online gambling singapore
online gambling singapore
online slot malaysia
online slot malaysia
mega888 malaysia
slot gacor
live casino malaysia
online betting malaysia
mega888
mega888
mega888
mega888
mega888
mega888
mega888
mega888
mega888
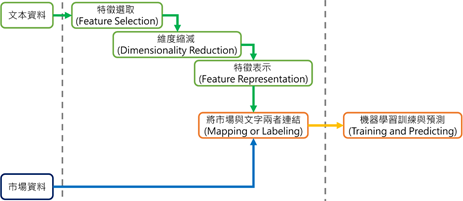
Visualization
摘要: 在本文中,我們蒐集了批踢踢實業-Stock 版,從2008/1/18 至 2017/3/21 日共69890 篇文章,以及各大報社財金相關新聞,從2000/2/13 至 2016/6/29 日共131,741 篇新聞,首先以結巴套件進行中文斷詞,再以謝委霖財金相關辭庫計算每篇文章的情緒字詞比例,以利輿情探勘。
摘要: 從眾為人們基於社會規範、群體意識所產生的行為反應。最著名的社會實驗就是當一個人盯著天空望時,其他人也會湊過來一起望著天空,既使當初的人走離開,剩下的人依然會持續這一動作。近年來,行為財務學發展,研究中融入許多投資人特性變數,從眾便是其中之一。以下將回顧文獻研究中提及之從眾行為。
摘要: 心理學上定義,人類將心理意識投注到某項信息,稱之為「注意力」。資訊增加的情況下,閱聽人並沒有增加接收訊息的時間。隨著行為財務學的興起,眾多學者紛紛將此應用於金融領域以觀察投資人關注的對象及接下來所採取的決策。
摘要: 文字探勘是涉及了統計學、機器學習、自然語言處理等不同領域的新學科,可以應用在輿情分析、文本的分類、聲量分析等
摘要: 在訊息爆炸,且網路成為重要的訊息傳播管道下,由於文字探勘能大量且迅速的瞭解文字訊息中的意涵,而具有相當的商業價值
摘要: 泡沫最主要的特徵是資產的交易價格高於資產的基本面價值,但是在實際進行研究時,若將所有資產的交易價格高於資產的基本面價值的時期定義為泡沫發生時期則會發現,許多看似不是泡沫時期皆被定義為泡沫發生之時期,以下探討我們的泡沫事件篩選方式。
摘要: 為了更好的了解泡沫何時發生,我們接著要了解泡沫如何形成,我們將泡沫形成的原因大致上可以分為三個構面,分別時市場微結構面、投資人行為面以及總體經濟面,進行以下探討。
摘要: 為了更好的了解泡沫何時發生,我們首先要了解如何檢測,或者如何定義泡沫的發生。在以前的研究中已經有很多如何預測泡沫的方法,其中以Fas和理性泡沫模型最為著名,此處根據現有研究對這兩種模型進行詳細敘述。同時本文也敘述了檢測泡沫是否存在的方法GSADF,與傳統的ADF模型參照,該方法可以直接對資產價格進行檢驗,而無需計算基礎價格,能在檢測出爆炸性跑的同時實時檢測泡沫產生的時點。
摘要: 何時會發生泡沫?過去哪些時間算是發生泡沫了?,泡沫的預測對於許多投資人而言或許並不如交易策略開發重要,然而對於投資人而言,泡沫發生所造成的影響卻是非常的劇烈,過去有許多案例是長期利用一些策略賺取穩定的報酬的投資者,僅僅因為一次的泡沫發生便將過去的報酬都退還給市場,甚至傾家蕩產,因此本文重點在於介紹幾種可以預測泡沫的方法,以讓讀者也能藉由泡沫的預測模型,從過去所發生過的泡沫記取教訓,規避泡沫發生所造成的鉅額損失。
摘要: Why understanding the causes of bubbles is important?