
比特幣54100元一枚!深度學習能預測其價格跌漲
近年來,加密貨幣交易勢頭很足,從早期的比特幣,發展到現在,全球加密數字貨幣已經超過900 種,除了廣為人知的比特幣之外,還有以太幣、瑞波幣等。
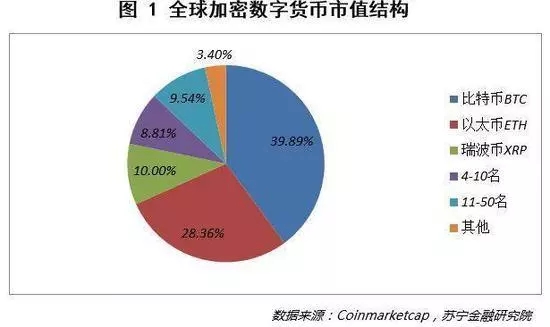
Coinmarketcap 數據顯示,截止2017 年6 月28 日,共有928 個加密數字貨幣,其中722 個有市值統計,總市值1061 億美元。
從市場結構來看,比特幣市值423.36 億美元,佔比39.89%;以太幣市值301 億美元,佔比28.36%;瑞波幣市值106 億美元,佔比10%。前三大加密數字貨幣合計佔比78.25%,第4-10 名合計佔比8.81%,第11-50 名合計佔比9.54%,其餘672 個幣種僅佔3.40%。
由於加密貨幣具有可以避開政府政策(好或壞)的去中心化性質,在一些當地貨幣對人們沒有多大吸引力的國家,比特幣開始被視為一個有效可行的替代品,加密貨幣價格也在經歷下跌之後反彈。據coingecko 數據顯示,2017 年11 月21 日,比特幣的價格已達8120.85 美元。
數據獲取
長期短期記憶(LSTM)是一種特別適用於時間序列數據(或具有時間/空間/結構順序的數據,例如電影、句子等)的深度學習模型,是預測加密貨幣的價格走向的理想模型。在建模之前,我們需要獲取一些數據。因為需要在一個模型中結合多個貨幣幣種,所以較好的方法是從同一個源頭獲取數據。在示例中,我們採用從coinmarketcap.com上獲取的數據,以比特幣和以太幣為例,在導入數據之前,需要加載一些Python包。
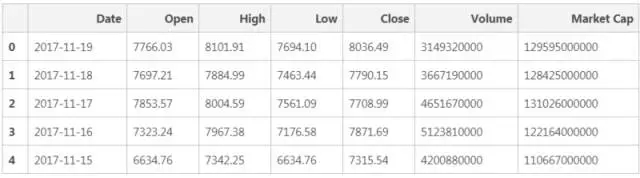
經過數據清理之後,我們得到上表。同理, 在URL 中把“比特幣”換成“以太幣”,就可以輕鬆完成幣種的轉換。
為了證明數據是準確的,可以繪製比特幣和以太幣的價格和數量隨著時間推移的圖表。


訓練、測試和隨機游動
接下來,是數據建模的過程。在深度學習中,數據通常分為訓練集和測試集,該LSTM 模型建立在訓練集上,在兩個不同的時間段內進行訓練,隨後在不可見的測試集上進行評估。這裡將截止日期設置為2017 年6 月1 日(即模型將在該日期之前接受數據培訓,並根據數據進行評估)。

從上圖中可以看到,訓練時段通常與比特幣價格相對較低的時期重合。因此,訓練數據可能並不能代表測試數據,模型生成不可見數據的能力也相應大打折扣。為了順利推進這個進程,我們先使用一個更簡單的模型,設定比特幣和以太幣明天的價格與今天的價格相等(滯後模型),它的數學定義是:


股票價格通常被視為隨機游動(random walk),將這個簡單的滯後模型進行拓展,用以下數學術語來定義:
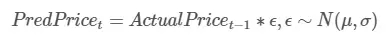
之後,我們將根據訓練集確定為μ和σ,並將隨機游動模型應用於比特幣和以太幣測試集。
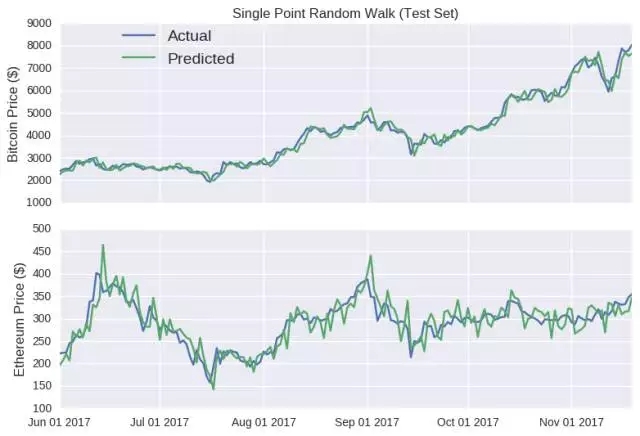
如圖所示,除了價格的走向,該模型還能追踪比特幣和以太幣的實際收盤價格,甚至還能反映出六月中旬和八月下旬,以太幣價格上升的趨勢(隨後下降)。如果在這個階段宣布發行虛擬貨幣,可能會引導ICO 超額認購,引起混亂。事實上,只能對未來很短一段時間做出預測的模型,往往是具有誤導性的,因為後續的預測中並沒有學會犯過的錯誤。因為模型是以真實價格為基礎的,所以,無論這個錯誤有多大,在每個時間點的數據都將重置。而比特幣隨機游動特別具有欺騙性,因為y 軸的比例相當寬,使得預測線顯得相當平滑。
在評估時間序列模型時,通常進行單點預測,但測試多點預測的準確性效果可能更好。這樣一來,先前預測發生的錯誤不會被重置,而是混在隨後的預測中,用數學術語表示:
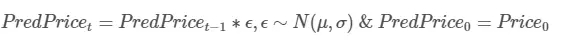
現在,我們用隨機游動模型來預測整個測試集的收盤價格。隨機模型預測對隨機種子非常敏感。
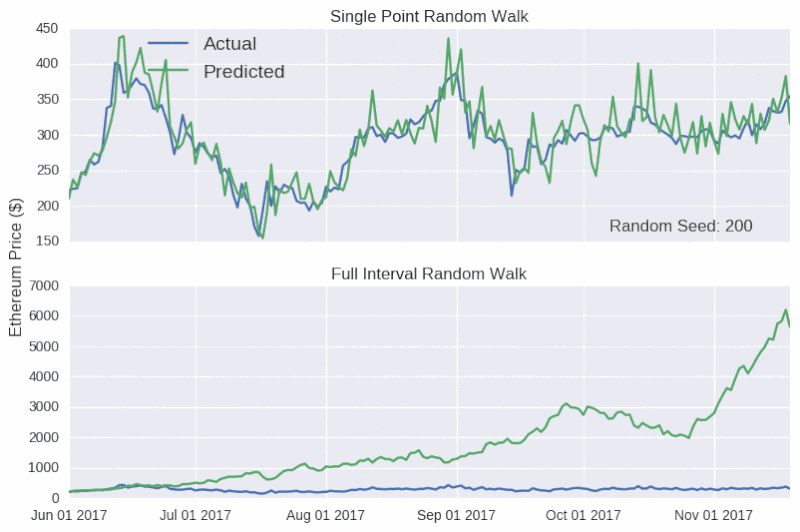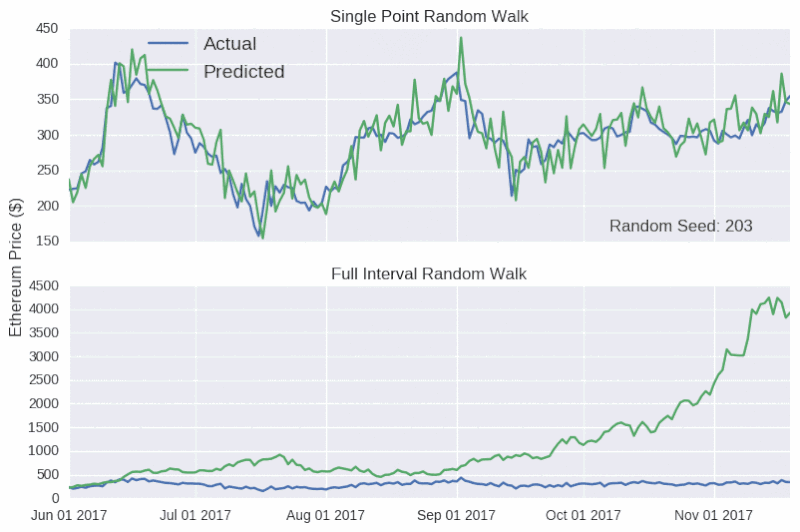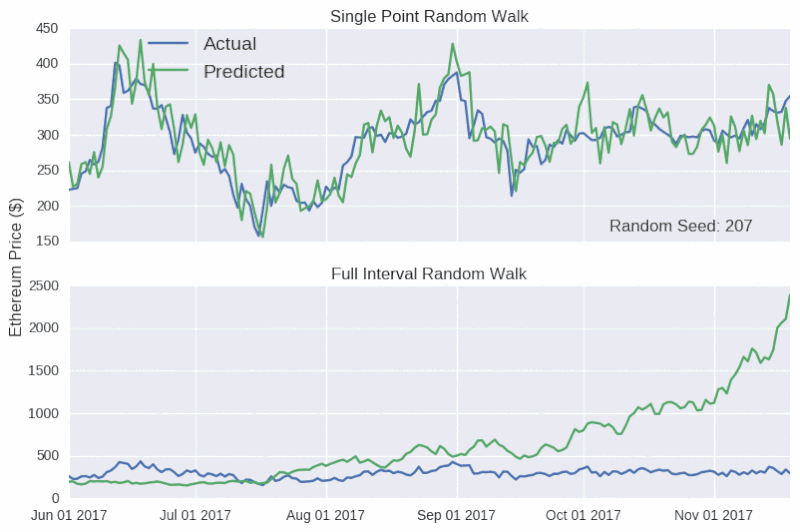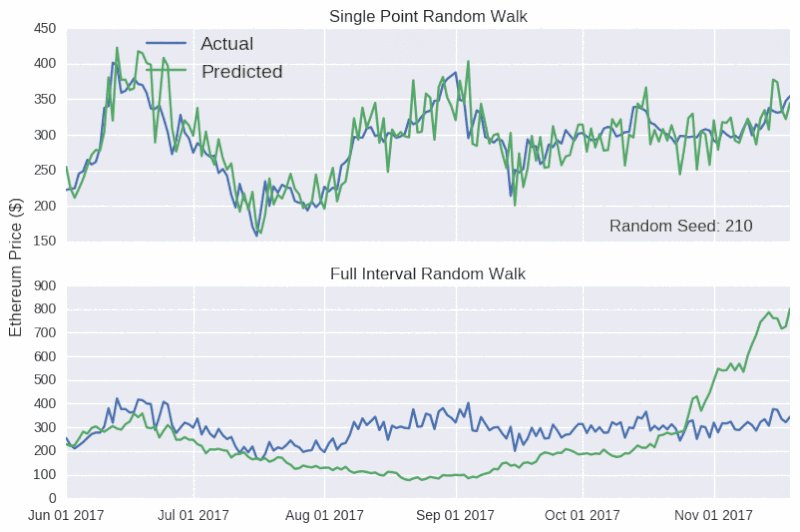
上表顯示,單點隨機游動預測的結果看起來相當準確,但背後卻沒有實質性的支撐數據。因此,對任何聲稱可以準確預測比特幣價格的言論,我們應該持懷疑的態度,就像加密貨幣粉絲要小心不要被市場營銷輕易帶跑一樣。
長短時記憶(LSTM)
對於LSTM,我們不需要從頭開始構建網絡,甚至不需要了解它,因為現成的就有包含各種深度學習算法(例如TensorFlow、Keras、PyTorch等)的標準使用安裝包。以Keras為例,這種算法對非專家學習人員來說是最直觀的。


首先,創建一個名為model_data 的新數據框,刪除一些列(開盤價、每日高點和低點),並重新加入一些列。close_off_high 表示當天收盤價格和價格高點之間的差值,-1 和1 的值分別表示收盤價與每日低點和每日高點相等,波動率列表示高價和低價之差除以開盤價。因為model_data 是按照時間順序排列的,這些信息不會被輸入到模型中,所以並不需要日期欄。
該LSTM 模型使用以前的數據(比特幣和以太幣)來預測第二天的特定貨幣的收盤價格。我們必須先確定之前哪些日期的數據是可以用的,比如選擇10 天的數據就比較合理。我們需要構建一些由連續10 天數據(稱為窗口)組成的小數據框,第一個窗口由訓練集的第0-9 行(Python 為零索引)組成,第二個窗口由1-10 行組成,依次類推。選擇一個規模較小窗口意味著我們可以為模型提供更多的窗口,但缺點是模型可能沒有足夠的信息來檢測複雜的長期行為(如果存在)。
在這些數據列中,數值變化的範圍非常大,其中一些值在-1 和1 之間,另一些則在達數百萬,而這是深度學習模型並不“喜歡”的。因此,我們需要對數據進行規範化處理,以保證輸入具有一定的一致性。通常情況下,我們需要-1 和1 之間的值,off_high 和volatility 列的值沒什麼問題,但對於剩餘的列,需要將輸入標準化為窗口中的第一個值。

這個表格是數百個類似LSTM 模型輸入列表的其中一個。經過對一些列進行歸一化處理後,它們的值在第一個時間點等於0。為了預測相對於這個時間點的價格變化,需要建立LSTM 模型。Keras 很輕鬆就可以做到這一點,只需將組件堆疊在一起就可以了。

所以,build_model函數建了一個空白的模型,稱為model(model = Sequential),並添加了一個LSTM層。該層已經過調整,以適應輸入(n×m個表格,其中n和m分別表示時間點/行和列的數量)。該函數還能夠調用更加通用的神經網絡功能,如退出和激活。現在,我們只需要指定放置在LSTM層上的神經元的數量,以及訓練的數據。

那麼,LSTM 模型預測以太幣明天收盤價格的表現如何呢?首先檢測其在訓練集上的表現(2017 年6 月之前的數據)。代碼下面的數字表示,在第50 次訓練迭代之後,模型訓練集的平均誤差(mae)。我們可以將模型輸出視為每日收盤價,而不是相對變化。

可以看到,這個模型預測數據的準確度非常高,因為其可以學習錯誤源並加以調整。事實上,實現訓練中錯誤為零並不難,在數百個神經元中進行數千次迭代(即過度擬合)就可以。
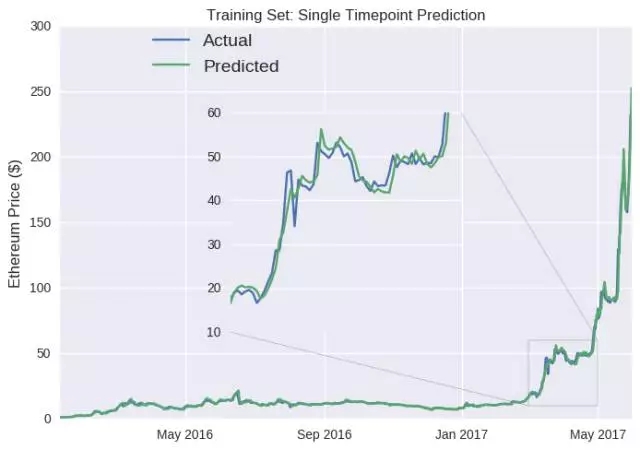
除了單點預測的誤導性之外,LSTM 模型在未經訓練和預處理的測試集上表現良好,預測的價格通常與一天后的實際價格相差無幾(例如7 月中旬價格下跌)。但這個模型最明顯的缺陷是,當價格突然上漲時(例如六月中旬和十月),它不能檢測到數值低迷的狀況,在峰值就更明顯了。
同理,為比特幣建立的類似LSTM 模型測試如下:

正如前述,單點預測同樣具有誤導性。下圖是LSTM 模型對未來五年加密貨幣價格的預測:
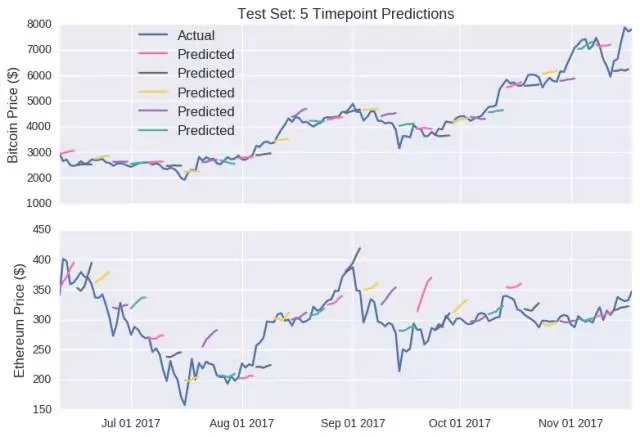
這個預測與之前有著細微的差別,價格的預測並不是朝向單一方向變動。在單點預測上,LSTM 模型與隨機游動模型一樣,對隨機種子的選擇也很敏感(模型權重最初是隨機分配的)。為對兩個模型進行比較,每個模型運行25 次,以獲得模型誤差的估值,此誤差值被計為測試集中實際和預測收盤價之間的差值。

從這個角度來看,人工智能的蓬勃發展不是沒有理由的:LSTM模型對比特幣和以太幣價格預測與實際價格的平均誤差僅分別為0.04和0.05,完敗隨機游動模型。
然而,完敗隨機游動模型並沒有多了不起,將LSTM 模型與更勢均力敵的時間序列模型,如加權平均、ARIMA 或Facebook 的先知算法等進行比較才更有意義。另一方面,LSTM 模型還可以進行更多改進,例如增加更多層或神經元、改變批量規模、學習速率等。
用於預測貨幣價格最完美的模型是:
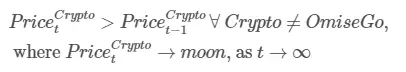
也許,我們不應該太迷信深度學習在預測貨幣價格變化方面的作用,因為我們不能忽略這樣一個事實:最完美的框架其實來源於人類的智慧,而加密貨幣的升值和貶值,永遠逃離不開市場規律的擺佈。
轉貼自: 煉數成金




留下你的回應
以訪客張貼回應