
摘要: During these last months I spent a lot of my time building and assembling my own entry-level HFT syst

▲圖片來源:towardsdatascience
Introduction
Let’s start with the question:
What is the rationale of an High-Frequency trading system?
To make a HFT system you have to assume that the hypothesis: “there are market inefficiencies” is true. Since everybody is looking at the market at the same time, there will be a group of individuals, which figure out these inefficiencies (e.g. using statistics) and try to compensate them. This means that the longer you wait, the lower the probability you have of catching that inefficiency before its corrected. There are different types of inefficiencies on different time windows, i.e. the smaller the time frame you are looking at the more predictable the inefficiency is going to be and more competition you are going to have (assuming you are not able to find inefficiencies that no one else is looking at, since I never achieved this, I can’t talk about it).
Why build an HFT system for cryptocurrencies?
In my opinion the standard asset markets are quite rotten. Why? Well if you try to get raw live access to market data as a singular individual you will find that it is hard (nobody will give it to you for free, and if they do I can assure you that you will be competing against people who have way better access than you). Most of the cryptocurrencies currency exchanges “borrowed” the already built infrastructures for standard asset markets and their FIX API’s have exactly the same structure as the ones present on standard asset markets. Also, since there is a lot of competition on cryptocurrency exchanges you will find that the commissions you have to pay for transacting these instruments are way more competitive than on regular market. For example, you can find brokers which will pay you for bringing liquidity to the market (something unthinkable for a single individual on the regular asset industry).
Why do you need raw access to the market? This question is answered with a machine learning motto:
Garbage in, garbage out
Also, if you want to perform any type of quantitative analysis you do have to control everything on the system, i.e., you want the analysis you make to be done on the same data aggregation platform you are going to use. When you build a machine learning model you assume that their prediction is valid within a set of boundary conditions, the more you violate these conditions the less valid your prediction is going to be. Thus the best alternative you have is to have the broker streaming every transaction to you(or orderbook change) as fast as you can.
Simplified overview of the system
For reasons I’m going to explain afterwards an HFT system has to have a huge tolerance to faults. When I figure this out, I adopted a micro service architecture, since for me it is the best way to ensure a multi-component system is fault tolerant and scalable. I can assure you that when you are trading live, your system will have unforeseen faults (some of them will be third-party related, e.g. Distributed Denial-of-service (DDOS) attacks to the broker. Yes, this happens). When you’re using a micro-service architecture, when a service fails, you have schedulers that try to reboot the service immediately, and this is a very elegant solution, when trying to build such system alone.
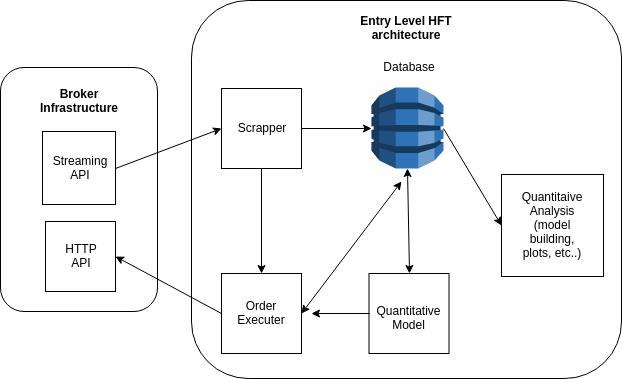
▲Simplified diagram of an entry level HFT architecture(來源:towardsdatascience)
Brief description of the components:
- Database: High density time series database which needs to be able to cope with a hundreds of thousands of data insertions by day. (Tip: pick one of those IOT database marvels that are around). Also needs to be scalable so it can perform very high speed re-sample in an immutable and distributed fashion.
- Scrapper: Inserts the newly streamed data to the database
- Quantitative Model: a quantitative model that signals when alpha is present
- Order Executer: picks up the signals of the Quantitative Model and interacts with the market. Sometimes markets are not liquid, or your strategy has to meet some type of slippage requirements. Thus, to make your system immutable it is better to have a microsystem which tries to execute your positions in the best way possible, this allows you to save up commissions, e.g., instead of using market orders you now have the possibility of executing limit orders which will take some time to be consumed and might need adjustment according to market liquidity.
- Quantitative Analysis: set of tools you have to develop to make models. Since these are fed with data from your infrastructure you have a much better way to ensure the boundary conditions of your system. E.g. you cannot guarantee you will have full market access in high volatile market conditions, thus by building your infrastructure you have a way to measure exactly what happens, when it happens, and log it.
Why adopt a micro service architecture like this? Well, sometimes your scrapper will fail due to broker outages (in high volatile situations there are malicious agents which start DDOS’ing to make market access more difficult for others). I’m inferring it is a DDOS attacks, but to be more correct, lets call it broker unavailability. This is what the market look like when it is efficient (note that these plots are not resampled, in reality, every transaction withing this time window is plotted):
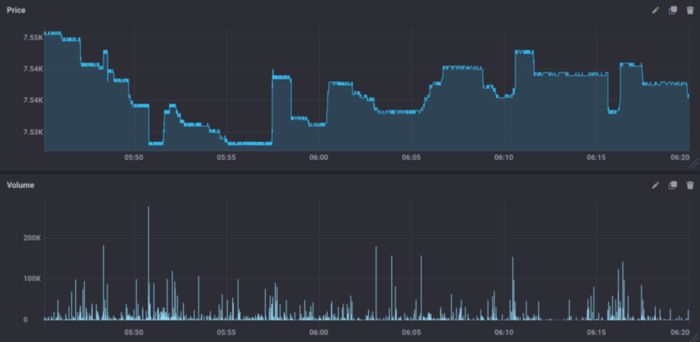
▲Efficient Market with nice spreads(來源:towardsdatascience)
Market highly inefficient with broker unavailability (notice that the y-axis scale is a magnitude bigger on this next picture):
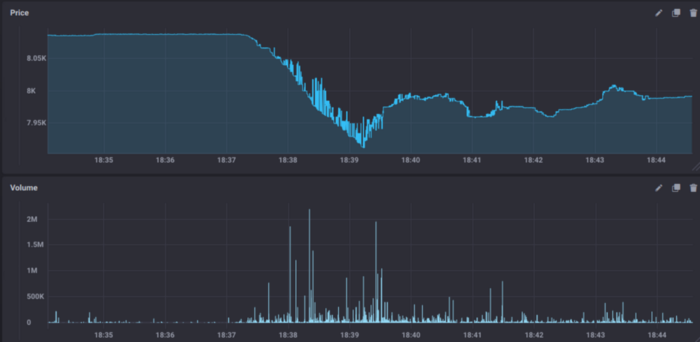
▲Inefficient Market(來源:towardsdatascience)
You can see in the last picture that in a small time window there were huge openings on spread. This happened due to an unavailability of the broker. Since algorithms were not able to place regular limit orders, bringing stability and liquidity to the markets, some high market orders were given (these are accepted regardless market conditions, but with no guarantees on what price you are going to get), opening the spread up by consuming existing limit orders.
A more detailed architecture overview
I will try to do a more detailed overview of this system and explain some of the design choices. The application I suggest for developing the services is Docker. Docker provides very nice managing tools and allows you to make an easier deploy in case you want to use a cluster such has Kubernetes.
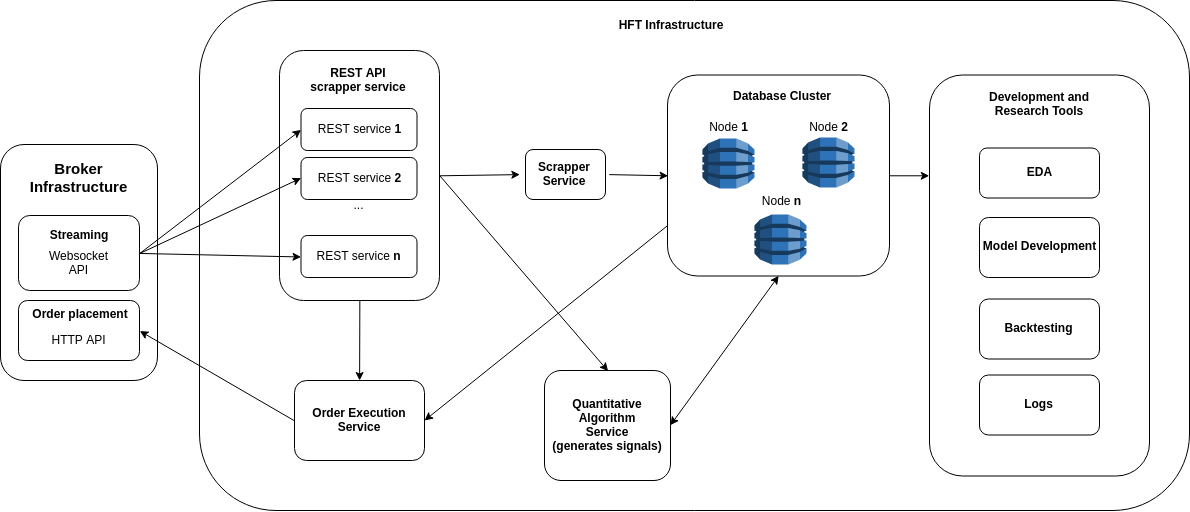
▲Detailed architectural design of an entry level HFT system(來源:towardsdatascience)
- REST API scrapper service: this service has a buffer of the recent market transactions, quotes and orderbooks provided by the broker’s Websocket API through streaming. The reason it has multiple workers is to mitigate the brokers infrastructure outages (if the brokers servers starts to get clogged down, which happens quite sometime, having multiple redundant workers rises you chances of getting all the messages through). E.g. the broker server might start to drop some connections in order to keep its workload running, if you have more workers you have a higher probability of keeping at least one connection while the already dropped workers reboot. You also have the chance of having multiple services running in multiples IP’s, which will bring you even more redundancy.
- Scrapper Service: the scrapper service collects the information posted on the REST API and inserts it into the database. It has the ability to hop through the multiple REST services and in case it detects a faulty behavior, trigger its restart.
- Order Execution Service: grabs the signals to perform an action from a table on the database and initiates its execution, by doing a market order or a limit order (depending on the specifications of the model). It also has the ability to hop through the multiple REST services.
- Quantitative Algorithm Service: has the model implementation and uses data collected on the database to generate the trading signals.
- Database cluster: Receiving raw data from the market requires high bandwidth data transfers. Re-sampling this data can be quite intensive and since you want the same database for development and production you do need to have high throughput.
- Development and Research Tools: by developing your models on the same system you ensure a better quality at keeping the necessary boundary conditions met. After all, its your data now, and you know exactly how long you it took you to receive it and treat it.
Why are the REST API and scrapper services separated?
This decision is based to enhance the speed of the system and ensure 24/7 system reliability, e.g. when you decide you want to open or close a position, you don’t want to be constantly querying the database, by querying the REST API which stores the information directly on RAM (lowering the hard-disk overhead) you are able to achieve higher pooling frequencies (this also greatly depends on how far you are from the exchange and the programming language chosen). If a REST service fails for some unknown reason you can just restart, not losing any of the ongoing data stream while having enough time to safely reboot it. There is a difference from triggering a trading signal and trying to execute the trade. And you do want to execute the trade as fast as possible.
Conclusion
I could keep going on going for hours (specially talking about the bad experiences I had while trying to implement ML on time-series, lets leave that for another blog-post), but that is enough for today. I hit a lot of bottlenecks while achieving such an architecture while trying to achieve the best boundary conditions for the predictions my models were making. This was a voyage to get the best data possible while achieving 24/7 reliability.
轉貼自Source: towardsdatascience
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應