
摘要: 目前,深度學習模型需要大量算力,內存和電量。當我們需要執行實時推斷,在設備端運行資源有限的情況下運行瀏覽器時,這就是瓶頸。能耗是人們對於當前學習模型的主要擔憂。而解決這一問題的方法之一是提高推斷效率。
大模型 => 更多内存引用 => 更多能耗
隨著深度學習的發展,當前最優的模型準確率越來越高,但這一進步伴隨的是成本的增加。
挑戰:
1.模型規模越來越大
2:速度
解決方案:高效推斷算法
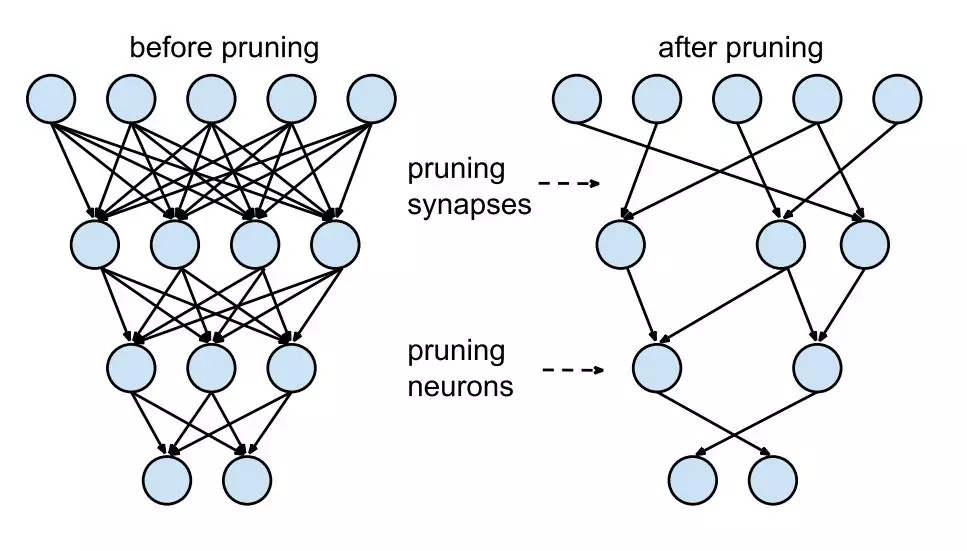
剪枝
權重共享
低秩逼近
二值化網絡(Binary Net)/三值化網絡(Ternary Net)
如果你根據神經元權重 L1 / L2範數進行排序,那麼剪枝後模型準確率會下降,(如果排序做得好的話,可能下降得稍微少一點),網絡通常需要經過訓練 - 剪枝 - 訓練 - 剪枝的迭代才能恢復。如果我們一次性修剪得太多,則網絡可能嚴重受損,無法恢復。因此,在實踐一個迭代的過程,這通常叫做“迭代式剪枝” (Iterative Pruning):修剪 - 訓練 - 重複(Prune / Train / Repeat)。
詳細全文及部分程式碼: 鍊數成金
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應