
摘要: 在摩爾定律的暮色中,GPU和其他硬件加速器極大地加速了神經網絡的訓練。但是隨著加速器的不斷改進,前期階段所花費的時間將逐漸成為訓練速度的瓶頸。谷歌大腦團隊提出了“數據回送(數據呼應)”算法,在部分情況下,數據回送甚至可以將訓練速度提升4倍。

在摩爾定律的暮色中,GPU和其他硬件加速器極大地加速了神經網絡的訓練。但是,訓練過程的前期階段(如磁盤讀寫和數據預處理)並不在加速器上運行。隨著加速器的不斷改進,這些前期階段所花費的時間將逐漸成為訓練速度的瓶頸。谷歌大腦團隊提出了“數據回送(數據呼應)”算法,它減少了訓練前期階段的總計算量,並在加速器上游的計算佔用訓練時間時加快訓練速度。“數據回送”复用訓練前期階段的中間輸出,以利用閒置的計算空間。作者研究了在不同任務,不同數量的回送以及不同批尺寸時數據回送算法的表現。在所有的情況下,至少有一種數據回送算法可以用更少的上游計算達到模型的基線性能。在部分情況下,數據回送甚至可以將訓練速度提升4倍。
在過去的十年中,神經網絡的訓練速度得到了極大的提升。研究人員能夠使用更大的數據集訓練更大的模型,並更快地探索新的想法,顯著提高了模型的表現性能。隨著摩爾定律的失效,通用處理器的速度已經不能滿足要求,但特定的加速器通過優化特定操作得到顯著的加速。例如,GPU和TPU優化了高度並行的矩陣運算,而矩陣運算正是神經網絡訓練算法的核心組成部分。
然而,訓練一個神經網絡需要的不僅僅是在加速器上運行的操作。訓練程序需要讀取和解壓縮訓練數據,對其進行打亂(shuffle的),批處理,甚至轉換或增強操作。這些步驟需要用到多個系統組件,包括CPU,磁盤,網絡帶寬和內存帶寬。這些通用操作涉及的組件太多,為它們設計專用的加速硬件是不切實際的。同時,加速器的改進遠遠超過了通用計算的改進,並且在加速器上運行的代碼只佔用整個訓練時間的一小部分因此,如果想使神經網絡訓練地更快,有以下兩個方法:(1)使非加速器工作地更快,或(2)減少非加速器所需的工作量。選項(1)可能需要大量的工程工作或技術探索,給系統增加太多的複雜性。因此,作者將重點放在選項(2)上,探索減少訓練前期階段的工作量的方法。
神經網絡的訓練過程可以看作是一個數據流程,需要對計算進行緩衝和重疊。例如,圖1顯示了小批次隨機梯度下降(SGD)及其變體的典型訓練流程,這是訓練神經網絡的標準算法訓練程序首先讀取和解碼輸入數據,然後對數據進行混洗,應用一組轉換操作來增加數據,並將數據分成不同批次最後,通過迭代更新網絡參數降低損失函數值;此階段稱為“SGD更新”。由於任何流程階段的輸出都可以緩衝,因此不同階段的計算互相重疊,最慢的階段將佔用主要的訓練時間。
▲圖1 經典神經網絡訓練流程圖
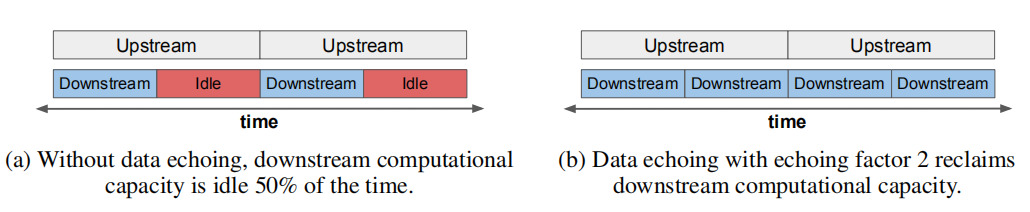
▲圖2 數據回送插入點上游上游和下游覆蓋計算時間。
在這篇論文中,作者研究如何通過減少訓練前期部分的時間來加速神經網絡訓練(圖2a)。作者將訓練過程中第一部分的輸出重複用於多個SGD更新,以利用空閒計算能力。這類算法稱為“數據回送”(data echoing),每個中間輸出被使用的次數稱為回送因子(echoing factor)。
數據回送算法在訓練流程中的某個位置(SGD更新之前)插入重複階段。如果上游任務(重複階段之前)花費的時間超過下游任務(重複階段之後)花費的時間,算法將回收下游閒置的計算能力,並提高模型的SGD更新率(圖2b)。通過改變插入點,回送因子和洗牌程度,可以得到不同的數據回送算法。
要點:
1.在數據集和模型結構上,數據回送在取得競爭性表現的同時減少了上游計算量
2.支持大範圍回送因子
3.有效性取決於訓練流程中插入點
4.數據回送可以從回送後的shuffle中獲益
5.數據回送與調優的基線模型取得相同錯誤率
數據回送指在訓練流程中插入一個重複階段,回送前一階段的輸出。如果重複數據的計算可以忽略不計,並且回送兩側的階段是並行執行的,則數據回送完成一個上游步驟和e個下游步驟的平均時間為:
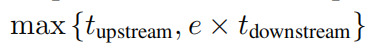
其中tupstream是回送上游所有階段所用的時間,tdownstream是回送下游所有階段所用的時間,例如是回送因子。假設tupstream≥tdownstream,這是使用數據回送的主要動機。如果用R = tupstream / tdownstream表示上下游處理時間之比,那麼完成一個上游步驟和e個下游步驟的時間對於從e到R的所有回送因子都是相同的。換句話說,額外的下游步驟是“無消耗的”,因為它們使用的是空閒的下游計算能力。
使用數據回送時,減少的訓練時間取決於上游步驟和下游步驟之間的比重。一方面,由於重複數據的價值可能低於新鮮的數據,數據回送可能需要更多的下游SGD更新才能達到預期的表現。另一方面,每個下游步驟只需要1 / E(而不是1)個上游步驟的時間。如果下游步驟增加的數量小於e,上游步驟的總數(以及總訓練時間)將減少。R代表數據回送的最大可能加速,如果e = R,並且重複數據和新數據價值相同,則可以實現最大加速。
不同插入點的數據回送:
批處理前或批處理後的回送:批處理前的回送是指數據在樣本級別而不是批級別進行重複這樣增加了相鄰批次不同的可能性,但代價是不能複製一批內的樣本。批處理前回送的算法稱為樣本回送(example echoing),批處理後回送的算法稱為批回送(batch echoing)。
數據增強前或數據增強後的回送:數據增強前的回送允許重複數據進行不同的轉換,能使重複數據更接近新數據。
數據回送的表現也受回送階段後 shuffle 程度的影響。在適用的情況下,作者將shuffle 作為緩衝區。緩衝區越大,shuffle 程度越高,訓練算法能夠近似於將整個訓練集加載到內存中。
作者在兩個語言建模任務,兩個圖像分類任務和一個目標檢測任務上驗證了數據回送的效果。對於語言建模任務,作者在LM1B和通用抓取數據集上訓練了Transformer 模型。對於圖像分類任務,作者在CIFAR-10數據集上訓練了RESNET-32模型,在ImageNet數據集上訓練了RESNET-50模型。對於目標檢測任務,作者在COCO數據集上訓練了SSD模型。
論文研究的主要問題是數據回送是否能夠加速訓練。作者用達到訓練目標所需的“新鮮”樣本數量衡量訓練時間。因為新樣本的數量與訓練流程中上游步驟的數量成正比,因此,在回送因子小於或等於 R時,新樣本的數量與實際時間亦成正比。
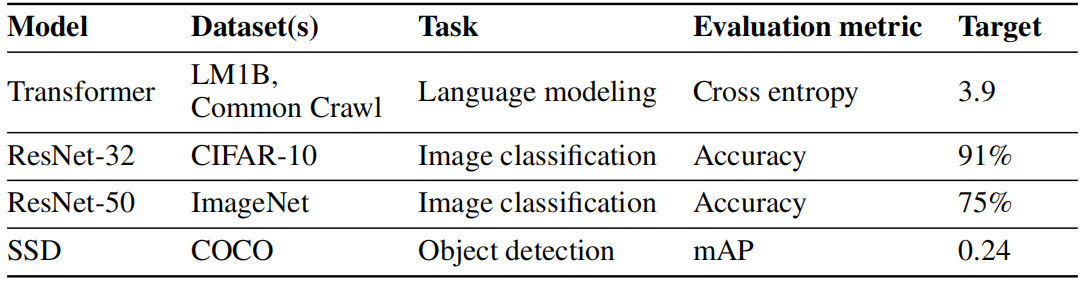
▲表1 任務總結
對於任務,作者運行了一組沒有數據回送的初始實驗,並且調整參數以在實際計算預算內獲得最佳的性能。作者選擇了比初始實驗中觀察到的最佳值稍差的目標值。目標的微小變化並不會影響結論。表1總結了實驗中使用的模型和目標值。
對每個實驗,作者獨立調整學習速率,動量和其它控制學習速率的參數。作者使用準隨機搜索來調整元參數。然後選擇使用最少的新樣本達到目標值的試驗。作者在每個搜索空間重複這個元參數搜索5次。實驗結果中的所有圖都顯示了這5次實驗所需的新樣本的平均數,用誤差條表示最小和最大值。
實驗評估了在標準神經網絡訓練流程中添加數據回送的效果作者實驗了三種不同的數據回送:數據增強前的樣本回送,增強後的樣本回送,以及批回送。
圖3顯示了表1中所有任務的數據回送效果,回送因子為2,除一種情況外,所有情況下數據回送達到目標性能所需要的新樣本數更少。唯一的例外(RESNET-50上的批回送)需要與基線相同數量的新樣本 - 說明數據回送雖然沒有帶來好處,但也不會損害訓練在訓練中插入回送越早,所需的新樣本就越少:與批回送相比,樣本回送需要的新樣本更少,並且數據增強之前的回送需要的新樣本比增強之後回送需要的新樣本更少。對於RESNET-50或SSD,沒有觀察到數據回送和批歸一化之間的任何負交互作用。
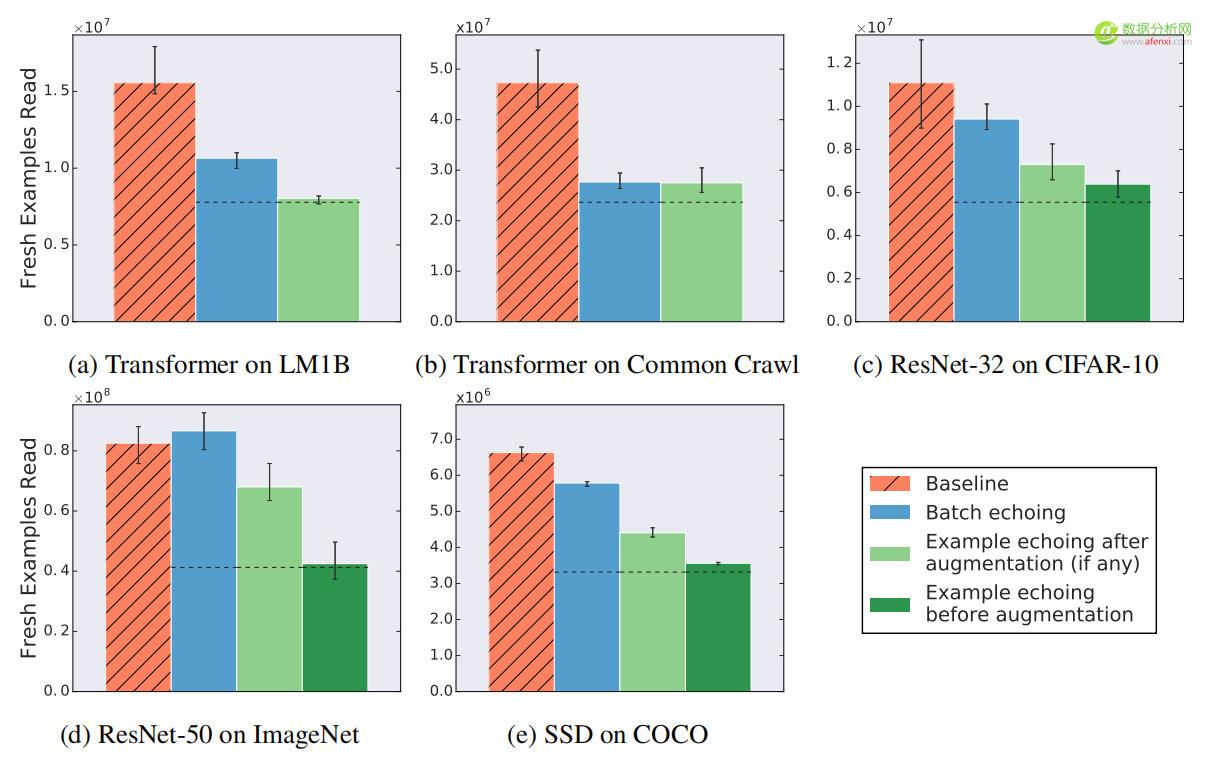
▲圖3 回送因子為2時,數據回送降低或不改變需要達到目標性能的新樣本數量。點劃線表示重複樣本與新樣本價值相同時的期望值。
圖4顯示了不同的 R值(上下游處理時間的比例)對應不同的回送因子e的訓練時間變化。如果R = 1,數據回送會增加,或不像預期的那樣顯著縮短訓練時間。如果R> 1,e≤R的任何設置都能縮短訓練時間,設置e= R可以最大程度地縮短訓練時間。設置e>R不會縮短LM1B數據集上的Transformer 的訓練時間,但它確實為ImageNet上的RESNET-50提供了加速。這些結果表明,圍繞e= R的最佳值附近的回送因子,數據回送可以縮短訓練時間,尤其是e≤R的設置。
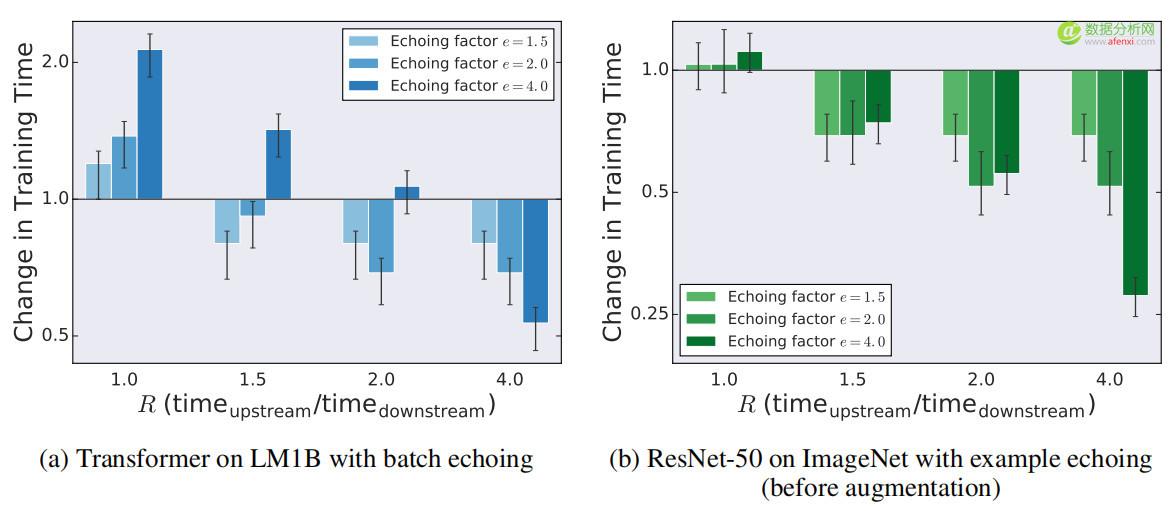
▲圖4 不同R值對訓練時間變化影響。
圖5顯示了Transformer 在LM1B上訓練時,回送因子高達16的影響批尺寸為1024時,最大有效回送因子介於4和8之間。超過此值,所需新樣本的數量就會大於較小回送因子所需的樣本數量。隨著回送因子的增加,所需的新樣本數量最終會超過基線,但即使是一個大於16的回送因子,所需的新樣本仍然比基線少得多。批尺寸為4096時,最大有效回送因子甚至大於16,這表明較大的批尺寸支持更大的回送因子。
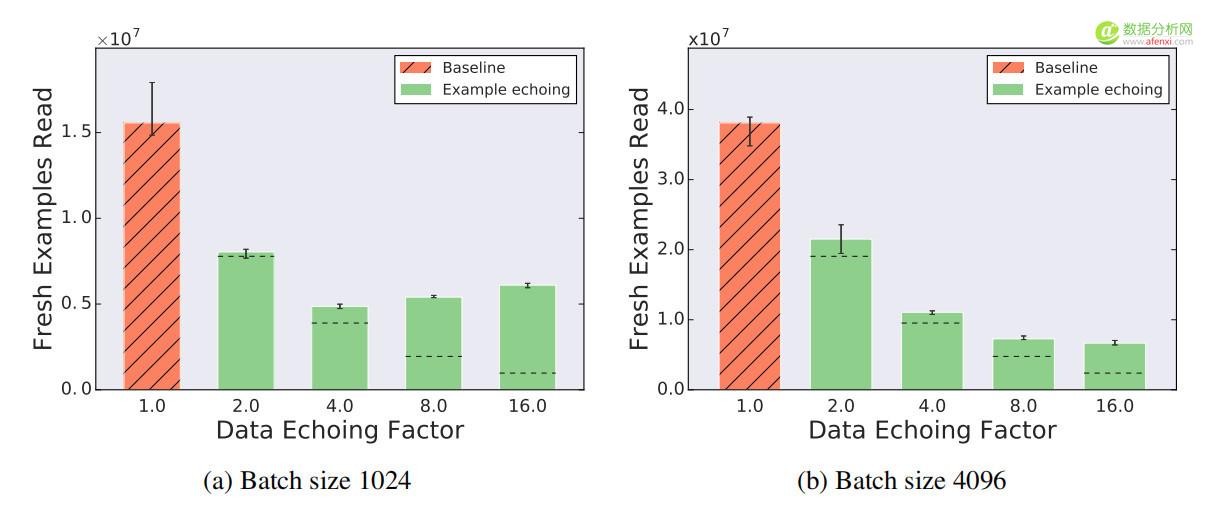
▲圖5 回送因子上限為16時,樣本回送減少了所需新樣本的數量。點劃線表示重複樣本與新樣本價值相同時的期望值。
對於較大的批尺寸,批回送的性能更好,但樣本回送有時需要更多的 shuffle 操作。圖6顯示了回送因子為2時,不同批尺寸的效果。隨著批尺寸的增加,批回送的性能相對於基線保持不變或有所提高。這種影響是有道理的,因為隨著批尺寸接近訓練集的大小,重複的批數據會接近新的批數據,因此,在限制範圍內,批回送必須通過回送因子減少所需的新樣本數量。另一方面,圖6顯示了隨著批尺寸增加,樣本回送的性能相對於基線的要么保持不變,要么變差。這是由於隨著批尺寸的增加,每批中重複樣本的比例也隨之增加,因此實際中,批尺寸較大的樣本回送的表現可能更像較小的批尺寸的表現。較小的批尺寸可能會增加所需的SGD更新步數,這可以解釋圖6中的樣本回送結果。增加重複樣本的亂序數量(以增加內存為代價)可以提升較大批尺寸樣本回送的性能,因為降低了每批中重複樣本的概率。
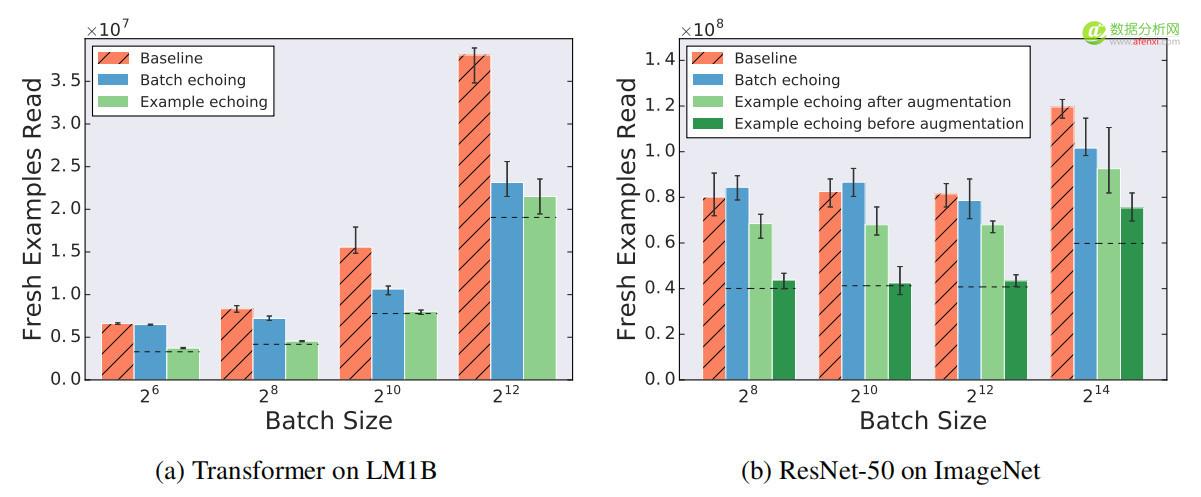
▲圖6 隨批尺寸增加,批回送的表現相對於基線保持不變或有所提升,而樣本回送的表現相對於基線保持不變或有所降低。點劃線表示重複樣本與新樣本價值相同時的期望值.。
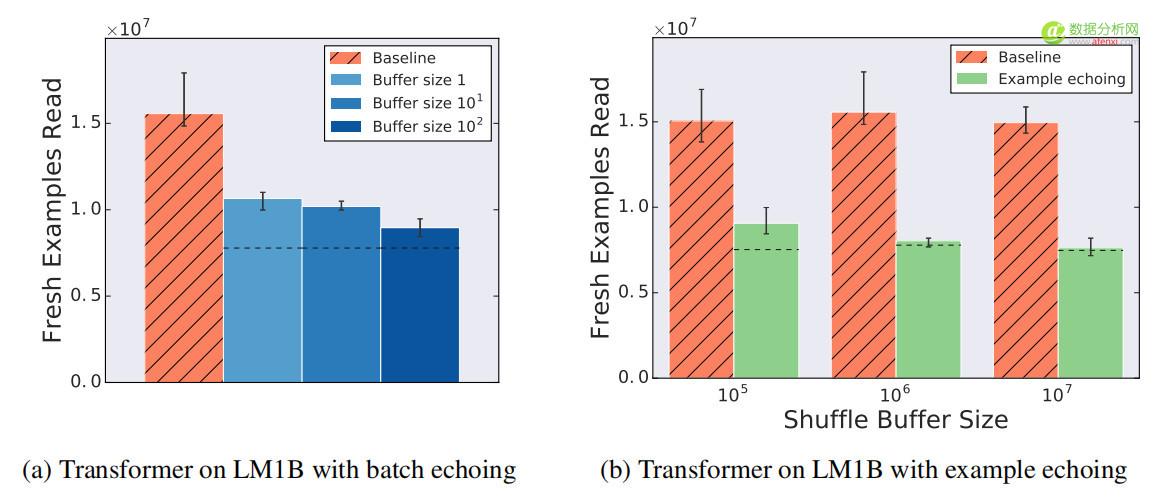
圖7顯示了增加數據回送的shuffle 緩衝區大小(以增加內存為代價)的效果。雖然之前的所有批回送實驗中沒有shuffle 操作,但如果重複批處理被打亂,批回送的性能會提高,而更多的亂序數量會帶來更好的性能。同樣,樣本回送的性能也隨著shuffle 緩衝區大小的增加而提高,即使它對基線沒有幫助。
▲圖6 隨批尺寸增加,批回送的表現相對於基線保持不變或有所提升,而樣本回送的表現相對於基線保持不變或有所降低。點劃線表示重複樣本與新樣本價值相同時的期望值.。
圖7 shuffle程度越高,數據回送的效果越好。
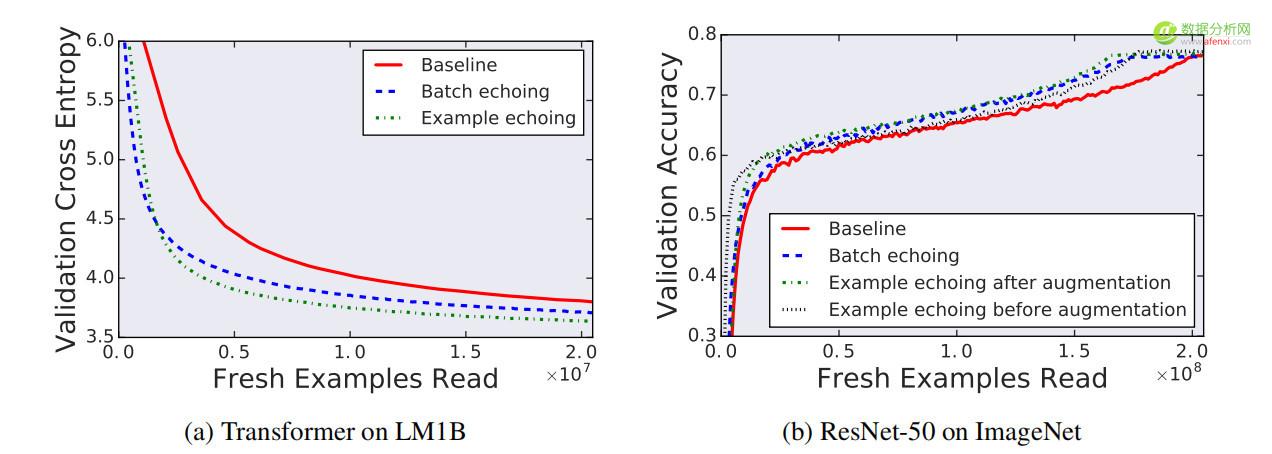
▲圖8 訓練中獨立試驗達到了最佳效果。
結論:
數據回送是提高硬體利用率的一種簡單策略,儘管先前研究人員擔心重複數據的SGD更新是無用的,甚至是有害的。但是對於實驗中的每一項任務,至少有一種數據回送方法能夠減少需要從磁盤讀取的樣本數量。
數據回送是優化訓練流程或額外上游數據處理的有效替代方案儘管訓練加速取決於模型結構,數據集,批尺寸以及重複數據的洗牌程度,但將回送因子設置為上下游處理時間的比率可以最大限度地提高潛在的加速速度,並在實驗中取得了良好的效果。隨著專業加速器(如GPU和TPU)的改進速度繼續超過通用計算的改進速度,數據回送以及類似的策略將成為神經網絡訓練工具包中越來越重要的組成部分。
查看论文原文:
Faster Neural Network Training with Data Echoing轉貼自: 數據分析網
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應