
摘要: 生成式AI需求爆發,導致GPU嚴重短缺,甚至影響到巨頭如微軟、OpenAI的業務,一般企業想導入AI,開始轉向軟體解決方案尋求更有效率的做法。
隨著今年生成式AI爆發,企業紛紛想投入自家的機密資料訓練「專屬大腦」,但GPU已經是高價稀缺資源,即便是滿手捧錢的大型企業,也難以支應龐大的GPU需求。該怎麼辦?
「GPU現在比毒品還難買到,好像所有人、還有他們的的狗都在買GPU。」今年5月《華爾街日報》舉辦的執行長高峰會上,伊隆.馬斯克(Elon Musk)用一貫的強烈風格形容GPU短缺的現況。 他不是唯一感到擔憂的人,協助企業建立大型語言模型的Lamini執行長雪倫.周(Sharon Zhou)用的形容詞是「和疫情期間瘋搶的衛生紙一樣」,並表示現在人脈變得異常重要,因為即使是全球最強大的科技創業者,也難以確保自己能獲得充足的GPU。 所謂「最強大的科技創業者」,也包括藉由ChatGPT掀起全球生成式AI熱潮的OpenAI創辦人山姆.奧特曼 (Sam Altman),他在5月於美國參議院作證時坦言:「我們的GPU非常短缺,現階段使用ChatGPT的人越少越好。」甚至因此推延部分功能的開發計畫。極力發展生成式AI應用的微軟,也在年報中首次將GPU短缺列為投資風險因素之一,甚至決定「反守為攻」。《The Information》 在報導中指出,面對AI晶片短缺、成本高昂的市況,微軟從2019年就啟動自研AI晶片專案「雅典娜Athena」,希望減緩成本壓力和對NVIDIA的依賴。 為什麼大家都在爭奪GPU資源?且如果這些最大型的科技公司都搶不到,一般企業還有什麼方法可以降低對GPU的需求?
AI運算的「心臟」,GPU到底有多缺?
GPU(圖形處理器)是手機、筆電到伺服器最重要的心臟,擔負起運算處理的任務。過去5年卻一直處於短缺狀況,加密貨幣「挖礦」龐大需求和2020年疫情導致的供應鏈危機,都讓GPU供不應求,從2022年底開始的生成式AI,更讓需求如黑洞般越捲越大、深不見底。
從2022年底開始的這波生成式AI熱潮,對GPU需求量到底有多大?
目前還沒有第三方機構進行全面性解析,不過匿名網站《GPU Utils》在7月發布了一篇文章:Nvidia H100 GPUs: Supply and Demand,揭露多家大型企業需求量,和NVIDIA高階GPU H100的供應現況,在科技圈內迅速爆紅,不只出現在《紐約時報》等媒體頭版上,連OpenAI的聯合創辦人兼科學家安德烈.卡帕斯(Andrej Karpathy)也在自己的推特上分享、多家資產管理公司和AI公司創辦人指出,文章中除了「誰擁有多少GPU」部分有待商榷外,其他數字都很精準掌握現況。 文章中估算,如果只是微調LLM模型,只需要數十張到數百張的NVIDIA H100,但若要「訓練」出一個LLM模型,則需要千張以上。換算下來,粗估全球企業對H100 GPU需求量落在43.2萬張,如果以每張3.5萬美元的售價來算,對於GPU總需求耗資近150億美元,這還不包括字節跳動、百度、騰訊等中國公司受到經濟制裁而無法購買的需求量。
《GPU Utils》推估H100需求用量:
◆ OpenAI:5萬張
◆ Meta:2.5到10萬張。
◆ 微軟Azure、Google Cloud、AWS、Oracle等公有雲商:每家3萬張
◆ 私有雲(Private Cloud)運算提供商如Lambda和CoreWeave等:共需要約10萬張
市場面臨如此巨量的需求,加上NVIDIA在高階AI GPU市場幾乎是獨霸的地位,短期內要接決解決GPU供應的短期限制變得困難。TrendForce資深分析師龔明德指出,上游公司台積電、三星、美光、SK海力士都在積極擴廠,需要6到9個月──也就是要到2024下半年,才有望開始減緩GPU供應鏈問題,但能否補上不斷增長的需求缺口,仍有待觀察。
買不到GPU又想導入AI?企業尋求軟體解方支援
不只科技巨頭面臨困境,一般企業也在著急尋找解方。龔明德觀察到,生成式AI讓大量業者想建構自家的LLM(大型語言模型)的基礎,無論是想建立可在公司系統運行的小型模型,還是能夠想要能夠自動思考的「推論」功能,需求都在短時間內往上擠。 台灣的需求爆發可以從一家新創公司「滿拓科技」的業績中看出端倪,滿拓是一家專精於AI模型縮小技術的公司,當AI模型被縮小,就可以大幅降低企業所需的GPU用量。過去滿拓只有10幾家客戶,到今年需求爆發,超過50家企業來主動接洽解決方案,遠超出可以負荷的量,「我們甚至跟小公司說可以再等等,因為現在生成式AI剛發展起來,成本太高了,只有大公司才能有試錯的空間。」滿拓科技創辦人吳昕益說。 其中一家積極切入的大公司,是台灣市值排名前20大的玉山金控,科技長張智星就坦言,GPU的缺貨和漲價導致成本提升,「但還是得做」,因為生成式AI能提升工作效率和決策速度,而玉山金坐擁龐大數據,為了保障機密資料不外洩,以及活用資料的專業性,必須自己訓練模型。例如能夠推薦適合的金融產品的AI、回答公司專屬問題的Chatbot、能夠辨識文件內容轉為數據的模型,都會用到第三方業者難以掌握的資料量。 企業有需求,但GPU處於短缺狀態,加上過高的訓練成本,企業開始轉向靠軟體技術來優化GPU運算能力、將閒置資源進行更有效率的分配運用。
◆ 優化使用效率:把難以拆分的GPU資源虛擬化,變成能自由調度、拆分或重組的虛擬GPU,就可以按照工作負載自由分配用量。
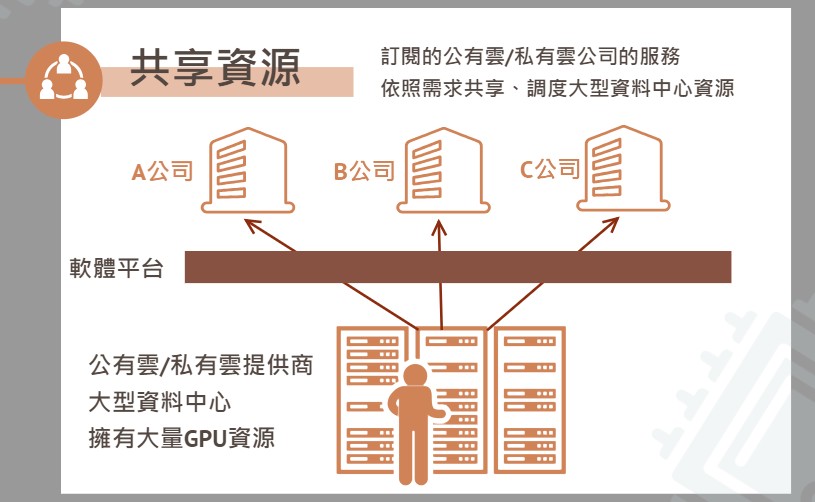
◆ 共享資源:訂閱公有雲/私有雲公司的服務,依照公司需求量,和其他企業共享、調度大型資料中心資源。
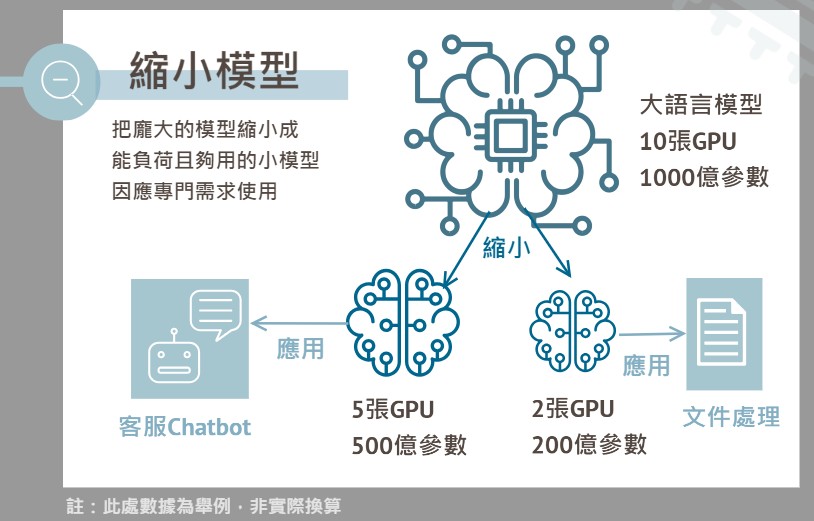
◆ 縮小模型:把龐大的AI模型縮小成企業能負荷的小模型,因應專門需求使用。 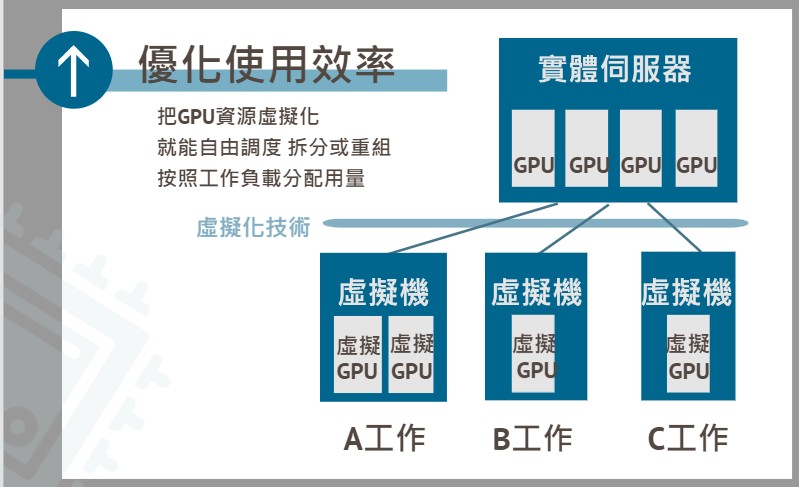
「現在企業很多是捧著錢在觀望或測試,最怕花下去了結果效率很差。」吳昕益分享觀察,企業不只單純要求導入,還希望效果快又好,一旦做了,就絕不能落後對手。當硬體資源有限,能靠軟體力榨出多少AI能量,將會是短期內AI大戰的關鍵武力。
轉貼自: bnnext.com
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應