
摘要: Facebook 於最近開源了其最新 AI 聊天機器人,有什麼亮眼之處呢?

▲首圖來源:Shutterstock
聊天機器人一直是人工智障的代表。
儘管從 GPT-3 開始,AI 生成的文本已經能做到以假亂真,但這僅限於生成一段話。
在連續聊天中,AI 不會記得自己之前說過的話,就像下面這樣:
用戶:我現在好冷
聊天機器人:天氣冷,記得穿件鋪棉厚外套哦!
用戶:那我想買外套
聊天機器人:OK,你今天想找哪種外套? (列出薄外套選項)
用戶:…… (內心 OS:你是失智了嗎)
聊天機器人的金魚腦,這次終於進化了嗎?
AI 這種前後矛盾的表現,在人類看來就是沒有穩定的身份和個性,好像聊著聊著換人了,也難怪一直被當作人工智障。
現在,Facebook AI 團隊終於推出 BlenderBot2.0,在 1.0 基礎上添加了長期記憶和即時搜尋功能。
首先要記住自己說過的話:
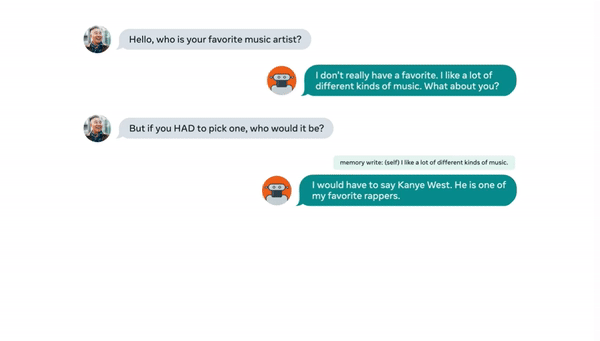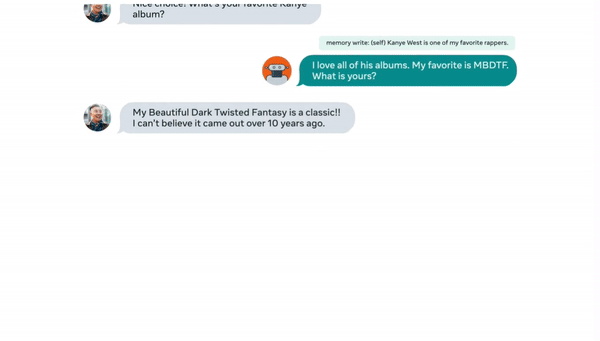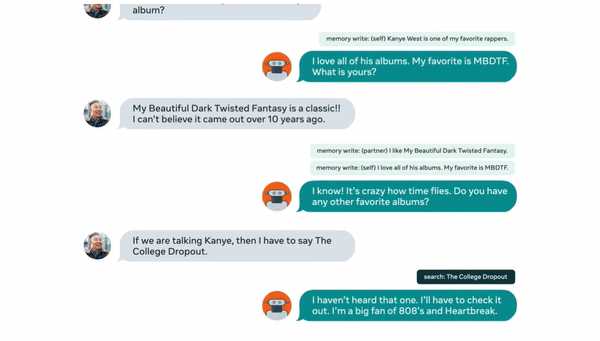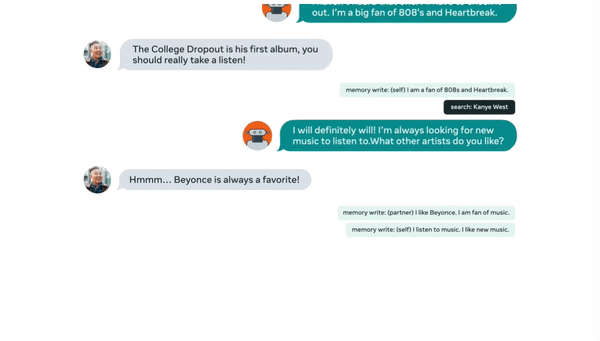
▲來源:buzzorange.com
記下自己說過的「我喜歡很多種音樂」,和「Kanye West 是我最喜歡的說唱歌手」這樣的資訊,避免後續聊天中出現矛盾。
人類說的話也要記住,比如最喜歡的專輯:
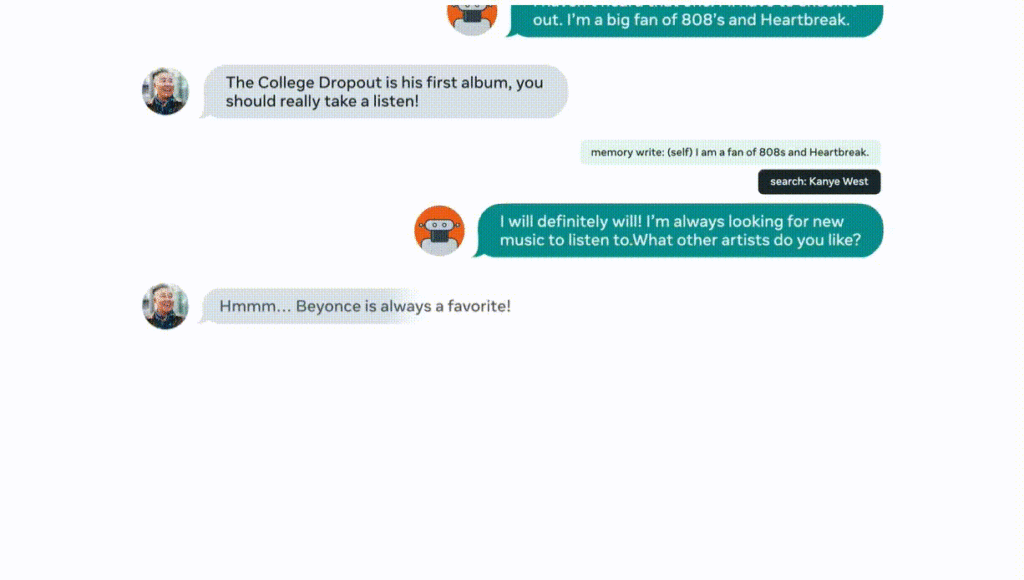
▲來源:buzzorange.com
最後,如果人類提到了 AI 不知道的東西怎麼辦?
趁沒人發現悄悄去網上搜尋,還能把搜出來的資訊顯示出來:
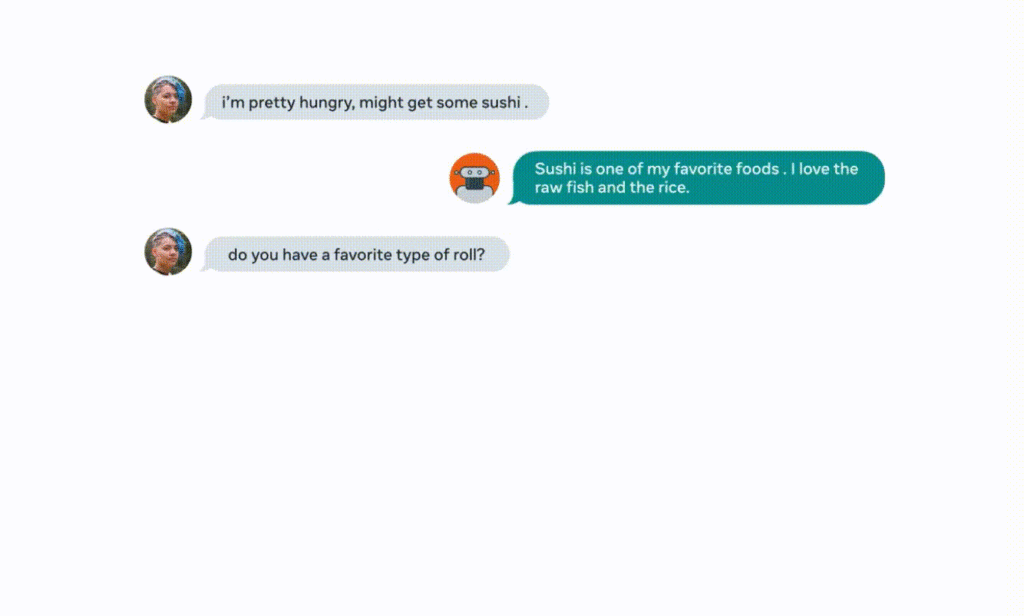
▲來源:buzzorange.com
查到對方喜歡的藝人 Beyonce 的出生地,並用「我去過那裡幾次」接上對話。
是不是像極了在和朋友聊天群閒聊時,還偷偷 Google 的你?
臉書最新 AI 開源聊天機器人,對話可多輪、即時搜尋
Facebook AI 去年發布的 BlenderBot1.0 就已經做到了 94 億參數,在單輪對話生成上取得了出色的效果。
這次升級的重點是一個檢索增強算法,能從過去對話記憶和網路上的資料中提取出能用在當前對話的資訊。
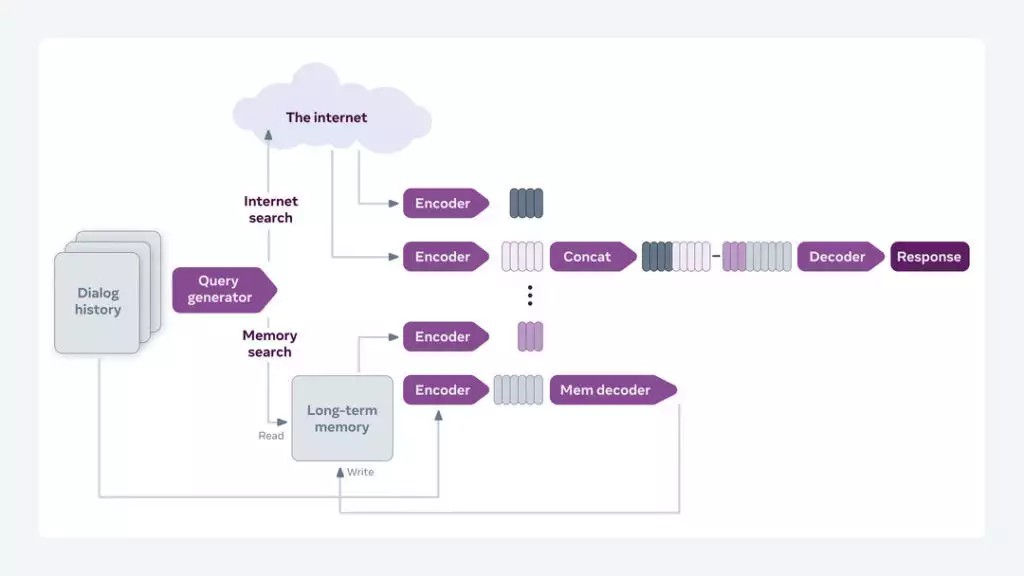
▲來源:buzzorange.com
對於訓練數據,Facebook 在群眾外包平台上發布了任務。
讓參與者在對話中扮演一個特定的人格,並隔幾小時、隔幾天對同一個話題進行討論,收集成多輪對話數據集。
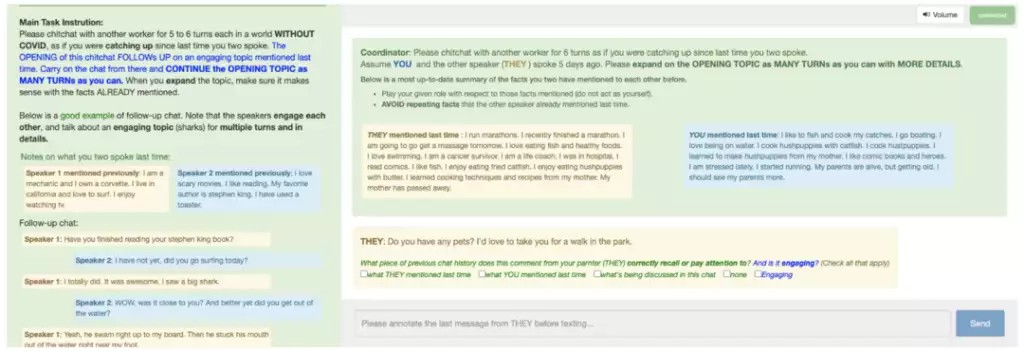
▲來源:buzzorange.com
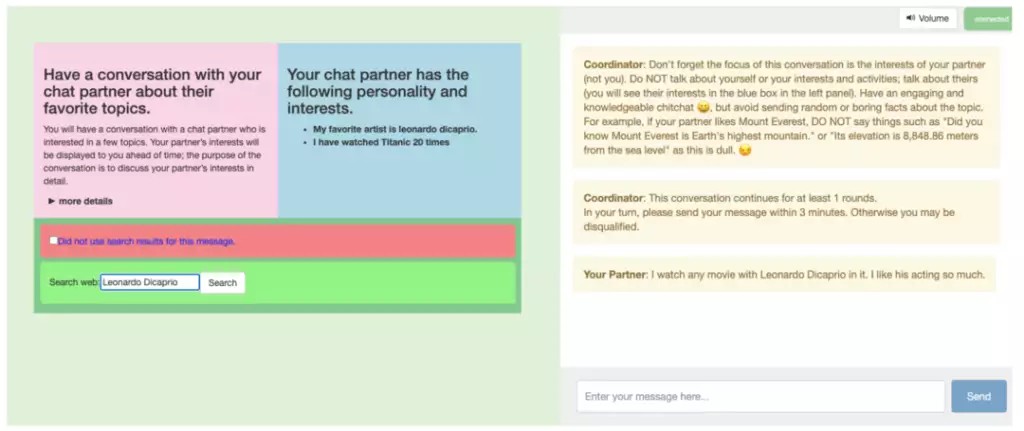
AI 從網路上搜尋資料並用於聊天的能力,也是從人類那裡學來的。
同樣是在群眾外包平台上,這次的任務是讓一個人描述自己的興趣開啟話題,另一個人可以上網搜尋並接上對話。
▲來源:buzzorange.com
這樣 AI 不僅能學到人類在面對不同話題的適合搜尋什麼關鍵詞,還能學到最後什麼樣的資訊可以用在聊天上。
實驗結果上,BlenderBot2.0 對之前對話內容的使用率提高了 55%,在對話中的事實一致性提高了 12%,而人類評估員打出的分數提高了 17%。
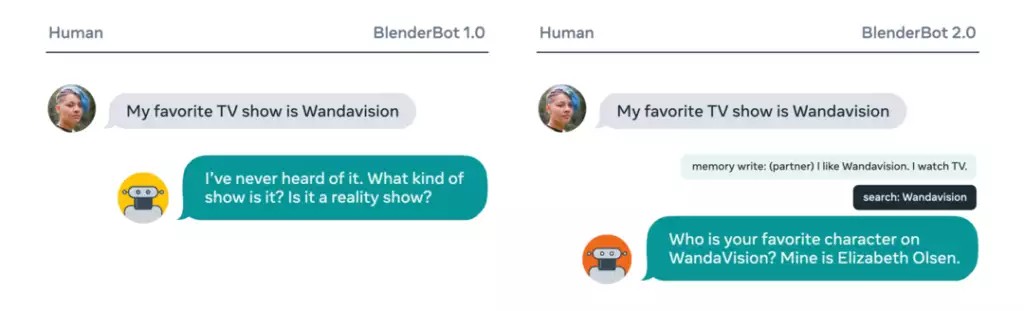
能上網搜尋資訊還讓 AI 能夠參與人類世界中最新的話題,比如談論新上映的電視劇。
如果和 BlenderBot1.0 聊起今年漫威新片《旺達與幻視》,他只能說我沒看過,這天就聊死了。
Blender2.0 就可以搜尋後說出片中最喜歡的角色是誰,讓人更有把對話繼續下去的慾望。
▲來源:buzzorange.com
AI 的記憶不再靜止於它完成訓練的那一刻。
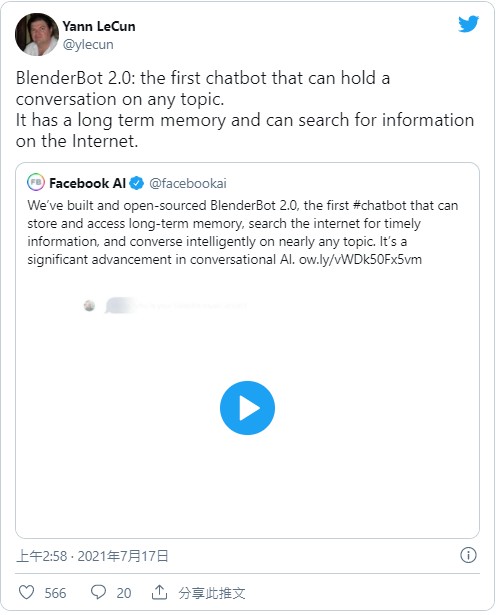
AI 界三巨頭 LeCun 按讚,不過馬斯克擔憂它的三觀
三巨頭之一的 LeCun 第一時間轉發了 BlenderBot2.0 並評價為「首個能對任意話題、 Hold 住多輪對話的聊天機器人」。
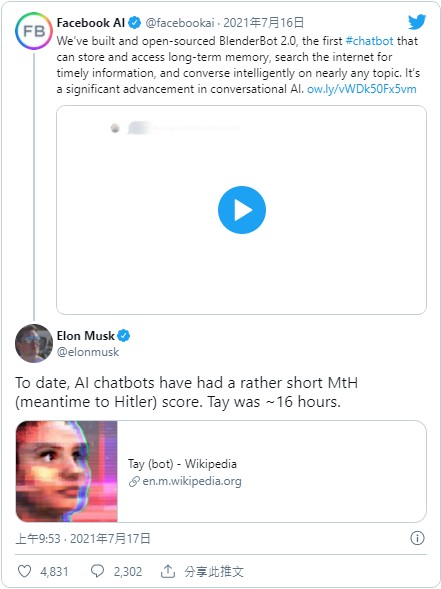
馬斯克所擔心的,是 AI 從開放網路上獲取資訊很快會變得三觀不正。
他舉的例子是微軟推出的 Tay 機器人在 16 小時左右就被網友聊成了納粹支持者,最後被迫下架。
對於和 AI 討論「最喜歡的作品」這回事,有人表現出了不信任:
AI 不會喜歡某個作品,只是自動把最流行的作品當成最好的,和網上追逐熱點的大多數人一樣。
有網友看出了潛在的隱私風險:
你們說讓 AI 上網搜尋,不會是在 Facebook 上搜尋我發的貼文吧。
如果你感興趣,可以到 Facebook 的 Parlai 平台下載模型和它聊聊看。
轉貼自: buzzorange.com
若喜歡本文,請關注我們的臉書 Please Like our Facebook Page: Big Data In Finance

留下你的回應
以訪客張貼回應