

大數據輿情情感分析,如何提取情感並使用什麼樣的工具?(貼情感標籤)
by 崔維福
情感分析是學術領域研究多年的課題,用google學術搜索可以找到很多paper,基本的方法上有基於詞典規則的方法、語言文法的方法,此外還有分類器以及近幾年比較火的深度學習的方法(稍後有詳細介紹)。
各類paper是有一定的借鑒意義的,不過這主要是學術界在單個問題上的細化,要真正從研究領域落地到大數據的處理還有很多工作要做。
一、工程上的處理流程
工程上的處理流程具體包括以下幾個方面:
1、情感分析任務的界定
在進行情感分析任務的界定時,要弄清楚工程的需求到底是什麼;要分析文本的哪個層面上的情感,比如篇章、段落、句子、短語、詞等粒度;是不是要分析所有的文本還是分析其中的部分文本;准許的錯誤誤差是在個什麼範圍內等。
2、情感分析標準的製定
在實際的企業應用中往往要根據行業的特點來製定一些情感分析的標準,甚至要從客戶的立場中去建立標準。根據國雙實際接觸客戶的經驗,在行業上建立標准後,還需要再具體跟客戶做一些適度調整。
3、 語料數據加工、詞典加工
有了上一步的工作, 接下來進行加工語料或者字典的總結。這一步中不同的方法要做的工作不同,基本上是鋪人力的工作,難點是讓各個語料加工人員能協調一致,執行統一的標準(通常會在這個過程中還會反作用到第二步情感分析標準的製定,因為看到實際數據後會發現標準總會有一些模糊地帶)
4、根據數據特徵、規模等選擇合適的方法,並評測方法的優劣
工程中的方法並不是單一的方法,想用一個方法或者模型來解決各類數據源上的問題是不可能的。想要做出好的效果一定是採用分而治之的思想,比如,能用規則精準過的就不需要用分類器。
當應用在實際產品時,最好能結合產品的垂直特點,充分利用垂直行業的特性,比如在金融行業、汽車行業,它們一定有自己的行話,這些行話具有非常明顯的規則或者特徵。
二、情感分析方法及工具
情感分析對象的粒度最小是詞彙,但是表達一個情感的最基本的單位則是句子,詞彙雖然能描述情感的基本信息,但是單一的詞彙缺少對象,缺少關聯程度,並且不同的詞彙組合在一起所得到的情感程度不同甚至情感傾向都相反。所以以句子為最基本的情感分析粒度是較為合理的。篇章或者段落的情感也可以通過句子的情感來計算。
現階段關於情感分析方法主要有兩類:
(一)、基於詞典的方法:
基於詞典的方法主要通過制定一系列的情感詞典和規則,對文本進行拆句、分析及匹配詞典(一般有詞性分析,句法依存分析),計算情感值,最後通過情感值來作為文本的情感傾向判斷的依據。
做法:
基於詞典的情感分析大致步驟如下:
- 對大於句子力度的文本進行拆解句子操作,以句子為最小分析單元;
- 分析句子中出現的詞語並按照情感詞典匹配;
- 處理否定邏輯及轉折邏輯;
- 計算整句情感詞得分(根據詞語不同,極性不同,程度不同等因素進行加權求和);
- 根據情感得分輸出句子情感傾向性。
如果是對篇章或者段落級別的情感分析任務,按照具體的情況,可以以對每個句子進行單一情感分析並融合的形式進行,也可以先抽取情感主題句後進行句子情感分析,得到最終情感分析結果。
參考及工具:
1. 常見英文情感詞庫:GI(The General Inquirer)、sentiWordNet等;
2. 常見中文情感詞庫:知網、台灣大學的情感極性詞典;
3. 幾種情感詞典構建方法:基於bootstrapping方法的Predicting the semantic orientation of adjectives及Determining the sentiment of opinions兩種最為經典的詞典構建方法。
(二)、 基於機器學習的方法:
情感詞典準確率高,但存在召回率比較低的情況。對於不同的領域,構建情感詞典的難度是不一樣的,精準構建成本較高。另外一種解決情感分析的思路是使用機器學習的方法,將情感分析作為一個有監督的分類問題。對於情感極性的判斷,將目標情感分為三類:正、中、負。對訓練文本進行人工標註,然後進行有監督的機器學習過程,並對測試數據用模型來預測結果。
處理過程:
基於機器學習的情感分析思路是將情感分析作為一個分類問題來處理,具體的流程如下:
1、 文本預處理
文本的預處理過程是使用機器學習作用於文本分類的基礎操作。由於文本是非結構化數據及其特殊性,計算機並不能直接理解,所以需要一系列的預處理操作後,轉換為計算機可以處理的結構化數據。在實際分析中,文本更為複雜,書寫規範也更為隨意,且很有可能摻雜部分噪聲數據。整體上來說,文本預處理模塊包括去噪、特徵提取、文本結構化表示等。
特徵抽取:中文最小語素是字,但是往往詞語才具有更明確的語義信息,但是隨著分詞,可能出現詞語關係丟失的情況。n-元文法正好解決了這個問題,它也是傳統機器學習分類任務中最常用的方法。
文本向量化:對抽取出來的特徵,向量化是一個很重要的過程,是實現由人可以理解的文本轉換為計算機可以處理數據的重要一步。這一步最常用到的就是詞袋模型(bag-of-words )以及最近新出的連續分佈詞向量模型(word Embedding)。詞袋模型長度為整個詞表的長度,詞語對應維度置為詞頻,文檔的表示往往比較稀疏且維度較高。Embedding的表示方式,能夠有效的解決數據稀疏且降維到固定維度,更好的表示語義信息。對於文檔表示,詞袋模型可以直接疊加,而Embedding的方法可以使用深度學習的方法,通過pooling得到最終表示。
特徵選擇:在機器學習分類算法的使用過程中,特徵好壞直接影響機器的準確率及召回率。選擇有利於分類的特徵,可以有效的減少訓練開支及防止模型過擬合,尤其是數據量較大的情況下,這一部分工作的重要性更加明顯。其選擇方法為,將所有的訓練語料輸入,通過一定的方法,選擇最有效的特徵,主要的方法有卡方,信息熵,dp深層感知器等等。
目前也有一些方法,從比句子粒度更細的層次去識別情感,如基於方面的情感分析(Aspect based Sentiment Analysis),他們從產品的評價屬性等更細粒度的方面對評價主體進行情感傾向性分析。
2、分類算法選擇
文本轉換為機器可處理的結構後,接下來便要選擇進行機器學習的分類算法。目前,使用率比較高的是深度學習(CNN,RNN)和支持向量機(SVM)。深度學習的方法,運算量大,準確率有一定的提高,所以都在做這方面的嘗試。而支持向量機則是比較傳統的方法,其準確率及數據處理能力也比較出色,很多人都在用它來做分類任務。
參考及工具:
1. svm分類libsvm
2. python 機器學習工具scikit-learn
3. 深度學習框架:Tensorflow、Theano
本文選自國雙商業市場在知乎的回答。
轉貼自: 36大數據

交易中的大數據歸誰所有?
摘要: 大數據交易,大數據商品化,必然會涉及到一系列法律問題,如大數據所有權、隱私權、版權等,其中所有權問題最為模糊,至今無明確法律法規予以清晰規定。交易的所謂大數據的所有權究竟歸誰?

卞中佩/大數據內爆麥當勞?
摘要: 作為速食業的龍頭,麥當勞是創新的標竿,但樹大招風,也是被各種不滿鎖定伺候的焦點。麥當勞成功引領飲食革命風潮,將製作餐點的過程標準化、去技術化,不再需要聘請廚師,僅僅需要雇用部分工時員工,節省了龐大的成本,加上透過...

菜鳥眼中的大數據與汽車金融
摘要: 不知道從什麼時候開始,“大數據”這個詞不斷從朋友圈,微博及各種傳媒渠道侵占到我們的視覺與聽覺,身邊也不斷有各種版本的“大數據”概念,恍惚一夜之間大數據就變成了我們身邊炙手可熱的資源,在金融類...

大數據:金融領域的變局者
摘要: 無論從商業還是技術視角來看,“大數據”都引發了很多爭議。很難分辨何為真實,何為炒作。大數據為金融機構研發創新性的方案提供了很大的潛力,並可能為其帶來顯著價值。為了能夠攫取價值,金融機構必須藉助大數據更
互聯網+金融的標準體系
摘要: 我國金融業是較早踐行“互聯網+”的行業之一,在短短幾年內,我國快速湧現出第三方網絡支付、互聯網小額貸款、P2P貸款、股權眾籌等新興互聯網金融業態,而銀行、證券、保險等傳統金融機構也在應用互聯網技術創新產品...
從銀行、保險到證券,揭開大數據在金融行業的應用
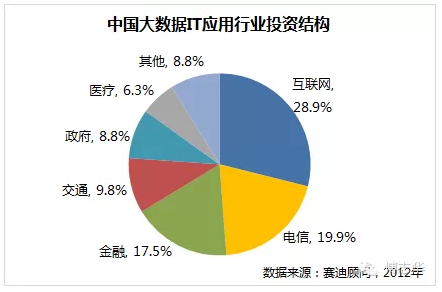
摘要: 數據顯示,中國大數據IT應用投資規模以五大行業最高,其中以互聯網行業佔比最高,佔大數據IT應用投資規模的28.9%,其次是電信領域(19.9%),第三為金融領域(17.5 %),政府和醫療分別為第四和第五。根據國際知名諮 ...
大數據下供應鏈金融發展的趨勢
摘要: 大數據是當下最熱的詞彙。在互聯網條件下,信息量爆炸式增長,如果我們不能獲取、整理和應用這些信息和數據,就有可能在很短的時間內落後,甚至被拋棄。在供應鏈金融服務領域,更是如此。一、供應鏈金融服務的現狀供 ...

金融互聯網與金融大數據:在變革中悄然孕育的巨大機遇(上)
摘要: 投資要點:銀行IT投資:總量巨大,增速穩定,市場分散。 2013年銀行業IT投資額佔金融行業IT總投資的近80%。得益於銀行利潤的增長和信息技術的飛速發展,我國銀行業IT投資額保持穩定增長的態勢,從2008年的500億元增長...
YOU MAY BE INTERESTED
