
洩密者愛德華·斯諾登(Edward Snowden)還在尋求容身之所的時候,美國國家安全局(NSA)全方位收集電話和電子郵件記錄之事經過他的披露,已經引發了不安和憤怒。奧巴馬當局聲稱,監聽數據帶來了安全,然而左翼和右翼都在譴責這種窺探行為是對隱私的侵犯。
數據不是信息,而是有待理解的原材料。但有一件事是確定無疑的:當NSA為了從其海量數據中“挖掘”出信息,耗資數十億改善新手段時,它正受益於陡然降落的計算機存儲和處理價格。
麻省理工學院的研究者約翰·古塔格(John Guttag)和柯林·斯塔爾茲(Collin Stultz)創建了一個計算機模型來分析之心髒病病患丟棄的心電圖數據。他們利用數據挖掘和機器學習在海量的數據中篩選,發現心電圖中出現三類異常者——一年內死於第二次心髒病發作的機率比未出現者高一至二倍。這種新方法能夠識別出更多的,無法通過現有的風險篩查被探查出的高危病人。
數據挖掘這一術語含義廣泛,指代一些通常由軟件實現的機制,目的是從巨量數據中提取出信息。數據挖掘往往又被稱作算法。
威斯康星探索學院主任大衛·克拉考爾(David Krakauer)說,數據量的增長——以及提取信息的能力的提高——也在影響著科學。 “計算機的處理能力和存儲空間在呈指數增長,成本卻在指數級下降。從這個意義上來講,很多科學研究如今也遵循摩爾定律。”
在2005年,一塊1TB的硬盤價格大約為1,000美元,“但是現在一枚不到100美元的U盤就有那麼大的容量。”研究智能演化的克拉考爾說。現下關於大數據和數據挖掘的討論“之所以發生是因為我們正處於驚天動地的變革當中,而且我們正以前所未有的方式感知它。”克拉勞爾說。
隨著我們通過電話、信用卡、電子商務、互聯網和電子郵件留下更多的生活痕跡,大數據不斷增長的商業影響也在如下時刻表現出來:
你搜索一條飛往塔斯卡魯薩的航班,然後便看到網站上出現了塔斯卡魯薩的賓館打折信息
你觀賞的電影採用了以幾十萬G數據為基礎的計算機圖形圖像技術
你光顧的商店在對顧客行為進行數據挖掘的基礎上獲取最大化的利潤
用算法預測人們購票需求,航空公司以不可預知的方式調整價格
智能手機的應用識別到你的位置,因此你收到附近餐廳的服務信息
大數據在看著你嗎?
除了安全和商業,大數據和數據挖掘在科研領域也正在風起雲湧。越來越多的設備帶著更加精密的傳感器,傳回愈發難以駕馭的數據流,於是人們需要日益強大的分析能力。在氣象學、石油勘探和天文學等領域,數據量的井噴式增長對更高層次的分析和洞察提供了支持,甚至提出了要求。

2005年6月至2007年12月海洋表面洋流示意圖。數據源:海面高度數據來自美國航空航天局
(NASA)的Topex/Poseidon衛星、Jason-1衛星,以及海形圖任務/Jason-2衛星測高儀;重力數據來自NASA/德國航空航天中心的重力恢復及氣候實驗任務;表面風壓數據來自NASA的QuikScat任務;海平面溫度數據來自NASA/日本宇宙航空研究開發機構的先進微波掃描輻射計——地球觀測系統;海冰濃度和速度數據來自被動微波輻射計;溫度和鹹度分佈來自船載、繫泊式測量儀器,以及國際Argo海洋觀測系統。
這幅2005年6月至2007年12月海洋表面洋流的示意圖集成了帶有數值模型的衛星數據。漩渦和窄洋流在海洋中傳送熱量和碳。海洋環流和氣候評估項目提供了所有深度的洋流,但這裡僅僅使用了表層洋流。這些示意圖用來測量海洋在全球碳循環中的作用,並監測地球系統的不同部分內部及之間的熱量、水和化學交換。
在醫學領域,2003年算是大數據湧現過程中的一個里程碑。那一年第一例人類基因組完成了測序。那次突破性的進展之後,數以千計人類、靈長類、老鼠和細菌的基因組擴充著人們所掌握的數據。每個基因組上有幾十億個“字母”,計算時出現紕漏的危險,催生了生物信息學。這一學科借助軟件、硬件以及復雜算法之力,支撐著新的科學類型。
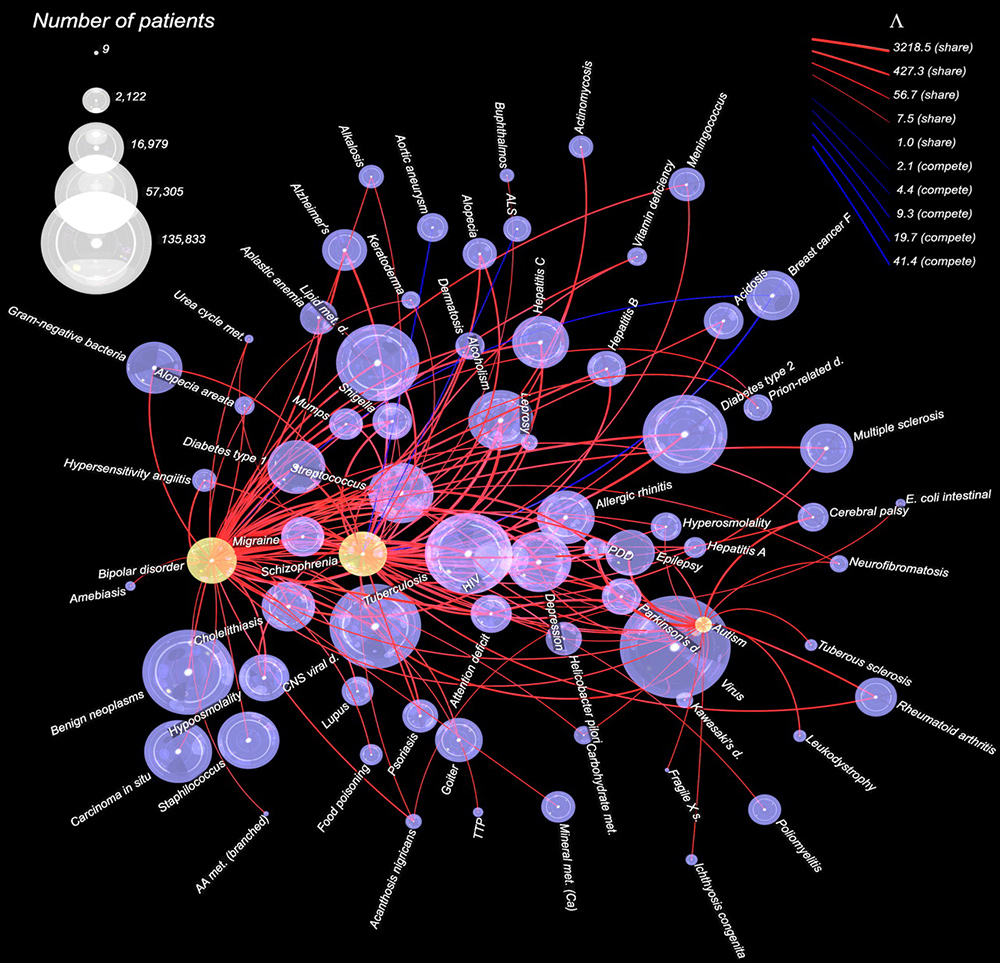
精神障礙通常是具體病例具體分析,但是一項對150萬名病人病例的研究表明,相當多的病人患有超過同一種疾病。芝加哥大學的西爾維奧·康特中心利用數據挖掘理解神經精神障礙的成因以及之間的關係。 “好幾個(研究)團隊都在致力於這個問題的解決。”中心主任安德烈·柴斯基(Andrey Rzhetsky)說,“我們正試圖把它們全部納入模型,統一分析那些數據類型……尋找可能的環境因素。”
另一例生物信息學的應用來自美國國家癌症研究所。該所的蘇珊·霍爾貝克(Susan Holbeck)在60種細胞系上測試了5000對美國食品和藥品管理局批准的抗癌藥品。經過30萬次試驗之後,霍爾貝克說:“我們知道每種細胞系裡面每一條基因的RNA表達水平。我們掌握了序列數據、蛋白質數據,以及微觀RNA表達的數據。我們可以取用所有這些數據進行數據挖掘,看一看為什麼一種細胞係對混合藥劑有良好的反應,而另一種沒有。我們可以抽取一對觀察結果,開發出合適的靶向藥品,並在臨床測試。”
互聯網上的火眼金睛
當醫學家忙於應對癌症、細菌和病毒之時,互聯網上的政治言論已呈燎原之勢。整個推特圈上每天要出現超過5億條推文,其政治影響力與日俱增,使廉潔政府團體面臨著數據挖掘技術帶來的巨大挑戰。
印第安納大學Truthy(意:可信)項目的目標是從這種每日的信息氾濫中發掘出深層意義,博士後研究員埃米利奧·費拉拉(Emilio Ferrara)說。 “Truthy是一種能讓研究者研究推特上信息擴散的工具。通過識別關鍵詞以及追踪在線用戶的活動,我們研究正在進行的討論。”
Truthy是由印第安納研究者菲爾·孟澤(Fil Menczer)和亞力桑德羅·弗拉米尼(Alessandro Flammini)開發的。每一天,該項目的計算機過濾多達5千萬條推文,試圖找出其中蘊含的模式。
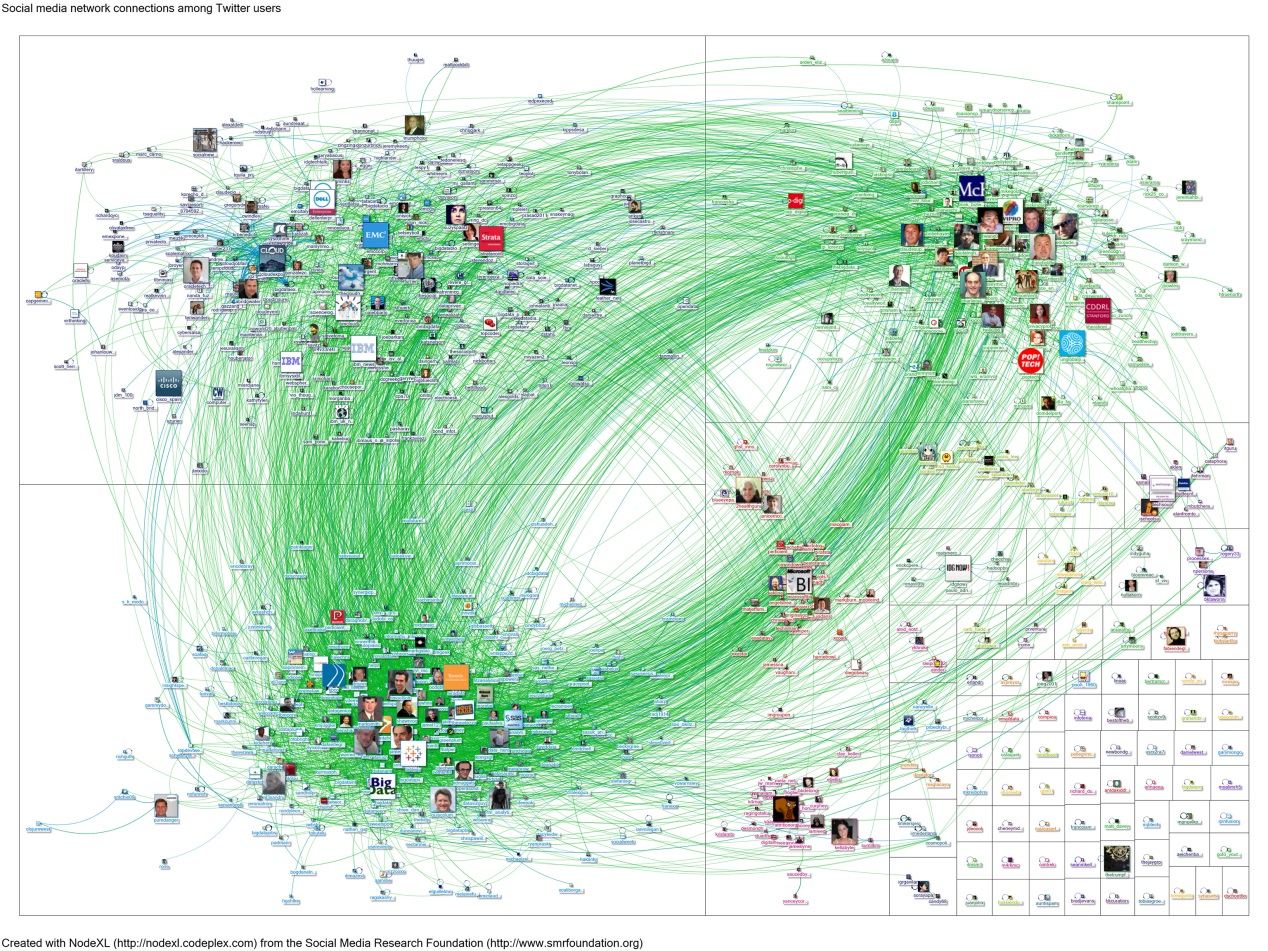
大數據盯著“#bigdata”(意為大數據)。這些是在推特上發布過“bigdata”的用戶之間的連接,用戶圖標的尺寸代表了其粉絲數多寡。藍線表示一次回复或者提及,綠線表示一個用戶是另一個的粉絲。
一個主要的興趣點是“水軍”,費拉拉說:協調一致的造勢運動本應來自草根階層,但實際上是由“熱衷傳播虛假信息的個人和組織”發起的。
2012年美國大選期間,一系列推文聲稱共和黨總統候選人米特·羅姆尼(Mitt Romney)在臉譜網上獲得了可疑的大批粉絲。 “調查者發現共和黨人和民主黨人皆與此事無關。”費拉拉說,“幕後另有主使。這是一次旨在令人們相信羅姆尼在買粉從而抹黑他的造勢運動。”
水軍的造勢運動通常很有特點,費拉拉說。 “要想發起一場大規模的抹黑運動,你需要很多推特賬號,”包括由程序自動運行、反復發布選定信息的假賬號。 “我們通過分析推文的特徵,能夠辨別出這種自動行為。”
推文的數量年復一年地倍增,有什麼能夠保證線上政治的透明呢? “我們這個項目的目的是讓技術掌握一點這樣的信息。”費拉拉說,“找到一切是不可能的,但哪怕我們能夠發現一點,也比沒有強。”
頭腦裡的大數據
人腦是終極的計算機器,也是終極的大數據困境,因為在獨立的神經元之間有無數可能的連接。人類連接組項目是一項雄心勃勃地試圖繪製出不同腦區之間相互作用的計劃。
除了連接組,還有很多充滿數據的“組”:
基因組:由DNA編碼的,或者由RNA編碼的(比如病毒)——全部基因信息
轉錄組:由一個有機體的DNA產生的全套RNA“讀數”
蛋白質組:所有可以用基因表達的蛋白質
代謝組:一個有機體新陳代謝過程中的所有小分子,包括中間產物和最終產物
連接組項目的目標是“從1,200位神經健康的人身上收集先進的神經影像數據,以及認知、行為和人口數據”,聖路易斯市華盛頓大學的連接組項目辦事處的信息學主任丹尼爾·馬庫斯(Daniel Marcus)說。
項目使用三種磁共振造影觀察腦的結構、功能和連接。根據馬庫斯的預期,兩年之後數據收集工作完成之時,連接組研究人員將埋首於大約100萬G數據。
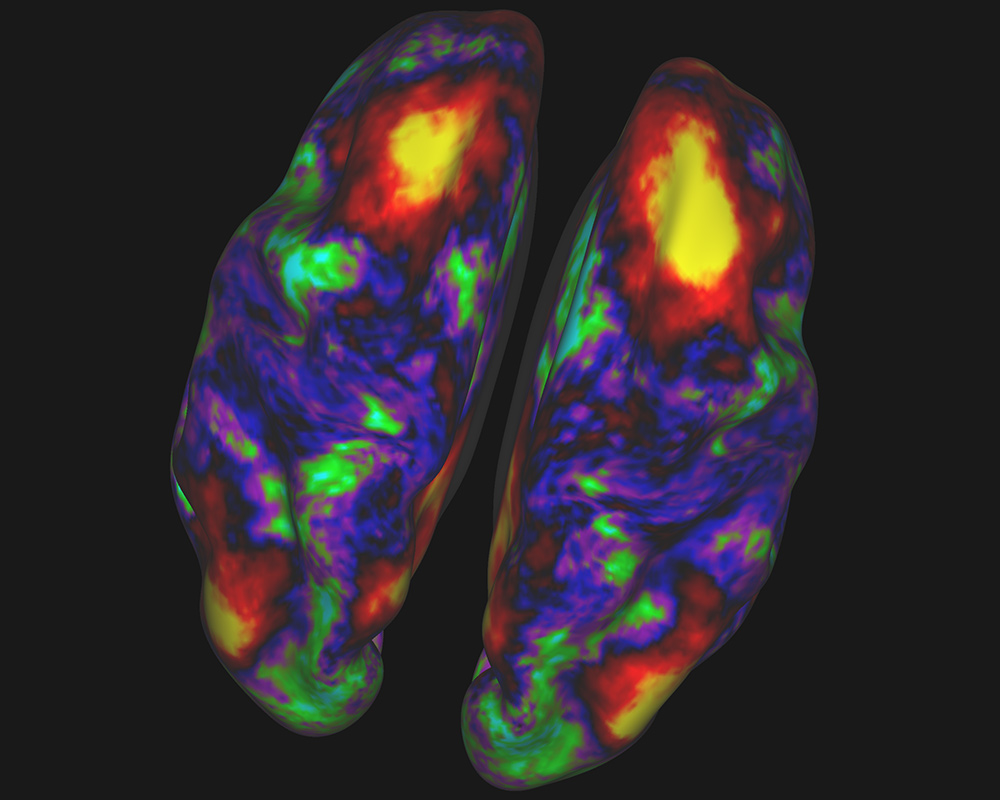
20名健康人類受試者處於休息狀態下接受核磁共振掃描,得到的大腦皮層不同區域間新陳代謝活動的關聯關係,並用不同的顏色表現出來。黃色和紅色區域在功能上與右半腦頂葉中的“種子”位置(右上角黃斑)相關。綠色和藍色區域則與之關聯較弱或者根本沒有關聯。
繪製腦區分佈圖的“分區”是一項關鍵的任務,這些腦區最早於兩到三世紀之前通過對少量大腦染色被識別出來。 “我們將擁有1,200個人的數據,”馬庫斯說,“因此我們可以觀察個人之間腦區分佈的差別,以及腦區之間是如何關聯的。”
為了識別腦區之間的連接,馬庫斯說,“我們在受試者休息時獲取的掃描圖中,觀察腦中的自發活動在不同區域之間有何關聯。”比如,如果區域A和區域B自發地以每秒18個週期的頻率產生腦波,“這就說明它們處於同一網絡中。”馬庫斯說。 “我們將利用整個大腦中的這些關聯數據創建一個表現出腦中的每一個點如何與其他每一個點關聯的矩陣。”(這些點將比磁共振成像無法“看到”的細胞大得多。)
星系動物園:把天空轉包給大眾
星系動物園項目打破了大數據的規矩:它沒有對數據進行大規模的計算機數據挖掘,而是把圖像交給活躍的志願者,由他們對星係做基礎性的分類。該項目2007年啟動於英國牛津,當時天文學家凱文·沙文斯基(Kevin Schawinski)剛剛蹬著眼睛瞧完了斯隆數字巡天計劃拍攝的5萬張圖片。
阿拉巴馬大學天文學教授、星系動物園科學團隊成員威廉·基爾(William Keel)說,沙文斯基的導師建議他完成95萬張圖像。 “他的眼睛累得快要掉出眼窩了,便去了一家酒館。他在那裡遇到了克里斯·林托特(Chris Lintott)。兩人以經典的方式,在一張餐巾的背面畫出了星系動物園的網絡結構。”
星係是一個經典的大數據問題:一台最先進的望遠鏡掃描整個天空,可能會看到2000億個這樣的恆星世界。然而,“一系列與宇宙學和星系統計學相關的問題可以通過讓許多人做相當簡單的分類工作得以解決。”基爾說,“五分鐘的輔導過後,分類便是一項瑣碎的工作,直到今日也並不適合以算法實現。”
星系動物園的啟動相當成功,用戶流量讓一台服務器癱瘓了,基爾說。
斯隆巡天的全部95萬張圖片平均每張被看過60次之後,動物園的管理者們轉向了更大規模的巡天數據。科學受益匪淺,基爾說。 “我的很多重要成果都來自人們發現的奇怪物體,”包括背光星系。
這是星系動物園志願者們發現的差不多2000個背光星系之一。它被其後方的另一個星系照亮。來自背後的光令前景星系中的塵埃清晰可辨。星際塵埃在恆星的形成中扮演了關鍵的角色,但它本身也是由恆星製造的,因此檢測其數量和位置對於了解星系的歷史至關重要。
星系動物園依賴統計學、眾多觀察者以及處理、檢查數據的邏輯。假如觀察某個特定星系的人增加時,而認為它是橢圓星系的人數比例保持不變,這個星係就不必再被觀察了。
然而,對一些稀有的物體,基爾說,“你可能需要40至50名觀察者。”
大眾科學正在發展自己的法則,基爾補充道。志願者們的工作“已經對一個真實存在的重大問題做出了貢獻,是現存的任何軟件都無法實現的。鼠標的點擊不該被浪費。”
這種動物園方法在zooniverse.org 網站上得到了複製和優化。這是一個運行著大約20項目的機構,這些項目的處理對象包括熱帶氣旋、火星表面和船隻航行日誌上的氣象數據。
最終,軟件可能會取代誌願者,基爾說。但是計算機和人類之間的界線是可互換的。比如說超新星動物園項目在軟件學會了任務之後就關閉了。
我們驚訝地得知志願者們積累的龐大數據是計算機學習分類的理想材料。 “一些星系動物園用戶真的很反感這一點。”基爾說,“他們對於自己的點擊被用來訓練軟件表達出明顯的怨恨。但是我們說,不要浪費點擊。如果某人帶來了同樣有效的新算法,人們就不必做那些事情了。”
學習的渴望
人們長久以來改進對圖像和語音的模式識別的努力已經受益於更多的訓練,威斯康星大學麥迪遜分校的克拉考爾說。 “它不僅僅是有所改善,更是有了實際的效果。5到10年之前,iPhone上的Siri是個想都不敢想的點子,語音識別一塌糊塗。現在我們擁有了這樣一批龐大的數據來訓練算法,忽然之間它們就管用了。”

隨著數據及通訊價格持續下跌,新的思路和方法應運而生。如果你想了解你家中每一件設備消耗了多少水和能量,麥克阿瑟獎獲得者西瓦塔克·帕特爾(Shwetak Patel)有個解決方案:用無線傳感器識別每一台設備的唯一數字簽名。帕特爾的智能算法配合外掛傳感器,以低廉的成本找到耗電多的電器。位於加利福尼亞州海沃德市的這個家庭驚訝地得知,錄像機消耗了他們家11%的電力。等到處理能力一次相對較小的改變令結果出現突破性的進展,克拉考爾補充道,大數據的應用可能會經歷一次“相變”。
“大數據”是一個相對的說法,不是絕對的,克拉考爾指出。 “大數據可以被視作一種比率——我們能計算的數據比上我們必須計算的數據。大數據一直存在。如果你想一下收集行星位置數據的丹麥天文學家第谷布拉赫(Tycho Brahe ,1546-1601),當時還沒有解釋行星運動的開普勒理論,因此這個比率是歪曲的。這是那個年代的大數據。”
大數據成為問題“是在技術允許我們收集和存儲的數據超過了我們對系統精推細研的能力之後。”克拉考爾說。
我們好奇,當軟件繼續在大到無法想像的數據庫上執行複雜計算,以此為基礎在科學、商業和安全領域制定決策,我們是不是把過多的權力交給了機器。在我們無法覷探之處,決策在沒人理解輸入與輸出、數據與決策之間的關係的情況下被自動做出。 “這正是我所從事的領域,”克拉考爾回應道,“我的研究對像是宇宙中的智能演化,從大爆炸到大腦。我毫不懷疑你說的。”
資料來源:煉數成金



留下你的回應
以訪客張貼回應