

йБОеОїеНБеєЊеєіпЉМз•ЮзґУзґ≤зµ°иЃКйЭ©дЇЖе§ІйЗПзЪДз†Фз©ґй†ШеЯЯпЉМдЊЛе¶Ви®ИзЃЧж©Яи¶Ци¶ЇгАБи™ЮйЯ≥и≠ШеИ•гАБж©ЯеЩ®дЇЇжОІеИґз≠ЙгАВз•ЮзґУзґ≤зµ°йАЪйБОе§Ъ屧жКљи±°еЊЮжХЄжУЪйЫЖдЄ≠жПРеПЦжЩЇиГљзЪДиГљеКЫзФЪиЗ≥иГљеЄґдЊЖиґЕиґКдЇЇй°ЮзЪДжЩЇиГљгАВеЫ†ж≠§пЉМз•ЮзґУзґ≤зµ°йАРжЉЄжИРзИ≤дЇЖзПЊдї£дЇЇеЈ•жЩЇиГљзЪДеЯЇзЯ≥гАВ
еЊЮ絶еЃЪзЪДжХЄжУЪйЫЖдЄ≠и°НзФЯеЗЇзЪДз•ЮзґУзґ≤зµ°жЮґжІЛе∞НеЕґжЬАзµВзЪДи°®зПЊжЬЙж•µе§ІзЪДељ±йЯњгАВдЄЛи°®дЄ≠е∞НжѓФдЇЖ 2012-2016 еєі ImageNet ILSVRC зЂґи≥љдЄ≠зЪДжХЄз®ЃзЯ•еРНз•ЮзґУзґ≤зµ°гАВеЊЮзґ≤зµ°зЪДжЈ±еЇ¶гАБеПГжХЄйЗПгАБйА£жО•йЗПгАБtop-5 й̃虧зОЗи°®зПЊ 5 е§Ізґ≠еЇ¶е∞НеРДз®Ѓзґ≤зµ°жЮґжІЛеБЪдЇЖжППињ∞гАВ

и°® 1:ILSVRC зЂґи≥љдЄ≠е§Ъз®Ѓз•ЮзґУзґ≤зµ°жЮґжІЛиИЗи°®зПЊзЪДе∞НжѓФ
е¶ВдљХеЊЮ絶еЃЪзЪДжХЄжУЪйЫЖдЄ≠йЂШжХИеЬ∞еЊЧеИ∞еРИйБ©зЪДз•ЮзґУзґ≤зµ°жЮґжІЛйЫЦзДґжШѓдЄАеАЛж•µзИ≤йЗНи¶БзЪДи™≤й°МпЉМдљЖдєЯдЄАзЫіжШѓеАЛйЦЛжФЊжАІйЫ£й°МпЉМзЙєеИ•жШѓе∞Не§ІеЮЛжХЄжУЪйЫЖиАМи®АгАВжЩЃжЮЧжЦѓй†УзЪДз†Фз©ґдЇЇеУ°еЊЧеИ∞з•ЮзґУзґ≤зµ°жЮґжІЛзЪДеВ≥зµ±жЦєеЉПжШѓпЉЪйБНж≠Јзґ≤зµ°жЮґжІЛзЪДеПГжХЄеТМе∞НжЗЙзЪДи®УзЈіпЉМзЫіеИ∞дїїеЛЩи°®зПЊйБФеИ∞жФґзЫКжЄЫе∞СзЪДйїЮгАВдљЖйАЩз®ЃжЦєж≥ХйЭҐиЗ®дЄЙеАЛеХПй°МпЉЪ
1. жЮґжІЛеЫЇеЃЪпЉЪе§ІйГ®еИЖеЯЇжЦЉеПНеРСеВ≥жТ≠зЪДжЦєж≥Хи®УзЈізЪДжШѓзґ≤зµ°жђКйЗНпЉМиАМйЭЮжЮґжІЛгАВеЃГеАСеП™жШѓеИ©зФ®з•ЮзґУзґ≤зµ°жђКйЗНз©ЇйЦУдЄ≠зЪД楃寶䜰жБѓпЉМиАМжХіеАЛи®УзЈійБОз®ЛдЄ≠зЪДз•ЮзґУзґ≤зµ°жЮґжІЛжШѓеЫЇеЃЪзЪДгАВеЫ†ж≠§пЉМйАЩж®£зЪДжЦєж≥ХдЄ¶дЄНиГљеЄґдЊЖжЫіе•љзЪДзґ≤зµ°жЮґжІЛгАВ
2. жЉЂйХЈзЪДжПРеНЗпЉЪйАЪйБО詶йМѓзЪДжЦєж≥ХжРЬ糥еРИйБ©зЪДз•ЮзґУзґ≤зµ°жЮґжІЛйЭЮеЄЄзЪДдљОжХИгАВйАЩдЄАеХПй°МйЪ®зЭАзґ≤зµ°зЪДеК†жЈ±гАБеМЕеРЂжХЄзЩЊиРђзЪДеПГжХЄжЩВжДИзИ≤еЪійЗНгАВеН≥дљњжШѓжЬАењЂзЪД GPUпЉМжѓПеШЧ詶дЄАз®ЃжЈ±еЇ¶з•ЮзґУзґ≤зµ°еЛХиЉТиК±и≤їжХЄеНБе∞ПжЩВгАВи¶БзЯ•йБУпЉМGPU зЫЃеЙНжШѓз•ЮзґУзґ≤зµ°и®УзЈізЪДдЄїеКЫгАВеН≥дљњжУБжЬЙиґ≥姆зЪДзЃЧеКЫиИЗз†Фз©ґдЇЇеУ°пЉМжЙЊеИ∞йБ©еРИжЯРз®ЃжЗЙзФ®зЪДеД™зІАжЮґжІЛдєЯи¶БиК±и≤їжХЄеєіжЩВйЦУпЉМдЊЛе¶ВеЬЦеГПй†ШеЯЯпЉМеЊЮ AlexNet еИ∞ VGGгАБGoogLeNetгАБResNet зЪДиЃКйЭ©гАВ
3. е§ІйЗПзЪДеЖЧй§ШпЉЪе§ІйГ®еИЖз•ЮзґУзґ≤зµ°зЪДеПГжХЄйГљйБОйЗПдЇЖгАВеН≥дљњжШѓеЬЦеГПеИЖй°ЮдїїеЛЩдЄ≠жЬАзЯ•еРНзЪДзґ≤зµ°пЉИдЊЛе¶ВпЉМLeNetsгАБAlexNetгАБVGGпЉЙпЉМдєЯйЭҐиЗ®зЭАе§ІйЗПзЪДе≠ШеД≤еТМи®ИзЃЧеЖЧй§ШзЪДеХПй°МгАВдЊЛе¶ВпЉМжЦѓеЭ¶з¶Пе§Іе≠ЄеНЪе£ЂйЯУйђЖз≠ЙдЇЇ 2015 еєізЪД NIPS иЂЦжЦЗи°®з§ЇпЉМAlexNet дЄ≠зЪДеПГжХЄйЗПеТМжµЃйїЮйБЛзЃЧеПѓеИЖеИ•жЄЫе∞С 9 еАНгАБ3 еАНпЉМдЄФдЄНжРН姱жЇЦ祯зОЗгАВ
зИ≤дЇЖиІ£ж±ЇйАЩдЇЫеХПй°МпЉМжЩЃжЮЧжЦѓй†Уз†Фз©ґеУ°еЬ®йАЩзѓЗиЂЦжЦЗдЄ≠жПРеЗЇдЇЖдЄ≠еЕ®жЦ∞зЪДз•ЮзґУзґ≤зµ°еРИжИРеЈ•еЕЈ NeSTпЉМжЧҐи®УзЈіз•ЮзґУзґ≤зµ°жђКйЗНеПИи®УзЈіжЮґжІЛгАВеПЧдЇЇиЕ¶е≠ЄзњТж©ЯеИґзЪДеХУзЩЉпЉМNeST еЕИеЊЮдЄАеАЛз®Ѓе≠Рз•ЮзґУзґ≤зµ°жЮґжІЛпЉИеЗЇзФЯйїЮпЉЙйЦЛеІЛеРИжИРгАВеЃГиГљиЃУз•ЮзґУзґ≤зµ°еЯЇж֊楃寶䜰жБѓпЉИеђ∞еЕТе§ІиЕ¶пЉЙзФЯжИРйА£жО•еТМз•ЮзґУеЕГпЉМдї•дЊњжЦЉз•ЮзґУзґ≤зµ°иГљењЂйАЯйБ©жЗЙжЙЛй†≠еХПй°МгАВзДґеЊМпЉМеЯЇжЦЉйЗПзіЪдњ°жБѓпЉИжИРдЇЇе§ІиЕ¶пЉЙпЉМеЃГдњЃеЙ™жОЙдЄНйЗНи¶БзЪДйА£жО•еТМз•ЮзґУеЕГеЊЮиАМйБњеЕНеЖЧй§ШгАВйАЩдљњеЊЧ NeST иÚ姆зФЯжИРзЈКжєКдЄФжЇЦ祯зЪДз•ЮзґУзґ≤зµ°гАВдљЬиАЕеАСйАЪйБОеЬ® MNIST еТМ ImageNet жХЄжУЪйЫЖдЄКзЪДеѓ¶й©Чи°®жШОпЉМNeST иÚ姆敵姲зЪДжЄЫе∞Сз•ЮзґУзґ≤зµ°зЪДеПГжХЄйЗПеТМжµЃйїЮйБЛзЃЧйЬАж±ВпЉМеРМжЩВдњЭи≠ЙжИЦзХ•еЊЃжПРеНЗж®°еЮЛзЪДеИЖй°ЮжЇЦ祯зОЗпЉМеЊЮиАМж•µе§ІеЬ∞еЙКжЄЫдЇЖе≠ШеД≤жИРжЬђгАБжО®зРЖйБЛи°МжЩВйЦУиИЗиГљиАЧгАВ
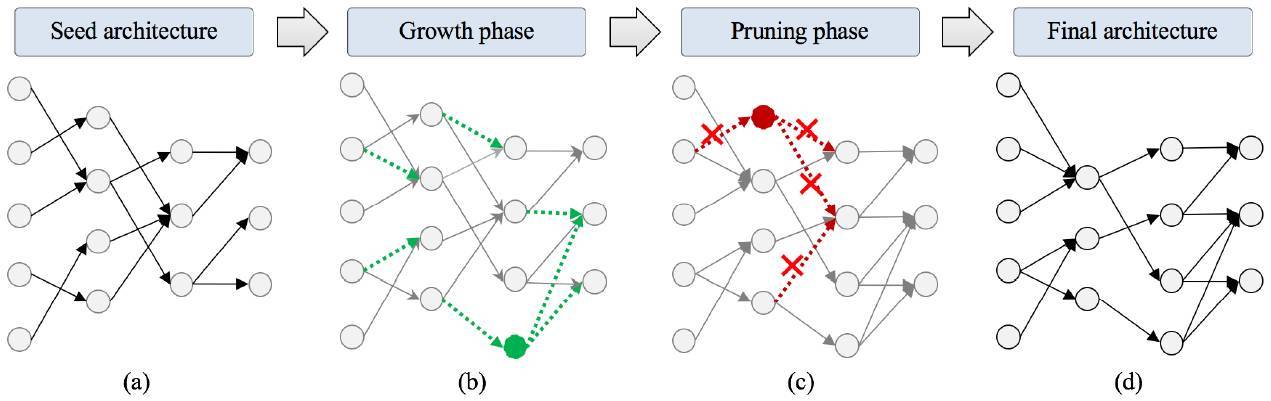
еЬЦ 1пЉЪNeST жЮґжІЛеРИжИРжµБз®ЛзЪДе±Хз§Ї
е¶ВдЄКеЬЦжЙАз§ЇпЉМNeST еЕИеЊЮдЄАз®Ѓз®Ѓе≠РжЮґжІЛйЦЛеІЛпЉИеЬЦ 1aпЉЙгАВз®Ѓе≠РжЮґжІЛдЄАиИђжШѓдЄАз®Ѓз®АзЦПзЪДгАБе±АйГ®йА£жО•зЪДз•ЮзґУзґ≤зµ°гАВзДґеЊМпЉМеЃГеЬ®еЕ©еАЛйА£зЇМйЪОжЃµеРИжИРз•ЮзґУзґ≤зµ°пЉЪ(i) еЯЇж֊楃寶зЪДжИРйХЈйЪОжЃµпЉЫ(ii) еЯЇжЦЉйЗПзіЪзЪДдњЃеЙ™йЪОжЃµгАВеЬ®жИРйХЈйЪОжЃµпЉМжЮґжІЛз©ЇйЦУдЄ≠зЪД楃寶䜰жБѓиҐЂзФ®жЦЉжЉЄжЉЄжИРйХЈеЗЇжЦ∞зЪДйА£жО•гАБз•ЮзґУеЕГеТМжШ†е∞ДеЬЦпЉМеЊЮиАМеЊЧеИ∞жГ≥и¶БзЪДжЇЦ祯зОЗгАВеЬ®дњЃеЙ™йЪОжЃµпЉМз•ЮзґУзґ≤зµ°зєЉжЙњжИРйХЈйЪОжЃµеРИжИРзЪДжЮґжІЛиИЗжђКйЗНпЉМеЯЇжЦЉйЗНи¶БжАІйАРжђ°ињ≠дї£еОїйЩ§еЖЧй§ШйА£жО•иИЗз•ЮзґУеЕГгАВжЬАзµВпЉМеЊЧеИ∞дЄАеАЛиЉХйЗПз•ЮзґУзґ≤зµ°ж®°еЮЛеЊМ NeST еБЬж≠ҐпЉМи©≤ж®°еЮЛжЧҐдЄНжРН姱жЇЦ祯зОЗпЉМдєЯжШѓзЫЄе∞НеЕ®йА£жО•зЪДж®°еЮЛгАВ

зЃЧж≥Х 1 е±Хз§ЇдЇЖеҐЮйХЈ-еЙ™жЮЭеРИжИРзЃЧж≥ХзЪДзі∞зѓАгАВsizeof жПРеПЦеПГжХЄзЄљйЗПпЉМдЄ¶еЬ®й©Чи≠ЙйЫЖдЄК檐詶з•ЮзґУзґ≤зµ°зЪДжЇЦ祯寶гАВеЬ®йА≤и°МеРИжИРдєЛеЙНпЉМжИСеАСеПѓе∞НжЬАе§Іе∞ЇеѓЄ S еТМжЬЯжЬЫжЇЦ祯寶 A йА≤и°МзіДжЭЯгАВдЄЛеЬЦ絶еЗЇдЇЖзЃЧж≥ХдЄїи¶БзµРжІЛгАВ
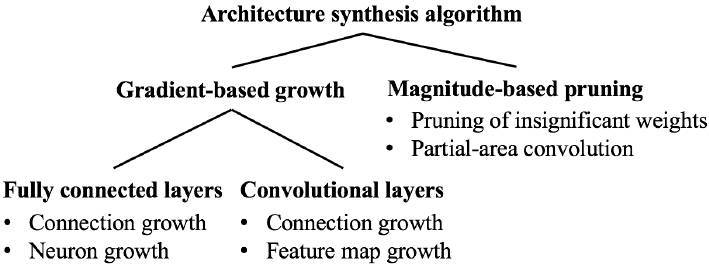
еЬЦ 2. NeST дЄ≠з•ЮзґУзґ≤зµ°зФЯжИРзЃЧж≥ХзЪДдЄїи¶БзµДжИРйГ®еИЖ
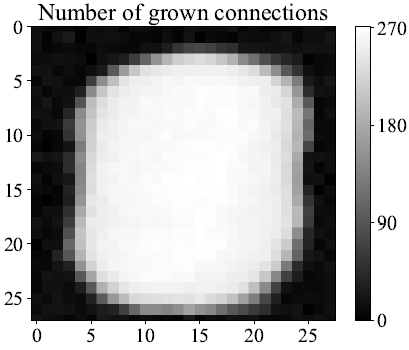
еЬЦ 3. LeNet-300-100 дЄКпЉМеЊЮиЉЄеŕ屧еИ∞зђђдЄА屧дЄКзФЯйХЈзЪДйА£жО•гАВ
и°® 4. MNIST дЄНеРМзЪДжО®е∞Ож®°еЮЛ
дЇЇй°Юе§ІиЕ¶зЪДи§ЗйЫЬзµРжІЛзИ≤зПЊдї£дЇЇеЈ•жЩЇиГљзЪДзЩЉе±ХжПРдЊЫдЇЖзД°жХЄеХУзЩЉгАВз•ЮзґУеЕГж¶ВењµзЪДеЯЇз§ОгАБе§Ъ屧з•ЮзґУзґ≤зµ°зµРжІЛзФЪиЗ≥еНЈз©Нж†ЄйГљжЇРжЦЉе∞НзФЯзЙ©йЂФзЪДж®°дїњгАВжЩЃжЮЧжЦѓй†Уе§Іе≠ЄзЪДз†Фз©ґдЇЇеУ°и°®з§ЇпЉМNeST еЊЮдЇЇиЕ¶зµРжІЛдЄ≠зН≤еЊЧдЇЖдЄЙеАЛжЦєйЭҐзЪДеХУзЩЉгАВ
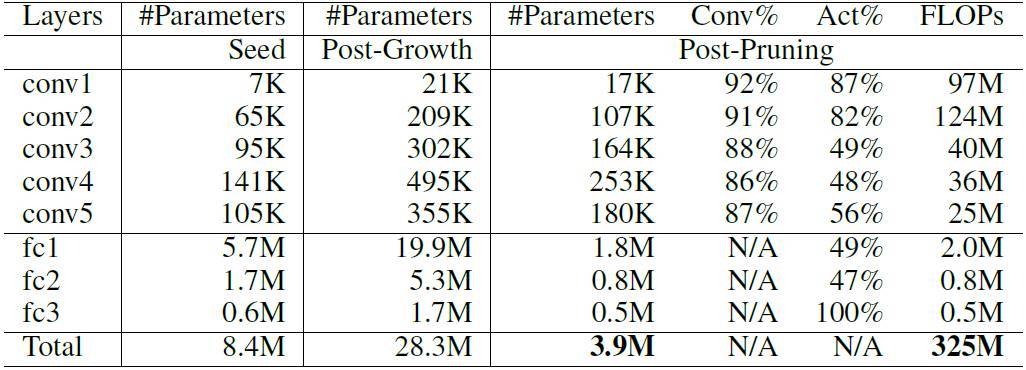
и°® 5. еРИжИРзЪД AlexNetпЉИй̃虧зОЗ 42.76%пЉЙ
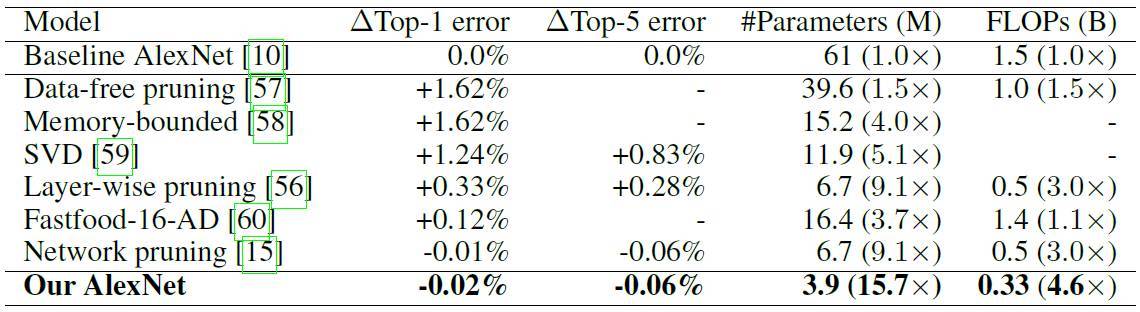
и°® 6. еЬ® ImageNet дЄКдЄНеРМеЯЇжЦЉ AlexNet жО®зРЖж®°еЮЛзЪДи°®зПЊ
й¶ЦеЕИпЉМе§ІиЕ¶дЄ≠з™БиІЄиБѓзєЂзЪДжХЄйЗПеЬ®дЄНеРМзЪДдЇЇй°Юеєійљ°жЃµдЄКжЬЙжЙАдЄНеРМгАВеЬ®еђ∞еЕТеЙЫеЗЇзФЯжЩВпЉМз™БиІЄиБѓзєЂзЪДжХЄйЗПеҐЮйХЈеЊИењЂпЉМеєЊеАЛжЬИеЊМйЦЛеІЛдЄЛйЩНпЉМйЪ®еЊМйАРжЉЄдњЭжМБз©©еЃЪгАВз•ЮзґУзґ≤зµ°еЬ® NeST дЄ≠зЪДе≠ЄзњТйБОз®ЛйЭЮеЄЄжО•ињСжЦЉйАЩдЄАжЫ≤зЈЪгАВжЬАеИЭзЪДз®Ѓе≠Рз•ЮзґУзґ≤зµ°з∞°еЦЃиАМз®АзЦПпЉМе∞±еГПеђ∞еЕТеЗЇзФЯжЩВзЪДе§ІиЕ¶гАВеЬ®зФЯйХЈйЪОжЃµпЉМеЕґдЄ≠зЪДйА£жО•еТМз•ЮзґУеЕГжХЄйЗПеЫ†зИ≤е§ЦзХМдњ°жБѓиАМе§ІйЗПеҐЮйХЈпЉМйАЩе∞±еГПдЇЇй°Юеђ∞еЕТзЪДе§ІиЕ¶е∞Не§ЦзХМеИЇжњАеБЪеЗЇеПНжЗЙгАВиАМеЬ®дњЃеЙ™йЪОжЃµеЃГжЄЫе∞СдЇЖз™БиІЄйА£жО•зЪДжХЄйЗПпЉМжУЇиДЂдЇЖе§ІйЗПеЖЧй§ШпЉМйАЩиИЗеђ∞еЕТ嚥жИРжИРзЖЯе§ІиЕ¶зЪДйБОз®ЛжШѓй°ЮдЉЉзЪДгАВзИ≤дЇЖжЫіжЄЕжЩ∞еЬ∞иІ£йЗЛйАЩдЄАйБОз®ЛпЉМз†Фз©ґдЇЇеУ°еЬ®еЬЦ 12 дЄ≠е±Хз§ЇдЇЖ LeNet-300-100 еЬ®жЦ∞жЦєж≥ХиЩХзРЖйБОз®ЛдЄ≠зЪДйА£жО•жХЄйЗПиЃКеМЦгАВ
зђђдЇМпЉМе§ІиЕ¶дЄ≠зЪДе§ІйГ®еИЖе≠ЄзњТйБОз®ЛйГљжШѓзФ±з•ЮзґУеЕГдєЛйЦУзЪДз™БиІЄйЗНжЦ∞йА£жО•еЉХиµЈзЪДгАВдЇЇй°Юе§ІиЕ¶жѓП姩йГљжЬГжЦ∞еҐЮеТМжЄЕйЩ§е§ІйЗПпЉИйЂШйБФ 40пЉЕпЉЙзЪДз™БиІЄйА£жО•гАВNeST еЦЪйЖТжЦ∞зЪДйА£жО•пЉМеЊЮиАМеЬ®е≠ЄзњТйБОз®ЛдЄ≠жЬЙжХИеЬ∞йЗНйА£жЫіе§ЪзЪДз•ЮзґУеЕГе∞НгАВеЫ†ж≠§пЉМеЃГж®°дїњдЇЖдЇЇй°Юе§ІиЕ¶дЄ≠гАМйЗНжЦ∞йА£жО•е≠ЄзњТгАНзЪДж©ЯеИґгАВ
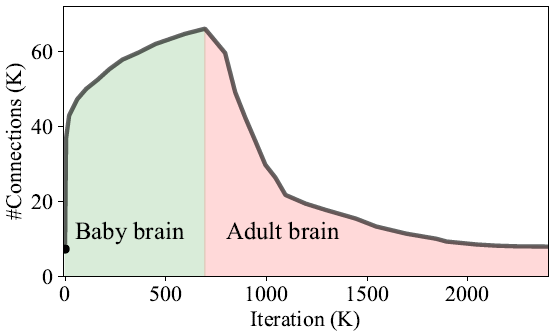
еЬЦ 12. LeNet-300-100 зЪДйА£жО•жХЄиИЗињ≠дї£жђ°жХЄе∞НжѓФ
зђђдЄЙпЉМе§ІиЕ¶дЄ≠еП™жЬЙдЄАе∞ПйГ®еИЖз•ЮзґУеЕГеЬ®жЙАжЬЙжЩВйЦУи£ПйГљжШѓжіїиЇНзЪДпЉМйАЩз®Ѓзό豰襀箱зИ≤з®АзЦПз•ЮзґУеЕГеПНжЗЙгАВйАЩз®Ѓж©ЯеИґеЕБи®±дЇЇй°Юе§ІиЕ¶еЬ®иґЕдљОеКЯиАЧдЄЛйБЛи°МпЉИ20WпЉЙгАВиАМеЕ®йА£жО•зЪДз•ЮзґУзґ≤зµ°еЬ®жО®зРЖдЄ≠е≠ШеЬ®е§ІйЗПзД°жДПзЊ©зЪДз•ЮзґУеЕГеПНжЗЙгАВзИ≤дЇЖиІ£ж±ЇйАЩеАЛеХПй°МпЉМжЩЃжЮЧжЦѓй†УзЪДз†Фз©ґиАЕеАСеЬ® NeST дЄ≠еК†еЕ•дЇЖдЄАеАЛеЯЇжЦЉйЗНи¶БжАІзЪДз•ЮзґУеЕГ/йА£жО•дњЃеЙ™зЃЧж≥ХдЊЖжґИйЩ§еЖЧй§ШпЉМеЊЮиАМеѓ¶зПЊдЇЖз®АзЦПжАІеТМзЈКжєКжАІгАВйАЩе§Іе§ІжЄЫе∞СдЇЖе≠ШеД≤еТМи®ИзЃЧйЬАж±ВгАВ
иЂЦжЦЗпЉЪNeST: A Neural Network Synthesis Tool Based on a Grow-and-Prune Paradigm
иЂЦжЦЗйА£зµРпЉЪhttps://arxiv.org/abs/1711.02017
зЄљзµРпЉЪ
з•ЮзґУзґ≤зµ°пЉИNeural NetworksпЉМNNпЉЙеЈ≤зґУе∞Нж©ЯеЩ®е≠ЄзњТзЪДеРДй°ЮжЗЙзФ®зФҐзФЯдЇЖеї£ж≥Ыељ±йЯњгАВзДґиАМпЉМе¶ВдљХзИ≤е§ІеЮЛжЗЙзФ®е∞ЛжЙЊжЬАеД™з•ЮзґУзґ≤зµ°жЮґжІЛзЪДеХПй°МеЬ®еєЊеНБеєідЊЖдЄАзЫіжЬ™иҐЂиІ£ж±ЇгАВеВ≥зµ±дЄКпЉМжИСеАСеП™иГљйАЪйБОе§ІйЗП詶йМѓдЊЖе∞ЛжЙЊжЬАеД™зЪД NN жЮґжІЛпЉМйАЩз®ЃжЦєеЉПйЭЮеЄЄдљОжХИпЉМиАМзФЯжИРзЪД NN жЮґжІЛе≠ШеЬ®зЫЄзХґжХЄйЗПзЪДеЖЧй§ШзµДзєФгАВзИ≤дЇЖиІ£ж±ЇйАЩдЇЫеХПй°МпЉМжИСеАСжПРеЗЇдЇЖз•ЮзґУзґ≤зµ°зФЯжИРеЈ•еЕЈ NeSTпЉМеЃГеПѓдї•зИ≤絶еЃЪзЪДжХЄжУЪйЫЖиЗ™еЛХзФЯжИРйЭЮеЄЄзЈКжєКзЪДйЂФз≥їзµРжІЛгАВ
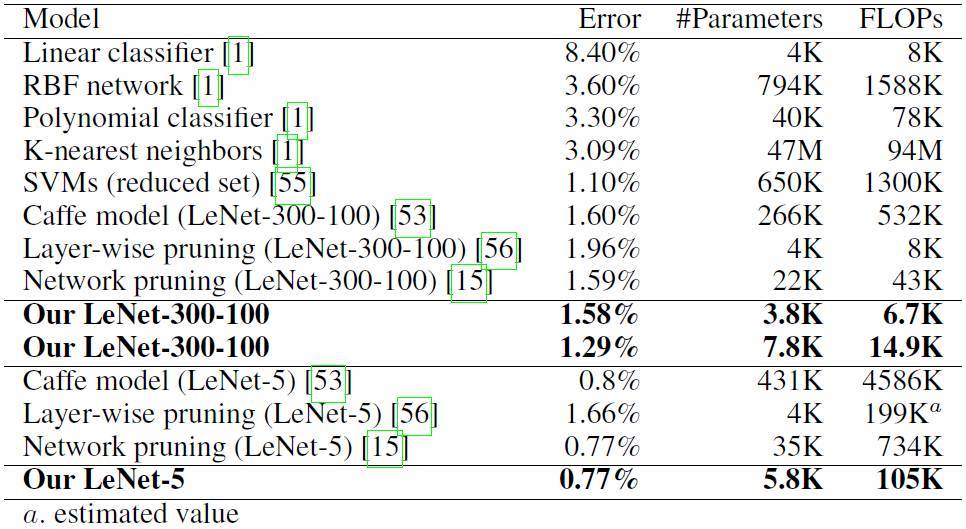
NeST еЊЮз®Ѓе≠Рз•ЮзґУзґ≤зµ°жЮґжІЛйЦЛеІЛпЉМеЃГдЄНжЦЈеЯЇж֊楃寶еҐЮйХЈеТМз•ЮзґУеЕГиИЗйА£жО•зЪДйЗНи¶БжАІдњЃеЙ™дЊЖи™њжХіиЗ™иЇЂжАІиГљгАВжИСеАСзЪДеѓ¶й©Чи≠ЙжШОпЉМNeST иГљдї•е§Ъй°Юз®Ѓе≠РжЮґжІЛзИ≤еЯЇз§ОпЉМзФҐзФЯеЗЇжЇЦ祯иАМе∞Пе∞ЇеѓЄзЪДз•ЮзґУзґ≤зµ°гАВдЊЛе¶ВпЉМе∞НжЦЉ MNIST жХЄжУЪйЫЖпЉМLeNet-300-100пЉИLeNet-5пЉЙжЮґжІЛпЉМжИСеАСзЪДжЦєж≥Хе∞ЗеПГжХЄжЄЫе∞СдЇЖ 34.1 еАНпЉИ74.3 еАНпЉЙпЉМжµЃйїЮйБЛзЃЧйЬАж±ВпЉИFLOPпЉЙжЄЫе∞СдЇЖ 35.8 еАНпЉИ43.7 еАНпЉЙгАВиАМеЬ® ImageNet жХЄжУЪйЫЖпЉМAlexNet жЮґжІЛдЄКпЉМNeST иЃУзЃЧж≥ХеПГжХЄжЄЫе∞СдЇЖ 15.7 еАНпЉМFLOP жЄЫе∞СдЇЖ 4.6 еАНгАВдї•дЄКзµРжЮЬеЭЗйБФжИРдЇЖзЫЃеЙНж•≠еЕІжЬАдљ≥ж∞іеє≥гАВ
иљЙи≤ЉиЗ™пЉЪ е£єиЃА
 jamesmartin
jamesmartin 
зХЩдЄЛдљ†зЪДеЫЮжЗЙ
дї•и®™еЃҐеЉµи≤ЉеЫЮжЗЙ