
摘要: Facebook has announced Ego4D, a long-term project aimed at solving AI research challenges in “egocentric perception,” or first-person views. The goal is to teach AI systems to comprehend and interact with the world like humans do as opposed to in the third-person, omniscient way that most AI currently does.

It’s Facebook’s assertion that AI that understands the world from first-person could enable previously impossible augmented and virtual reality (AR/VR) experiences. But computer vision models, which would form the basis of this AI, have historically learned from millions of photos and videos captured in third-person. Next-generation AI systems might need to learn from a different kind of data — videos that show the world from the center of the action — to achieve truly egocentric perception, Facebook says.
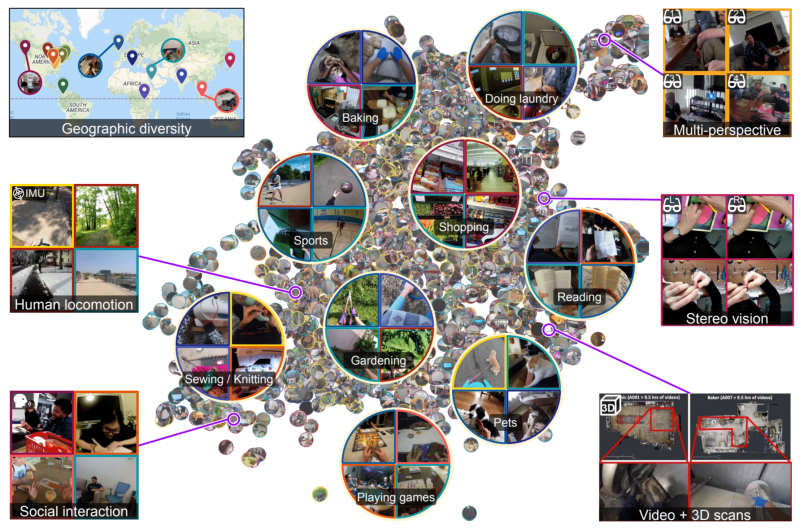
To that end, Ego4D brings together a consortium of universities and labs across nine countries, which collected more than 2,200 hours of first-person video featuring over 700 participants in 73 cities going about their daily lives. Facebook funded the project through academic grants to each of the participating universities. And as a supplement to the work, researchers from Facebook Reality Labs (Facebook’s AR- and VR-focused research division) used Vuzix Blade smartglasses to collect an additional 400 hours of first-person video data in staged environments in research labs.
COLLECTING THE DATA
According to Kristen Grauman, lead research scientist at Facebook, today’s computer vision systems don’t relate to first- and third-person perspectives in the same way that people do. For example, if you strap a computer vision system onto a rollercoaster, it likely won’t have any idea what it’s looking at — even if it’s trained on hundreds of thousands of images or videos of rollercoasters shown from the sidelines on the ground.
“For AI systems to interact with the world the way we do, the AI field needs to evolve to an entirely new paradigm of first-person perception,” Grauman said in a statement. “That means teaching AI to understand daily life activities through human eyes in the context of real-time motion, interaction, and multisensory observations.”
In this way, Ego4D is designed to tackle challenges related to embodied AI, a field aiming to develop AI systems with a physical or virtual embodiment, like robots. The concept of embodied AI draws on embodied cognition, the theory that many features of psychology — human or otherwise — are shaped by aspects of the entire body of an organism. By applying this logic to AI, researchers hope to improve the performance of AI systems like chatbots, robots, autonomous vehicles, and even smartglasses that interact with their environments, people, and other AI.

Ego4D recruited teams at partner universities to hand out off-the-shelf, head-mounted cameras (including GoPros, ZShades, and WeeViews) and other wearable sensors to research participants so that they could capture first-person, unscripted videos of their daily lives. The universities included:
- University of Bristol
- Georgia Tech
- Carnegie Mellon University
- Indiana University
- International Institute of Information Technology
- King Abdullah University of Science and Technology
- University of Minnesota
- National University of Singapore
- University of Tokyo
- University of Catania
- Universidad de los Andes
The teams had participants record roughly eight-minute clips of day-to-day scenarios like grocery shopping, cooking, talking while playing games, and engaging in group activities with family and friends. Ego4D captures where the camera wearer chose to gaze at in a specific environment, what they did with their hands (and objects in front of them), and how they interacted with other people from an egocentric perspective.
Some footage was paired with 3D scans, motion data from inertial measurement units, and eye tracking. The data was de-identified in a three-step process that involved human review of all video files, automated reviews, and a human review of automated blurring, Facebook says — excepting for participants who consented to share their audio and unblurred faces.
POTENTIAL BIAS
In computer vision datasets, poor representation can result in harm, particularly given that the AI field generally lacks clear descriptions of bias. Previous research has found that ImageNet and OpenImages — two large, publicly available image datasets — are U.S. and Euro-centric, encoding humanlike biases about race, ethnicity, gender, weight, and more. Models trained on these datasets perform worse on images from Global South countries. For example, images of grooms are classified with lower accuracy when they come from Ethiopia and Pakistan, compared to images of grooms from the United States. And because of how images of words like “wedding” or “spices” are presented in distinctly different cultures, object recognition systems can fail to classify many of these objects when they come from the Global South.

Tech giants have historically deployed flawed models into production. For example, Zoom’s virtual backgrounds and Twitter’s automatic photo-cropping tool have been shown to disfavor people with darker-colored skin. Google Photos once labeled Black people as “gorillas,” and Google Cloud Vision, Google’s computer vision service, was found to have labeled an image of a dark-skinned person holding a thermometer “gun” while labeling a similar image with a light-skinned person “electronic device.” More recently, an audit revealed that OpenAI’s Contrastive Language-Image Pre-training (CLIP), an AI model trained to recognize a range of visual concepts in images and associate them with their names, is susceptible to biases against people of certain genders and age ranges.
In an effort to diversify Ego4D, Facebook says that participants were recruited via word of mouth, ads, and community bulletin boards from the U.K., Italy, India, Japan, Saudi Arabia, Singapore, and the U.S. across varying ages (97 were over 50 years old), professions (bakers, carpenters, landscapers, mechanics, etc.), and genders (45% were female, one identified as nonbinary, and three preferred not to say a gender). The company also says it’s working on expanding the project to incorporate data from partners in additional countries including Colombia and Rwanda.

But Facebook declined to say whether it took into account accessibility and users with major mobility issues. Disabled people might have gaits, or patterns of limb movements, that appear different to an algorithm trained on footage of able-bodied people. Some people with disabilities also have a stagger or slurred speech related to neurological issues, mental or emotional disturbance, or hypoglycemia, and these characteristics may cause an algorithm to perform worse if the training dataset isn’t sufficiently inclusive.
In a paper describing Ego4D, Facebook researchers and other contributors concede that biases exist in the Ego4D dataset. The locations are a long way from complete coverage of the globe, they write, while the camera wearers are generally located in urban or college town areas. Moreover, the pandemic led to ample footage for “stay-at-home scenarios” such as cooking, cleaning, and crafts, with more limited video at public events. In addition, since battery life prohibited daylong filming, the videos in Ego4D tend to contain more “active” portions of a participant’s day.
BENCHMARKS
In addition to the datasets, Ego4D introduces new research benchmarks of tasks, which Grauman believes is equally as important as data collection. “A major milestone for this project has been to distill what it means to have intelligent egocentric perception,” she said. “[This is] where we recall the past, anticipate the future, and interact with people and objects.”
The benchmarks include:
- Episodic memory: AI could answer freeform questions and extend personal memory by retrieving key moments in past videos. To do this, the model must localize the response to a query within past video frames — and, when relevant, further provide 3D spatial directions in the environment.
- Forecasting: AI could understand how the camera wearer’s actions might affect the future state of the world, in terms of where the person is likely to move and what objects they’re likely to touch. Forecasting actions requires not only recognizing what has happened but looking ahead to anticipate next moves.
- Hand-object interaction: Learning how hands interact with objects is crucial for coaching and instructing on daily tasks. AI must detect first-person human-object interactions, recognize grasps, and detect object state changes. This thrust is also motivated by robot learning, where a robot could gain experience vicariously through people’s experience observed in video.
- Audiovisual diarization: Humans use sound to understand the world and identify who said what and when. AI of the future could too.
- Social interaction: Beyond recognizing sight and sound cues, understanding social interactions is core to any intelligent AI assistant. A socially intelligent AI would understand who is speaking to whom and who is paying attention to whom.
Building these benchmarks required annotating the Ego4D datasets with labels. Labels — the annotations from which AI models learn relationships in data — also bear the hallmarks of inequality. A major venue for crowdsourcing labeling work is Amazon Mechanical Turk, but an estimated less than 2% of Mechanical Turk workers come from the Global South, with the vast majority originating from the U.S. and India.
For its part, Facebook says it leveraged third-party annotators who were given instructions to watch a five-minute clip, summarize it, and then rewatch it, pausing to write sentences about things the camera wearer did. The company collected “a wide variety” of label types, it claims, including narrations describing the camera wearer’s activity, spatial and temporal labels on objects and actions, and multimodal speech transcription. In total, thousands of hours of video were transcribed and millions of annotations were compiled, with sampling criteria spanning the video data from partners in the consortium.

“Ego4D annotations are done by crowdsourced workers in two sites in Africa. This means that there will be at least subtle ways in which the language-based narrations are biased towards their local word choices,” the Ego4D researchers wrote in the paper.
FUTURE STEPS
It’s early days, but Facebook says it’s working on assistant-inspired research prototypes that can understand the world around them better by drawing on knowledge rooted in the physical environment. “Not only will AI start to understand the world around it better, it could one day be personalized at an individual level — it could know your favorite coffee mug or guide your itinerary for your next family trip,” Grauman said.
Facebook says that in the coming months, the Ego4D university consortium will release its data. Early next year, the company plans to launch a challenge that’ll invite researchers to develop AI that understands the first-person perspectives of daily activities.
The efforts coincide with the rebranding of Facebook’s VR social network, Facebook Horizon, to Horizon Worlds last week. With Horizon Worlds, which remains in closed beta, Facebook aims to make available creation tools to developers so that they can design environments comparable to those in rival apps like Rec Room, Microsoft-owned AltSpace, and VRChat. Ego4D, if successful in its goals, could give Facebook a leg up in a lucrative market — Rec Room and VRChat have billion-dollar valuations despite being pre-revenue.
“Ultimately — for now, at least — this is just a very clean and large dataset. So in isolation, it’s not particularly notable or interesting. But it does imply a lot of investment in the future of ‘egocentric’ AI, and the idea of cameras recording our lives from a first-person perspective,” Mike Cook, an AI researcher at Queen Mary University, told VentureBeat via email. “I think I’d mainly argue that this is not actually addressing a pressing challenge or problem in AI … unless you’re a major tech firm that wants to sell wearable cameras. It does tell you a bit more about Facebook’s future plans, but … just because they’re pumping money into it doesn’t mean it’s necessarily going to become significant.”
Beyond egocentric, perspective-aware AI, high-quality graphics, and avatar systems, Facebook’s vision for the “metaverse” — a VR universe of games and entertainment — is underpinned by its Quest VR headsets and forthcoming AR glasses. In the case of the latter, the social network recently launched Ray-Ban Stories, a pair of smartglasses developed in collaboration with Ray-Ban that capture photos and videos with built-in cameras and microphones. And Facebook continues to refine the technologies it acquired from Ctrl-labs, a New York-based startup developing a wristband that translates neuromuscular signals into machine-interpretable commands.
Progress toward Facebook’s vision of the metaverse has been slowed by technical and political challenges, however.
CEO Mark Zuckerberg recently called AR glasses “one of the hardest technical challenges of the decade,” akin to “fitting a supercomputer in the frame of glasses.” Ctrl-labs head Andrew Bosworth has conceded that its tech is “years away” from consumers, and Facebook’s VR headset has yet to overcome limitations plaguing the broader industry like blurry imagery, virtual reality sickness, and the “screen door effect.”
Unclear, too, is the effect that an internal product slowdown might have on Facebook’s metaverse-related efforts. Last week, The Wall Street Journal reported that Facebook has delayed the rollout of products in recent days amid articles and hearings related to internal documents showing harms from its platforms. According to the piece, a team within the company is examining all in-house research that could potentially damage Facebook’s image if made public, conducting “reputational reviews” to examine how Facebook might be criticized.
To preempt criticism of its VR and AR initiatives, Facebook says it’s soliciting proposals for research to learn about making social VR safer and to explore the impact AR and VR can have on bystanders, particularly underrepresented communities. The company also says it doesn’t plan to make Ego4D publicly available, instead requiring researchers to seek “time-limited” access to the data to review and assent to license terms from each Ego4D partner. Lastly, Facebook says it has placed restrictions on the use of images from the dataset, preventing the training of algorithms on headshots.
轉貼自Source: dataconomy
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應