擬合?
讓我們首先確定概念的基礎。
假設您想要預測股票的未來價格變動,然後,您決定收集過去10天的股票的歷史每日價格,並在散佈圖上繪製股票價格,如下所示:
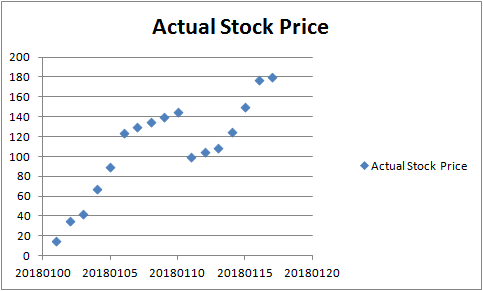
上圖顯示實際股票價格是隨機的。
要捕獲股票價格變動,您需要評估並收集以下16種功能的數據,您知道股票價格取決於:
1.行業表現
2.公司新聞發布
3.公司的收益
4.公司的利潤
5.公司未來的公告
6.公司的股息
7.公司當前和未來的合約規模
8.公司的併購狀態
9.公司的管理信息
10.公司目前的合同
11.公司的未來合同
12.通貨膨脹
13.利率
14.外匯匯率
15.投資者情緒
16.公司的競爭對手
收集,清理,縮放和轉換數據後,您可以將數據拆分為訓練和測試數據集。此外,您將訓練數據提供給您的機器學習模型以進行訓練。
訓練模型後,您決定通過傳入測試數據集來測試模型的準確性。
我們期待看到什麼?
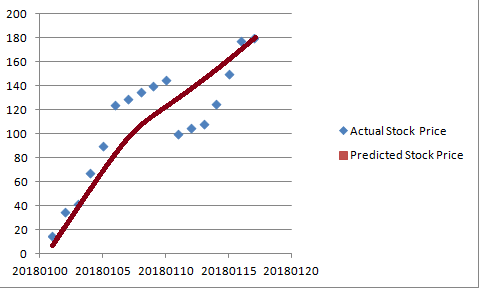
上圖顯示實際股票價格是隨機的。然而,預測的股票價格是平滑的曲線。它不擬合訓練集,因此它能夠更好地概括看不見的數據。
若假設你會遇到以下實際vs預測的股票價格圖形:
1.預測價格是一直線
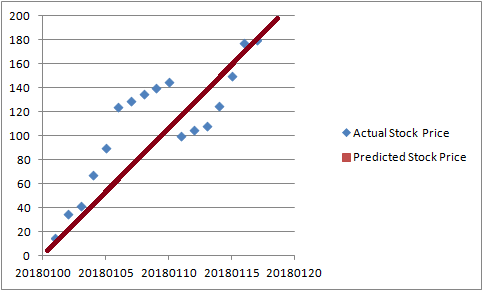
這意味著該算法具有非常強的數據預概念。這意味著它具有高偏見性。這被稱為欠擬合。這些模型不適合預測新數據。
2.非常強大的緊密擬合線
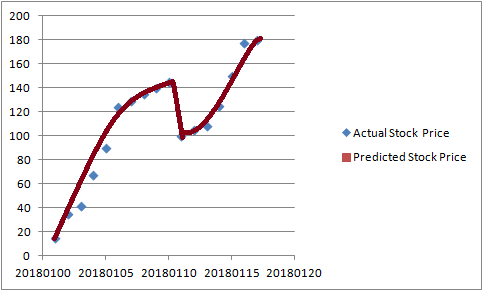
這是另一個極端。它可能看起來好像在預測股價方面做得很好。然而,這被稱為過度擬合。它也被稱為高方差,因為它已經很好地學習了訓練數據,因此無法很好地概括新的和看不見的數據。這些模型不適合預測新數據。
如果我們為模型提供新數據,那麼它的準確性將最終變得極差。
這也表明我們沒有用足夠的數據訓練我們的模型。
過度擬合是指您的模型過度訓練自己訓練的數據。可能是因為數據中存在太多特徵,或者因為我們沒有提供足夠的數據。它發生在實際值和預測值之間的差值接近0時。
如何檢測過度擬合?
過度適應訓練數據的模型並不能很好地概括新的例子。他們不善於預測看不見的數據。
這意味著它們在訓練期間非常準確,並且在預測看不見的數據期間產生非常差的結果。
如果在模型訓練期間精度測量值(例如平均誤差平方)顯著降低,並且測試數據集的精度會下降,那麼這意味著您的模型過度擬合數據。
如果您想了解可用於測量機器學習模型準確性的算法,請查看本文
我們如何解決過度擬合問題?
我們可以隨機刪除這些特徵並迭代地評估算法的準確性,但這是一個非常繁瑣和緩慢的過程。
基本上有四種減少過度擬合的常用方法。
1.減少特徵:
最明顯的選擇是減少特徵。您可以計算要素的相關矩陣,並減少彼此高度相關的要素
2.模型選擇算法:
您可以選擇模型選擇算法。這些算法可以選擇更重要的特徵。
這些技術的問題在於我們最終可能會丟失有價值的信息。
3.提供更多數據
您的目標應該是為模型提供足夠的數據,以便對模型進行全面的培訓,測試和驗證。旨在提供60%的數據來訓練模型,20%的數據用於測試,20%的數據用於驗證模型。
4.正規化:
正規化的目的是保持所有特徵,但對係數的大小施加約束。
它是首選,因為您通過懲罰機制來避免丟失特徵。當約束應用於參數時,模型不太容易過度擬合,因為它產生平滑的函數。
引入稱為懲罰因子的正規化參數,其控制參數並確保模型本身不會過度訓練訓練數據。
這些參數被設置為較小的值以消除過度擬合。當係數取大值時,正規化參數懲罰優化函數。
有兩種常見的正規化技術:
1.LASSO
增加一個懲罰值,它是係數幅度的絕對值。這確保了特徵不會最終對算法的預測施加高權重。
2. RIDGE
增加一個懲罰,它是係數大小的平方。結果,一些權重最終將為零。這意味著某些功能的數據將不會在算法中使用。

結論
本文重點介紹了我們在測試機器學習模型後遇到的一個關鍵主題。它概述了以下關鍵部分:
什麼是機器學習項目中的過度擬合?
我們如何檢測過度擬合?
我們如何解決過度擬合問題?
如果您想掌握機器學習項目的端到端指南,請閱讀 本文
轉貼自: Medium
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應